NineData Batch Database Changes
Today, let's discuss the deployment of databases across multiple regions and the challenges of database changes under the architecture of sharding and splitting databases.
Imagine an international e-commerce company with a large user base in different regions, covering markets in Europe, America, Asia, and many other countries. It goes without saying that the amount of data this company possesses is staggering. Naturally, considering factors such as business access speed, business continuity assurance, inter-departmental collaboration, and business independence, the company has deployed its databases across multiple environments and regions.
Due to the relevance of the business, changes to the database often involve multiple databases and tables distributed across different data sources. To avoid affecting the business, these changes need to be synchronized. For example, consider the following scenarios:
The company decides to carry out a global product category restructuring, requiring a large-scale adjustment to the category structure in the product database. Considering the distribution of databases in various regions around the world, the company needs to synchronize the update of product category information globally to prevent users in different regions from seeing inconsistent product categories.
In order to disperse the read and write pressure of the database and improve performance, the company has horizontally split the business database into multiple databases and tables. At this point, a new field needs to be added to this business database to cope with the needs of new product iterations.
As a DBA, how would you deal with this situation? The author believes there are several ways:
Change each database one by one: The most traditional method, manually changing each database one by one. Not only is it troublesome, but it also takes a long time. When there are many data sources, it is inevitable to miss one or two data sources, leading to inconsistent data categories in some regions, which may cause business errors when writing new data later.
SQL change script: Execute SQL scripts in all data sources, which is more efficient than changing one by one. However, to ensure the completeness of the results, manual queries are needed to verify the change results one by one after the change is completed. And if there is a problem with the SQL script that is not checked out, after the change is executed in all data sources...
The above two methods may be the most used in the above scenarios, but the disadvantages are self-evident. For companies that frequently need to make the same changes to multiple databases, it is simply the worst strategy.
So what is the best strategy?
Good question! Once upon a time, to ensure the continuity of online business, you worked overtime until dawn. At that time, didn't you ever fantasize about being able to complete the execution in all data sources with just one SQL statement? Or, by submitting a single SQL task, the system can automatically execute it at a specified time, eliminating the trouble of working overtime until midnight.
In fact, by using NineData's database and table grouping features in combination with SQL tasks, you can easily achieve these effects.
Simple demonstration of configuration methods
Create a database group and add the databases that need to be changed in batches to a group.
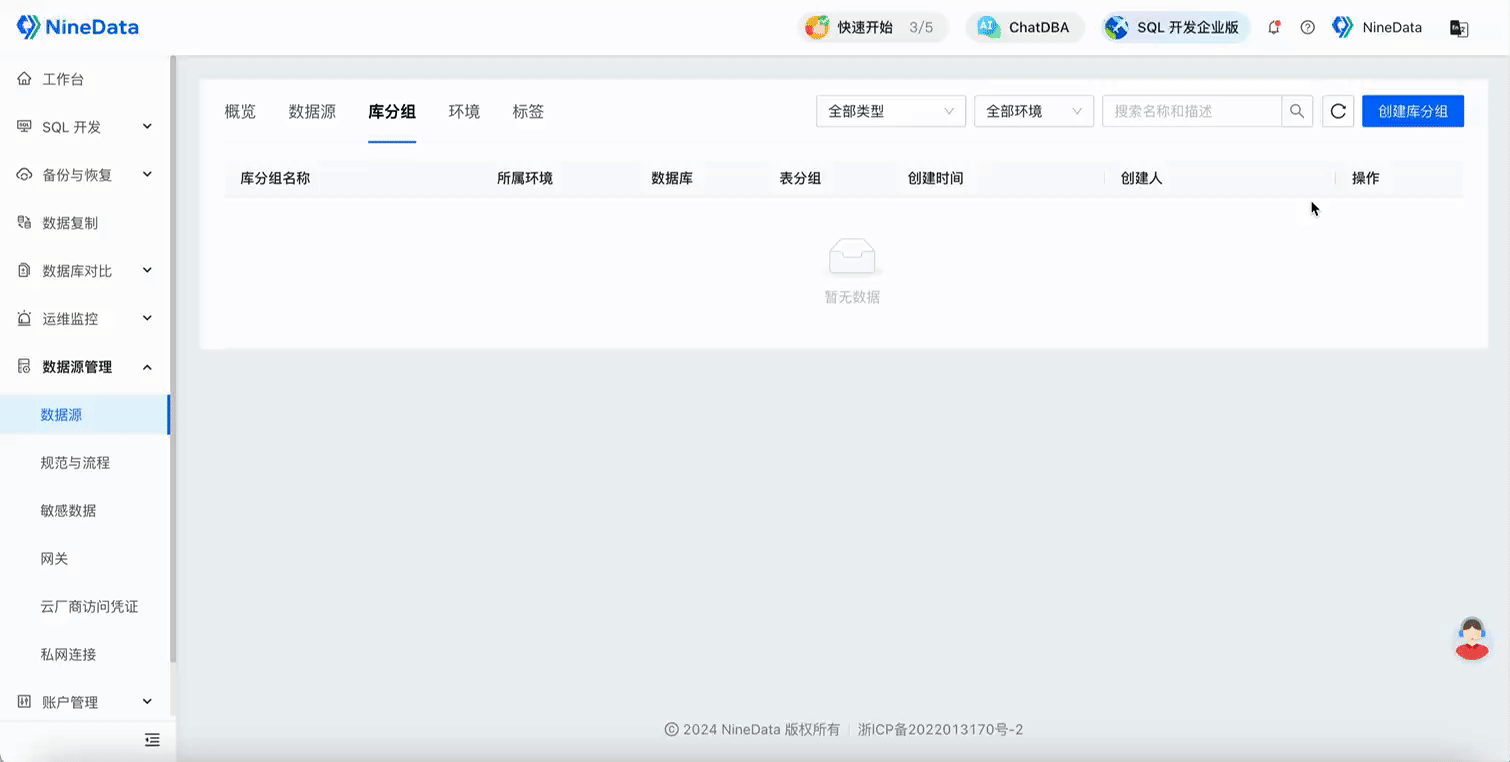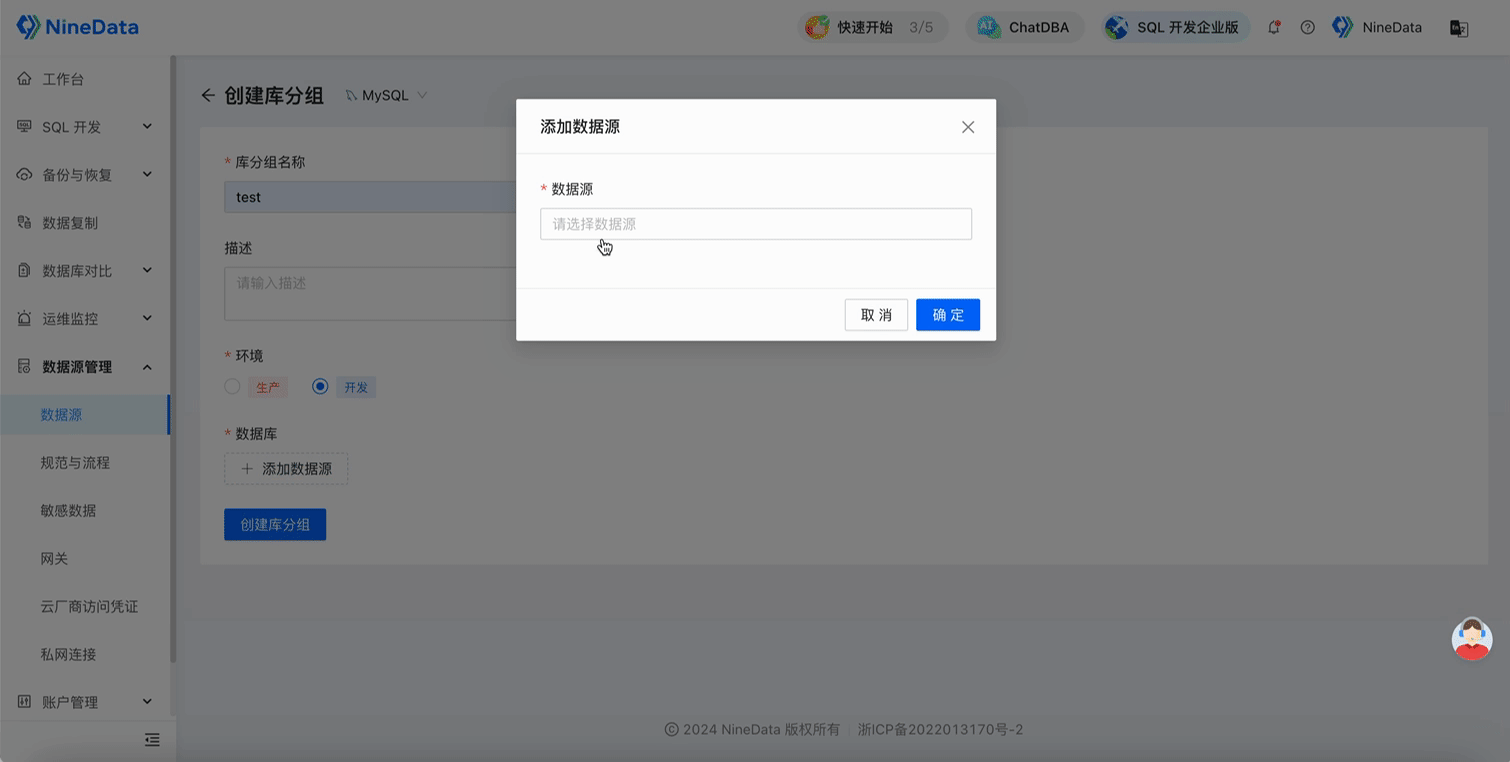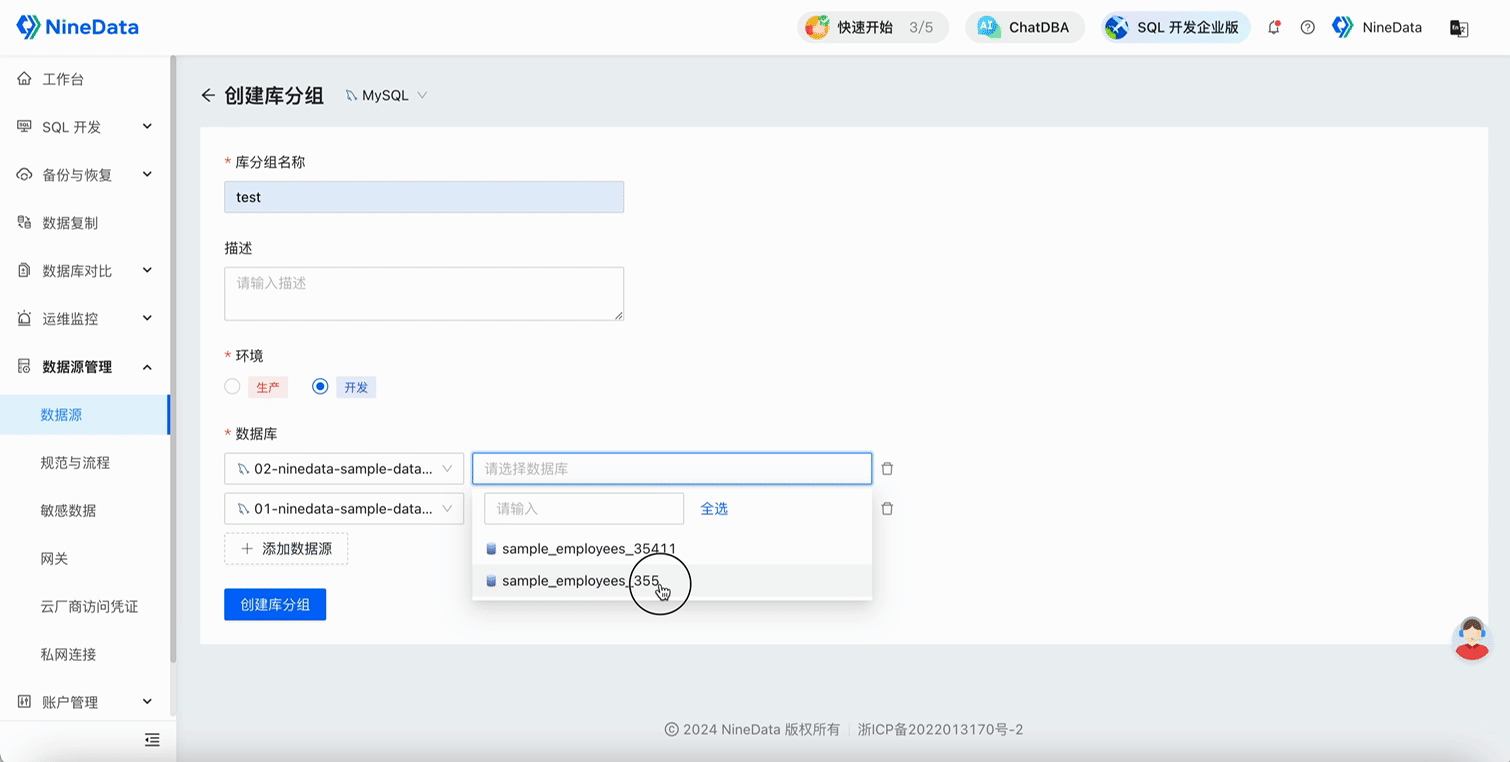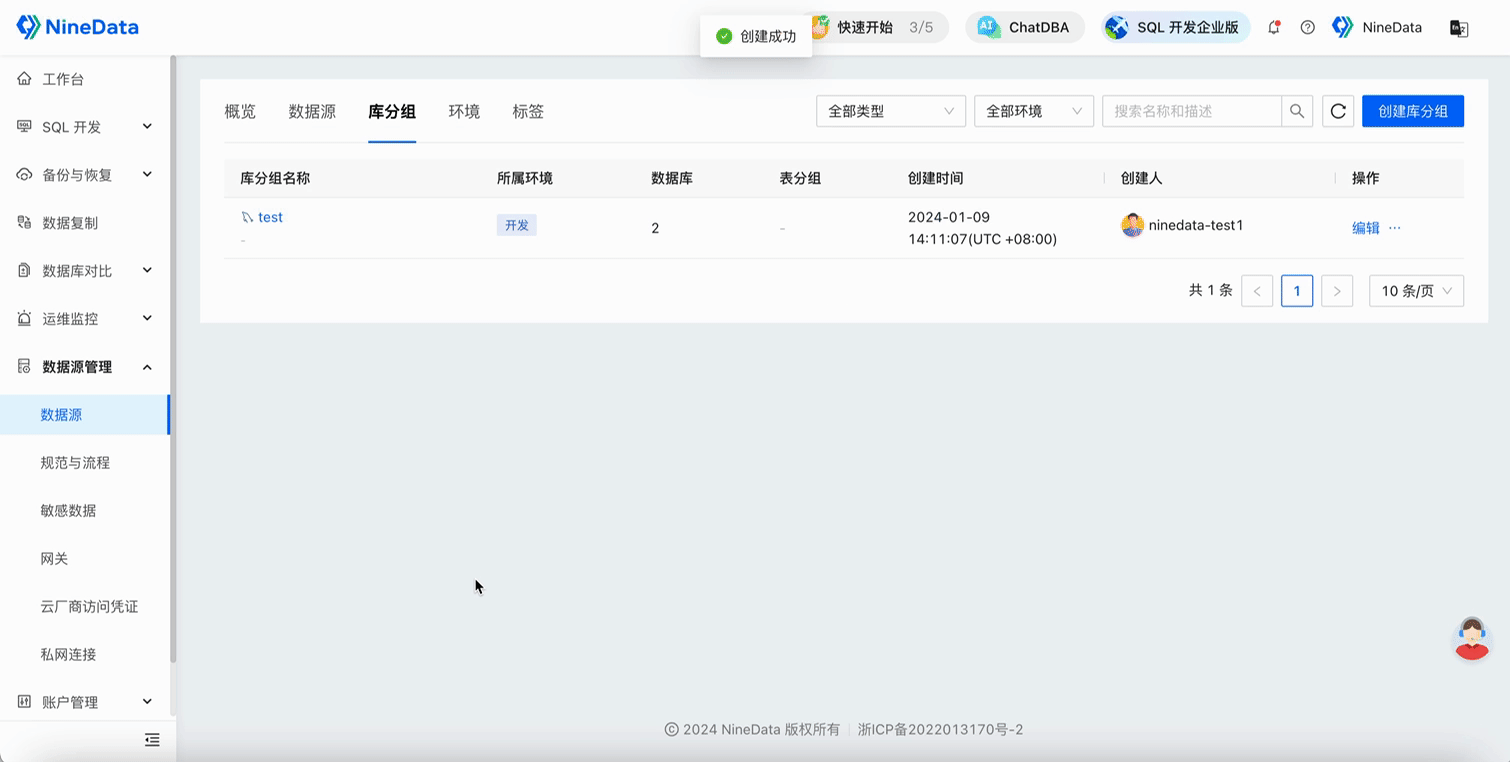
Submit an SQL task, select the database group, execute the DDL statement, and add a new column to the
departmentstable in all databases in the group.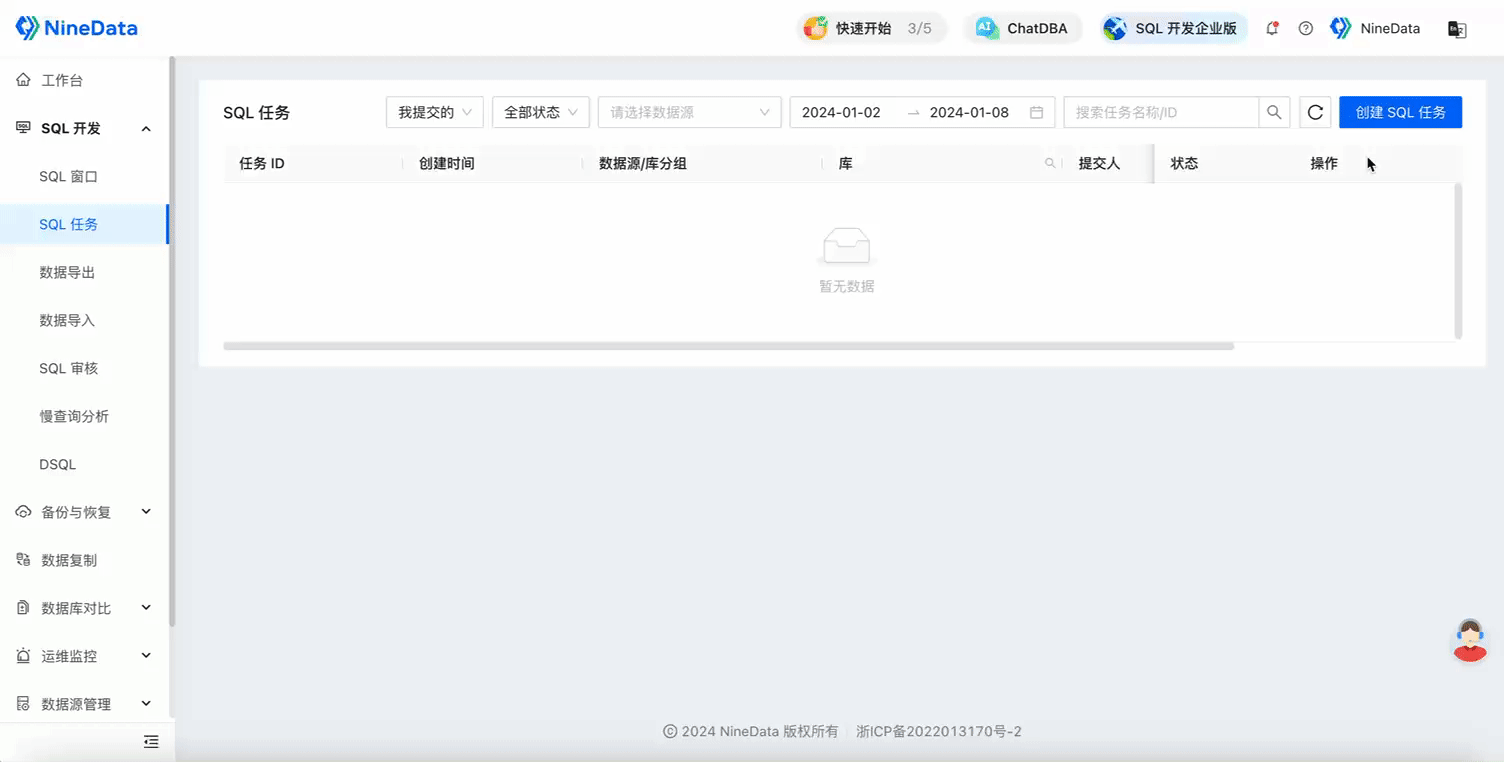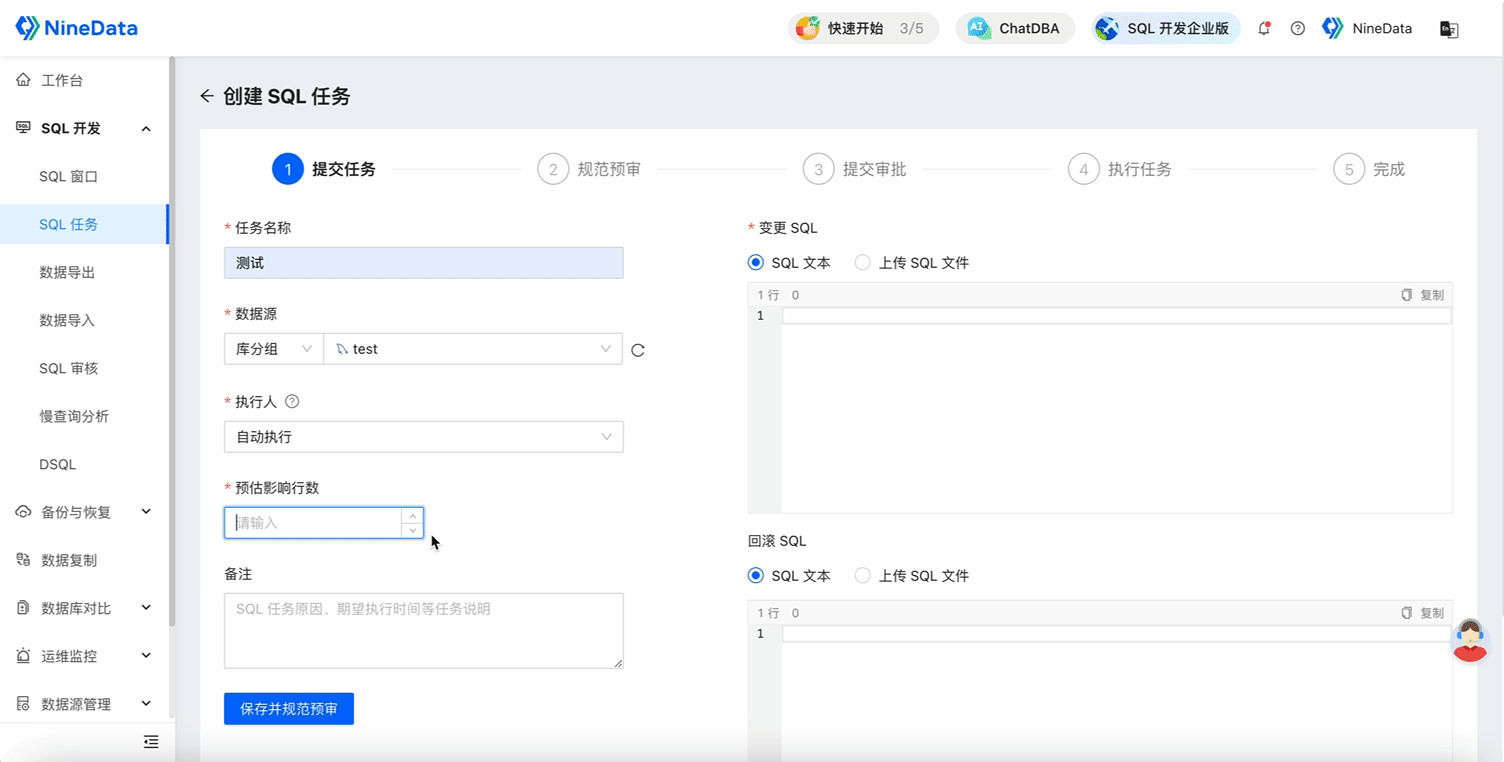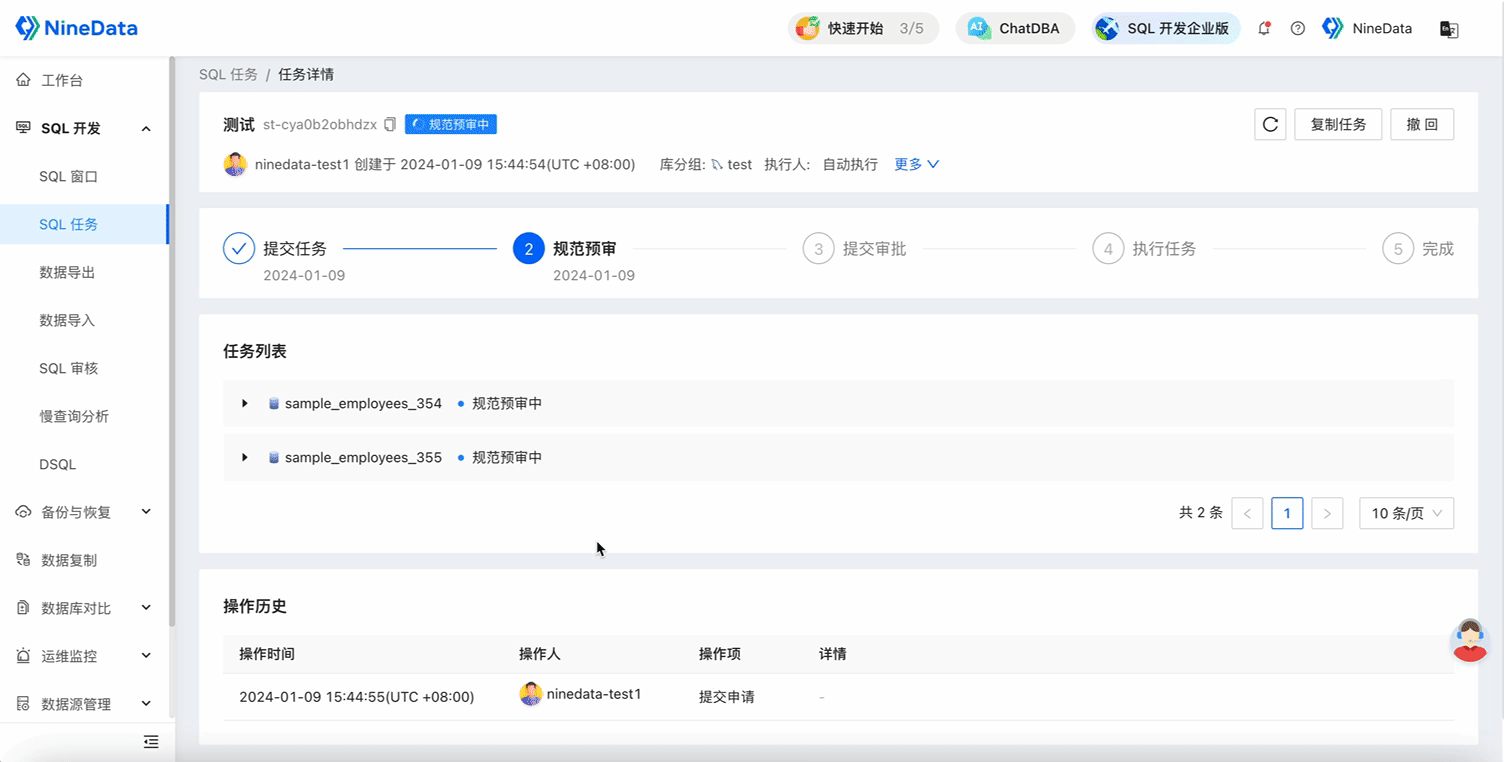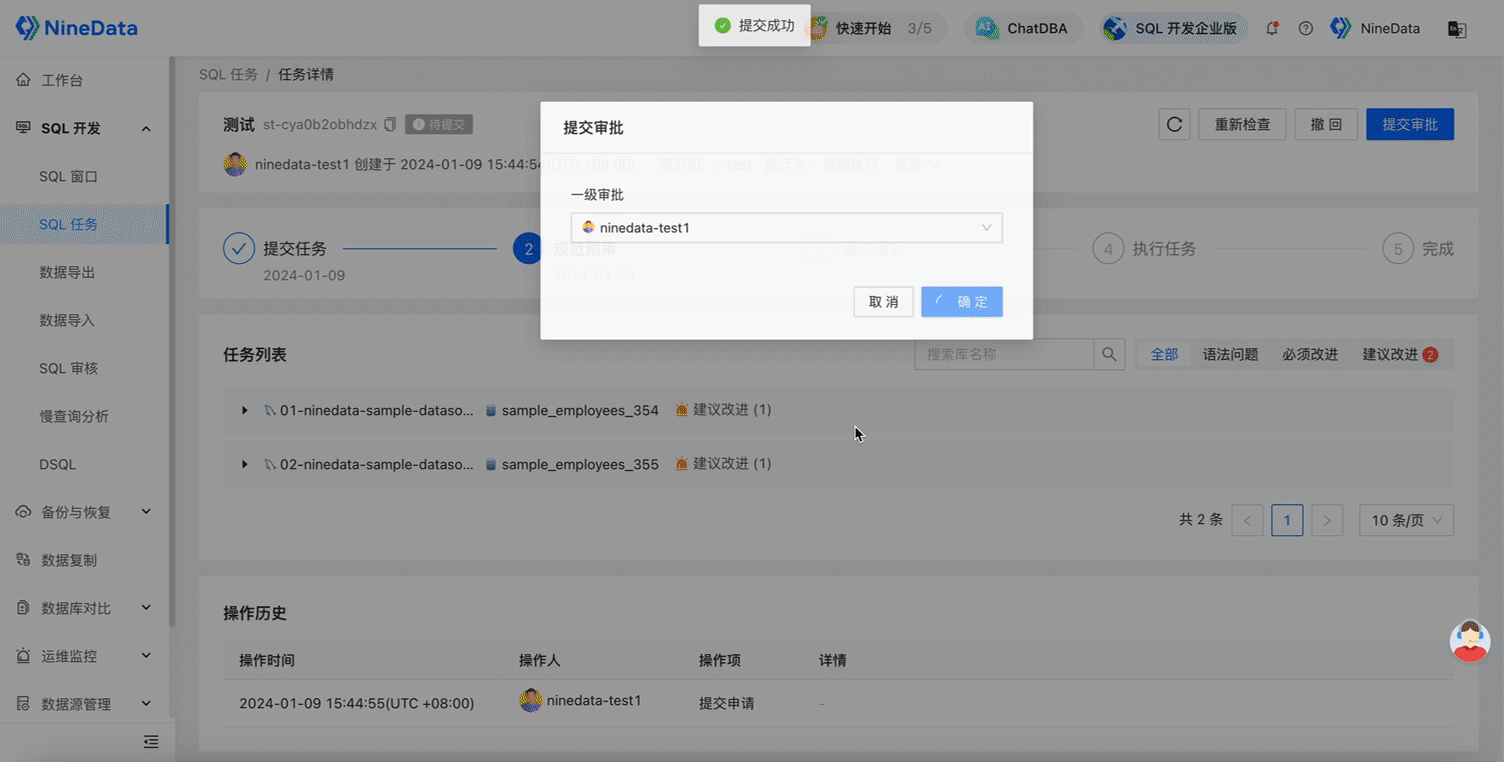
After the SQL task is approved, the change statement will be executed in all databases in the database group, and you can confirm the execution results in each database on the SQL task details page.
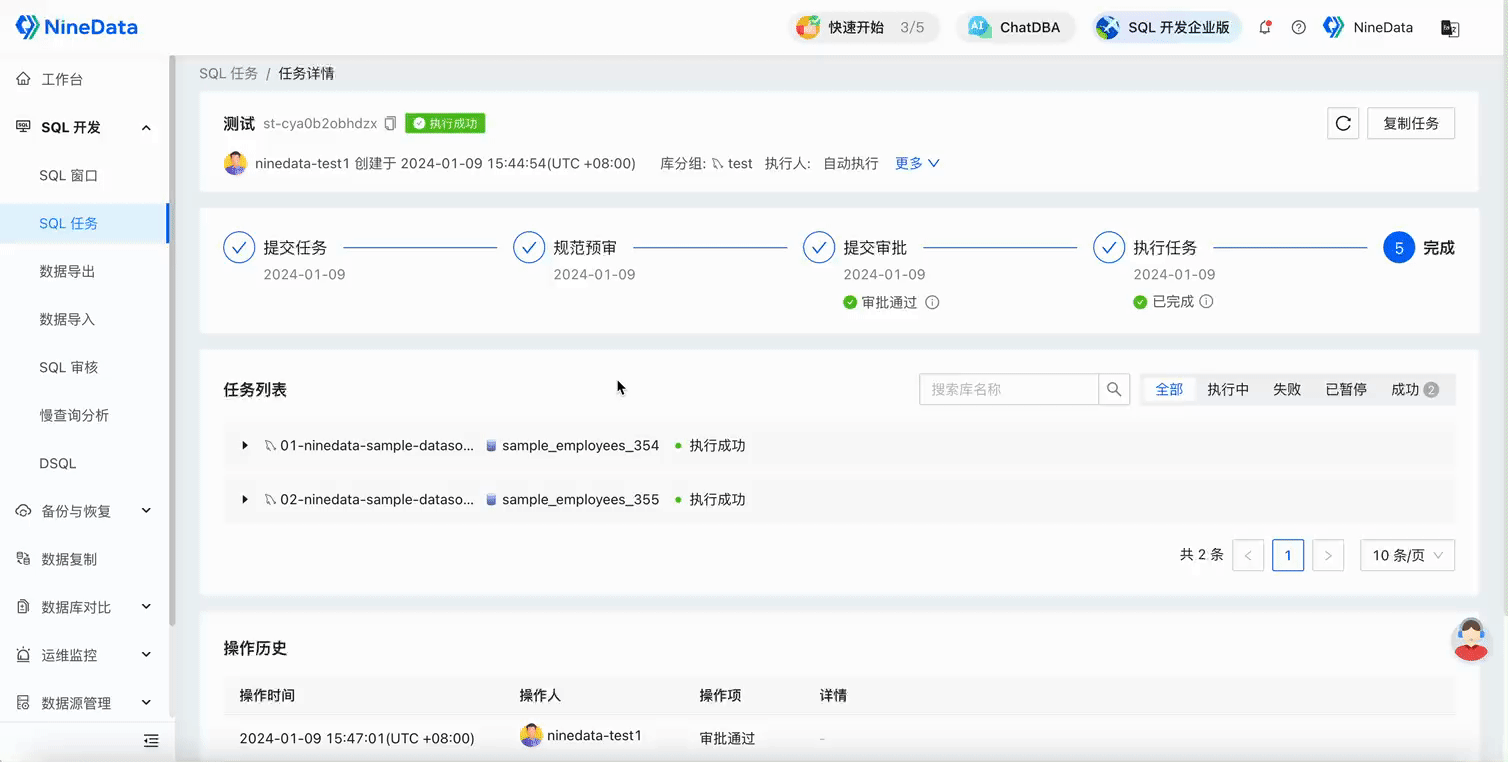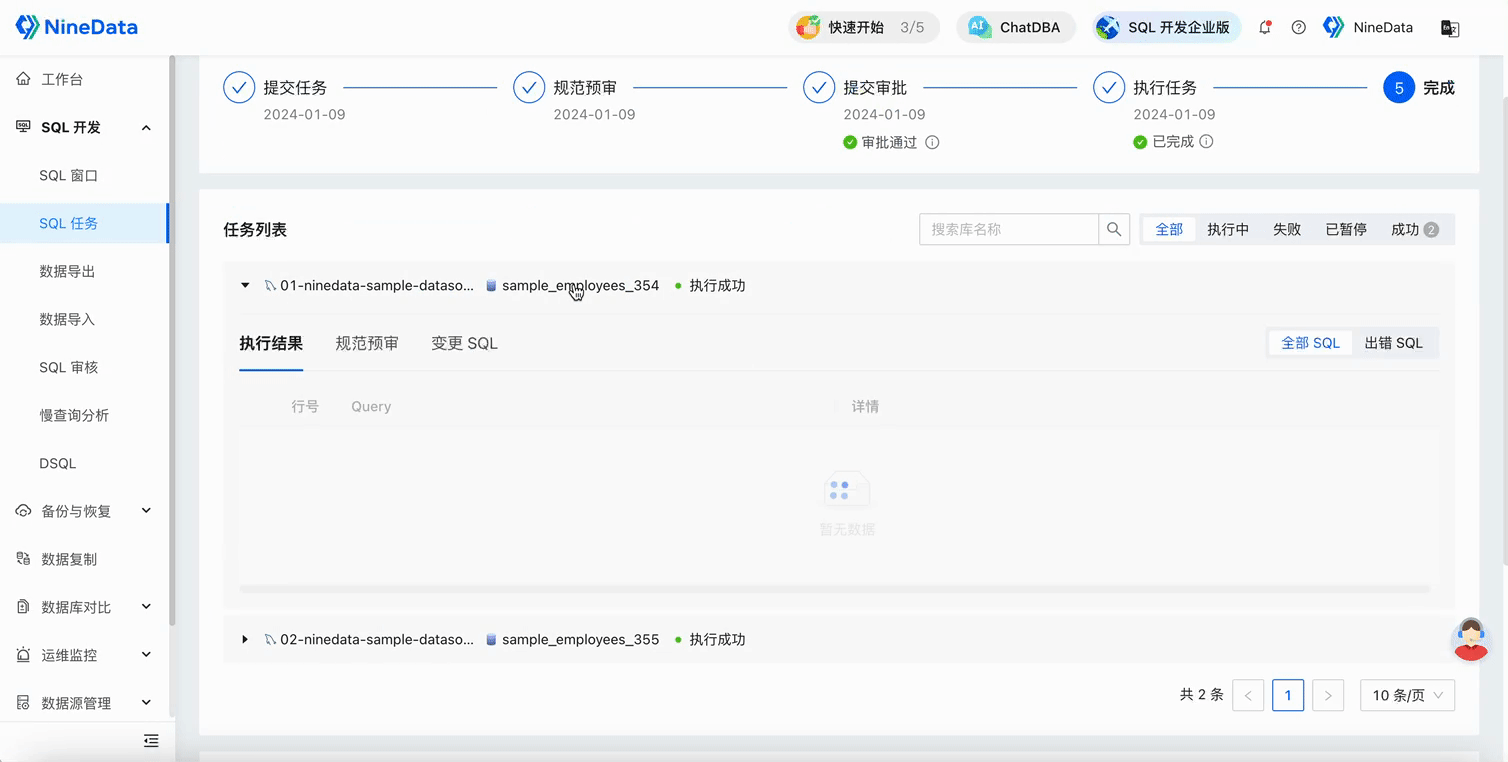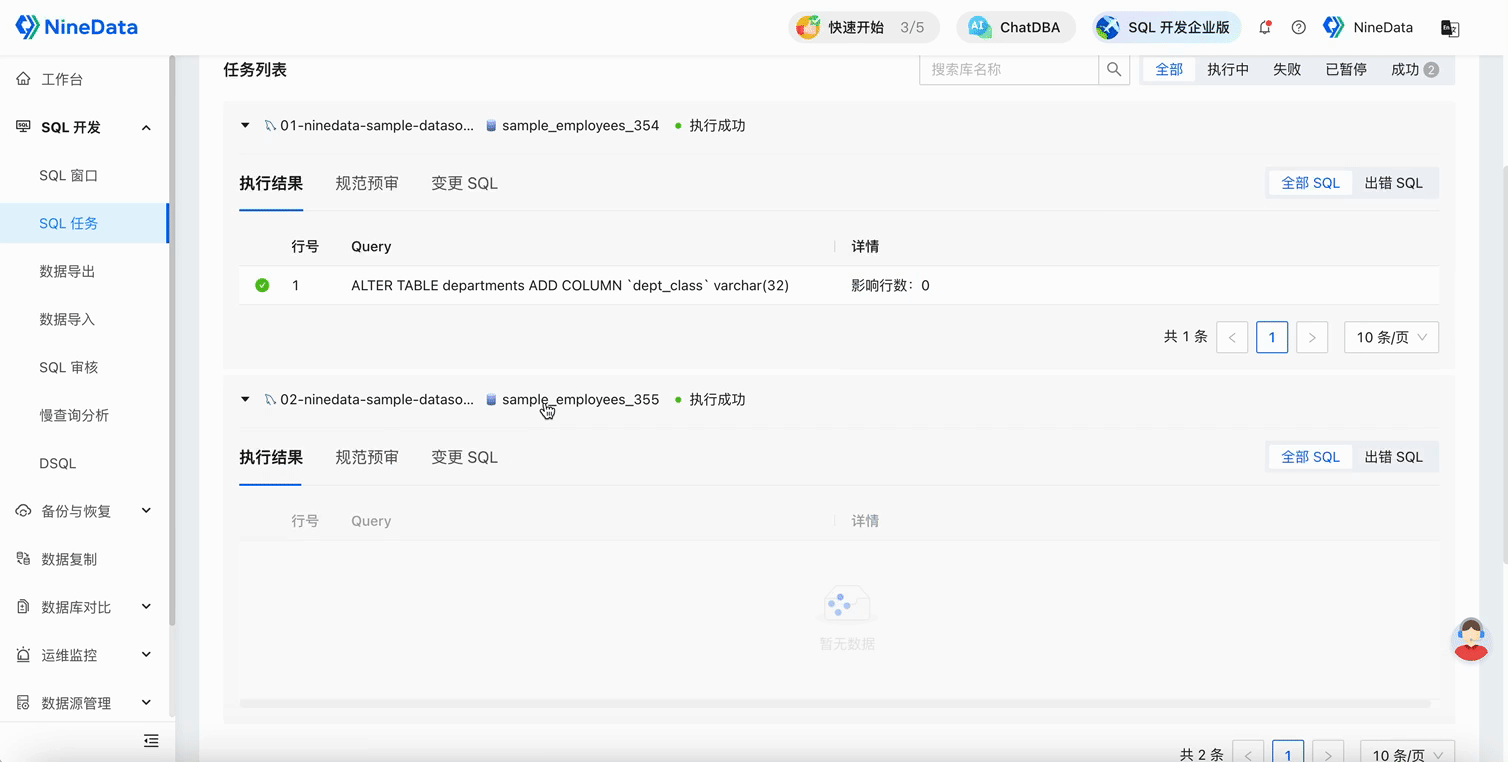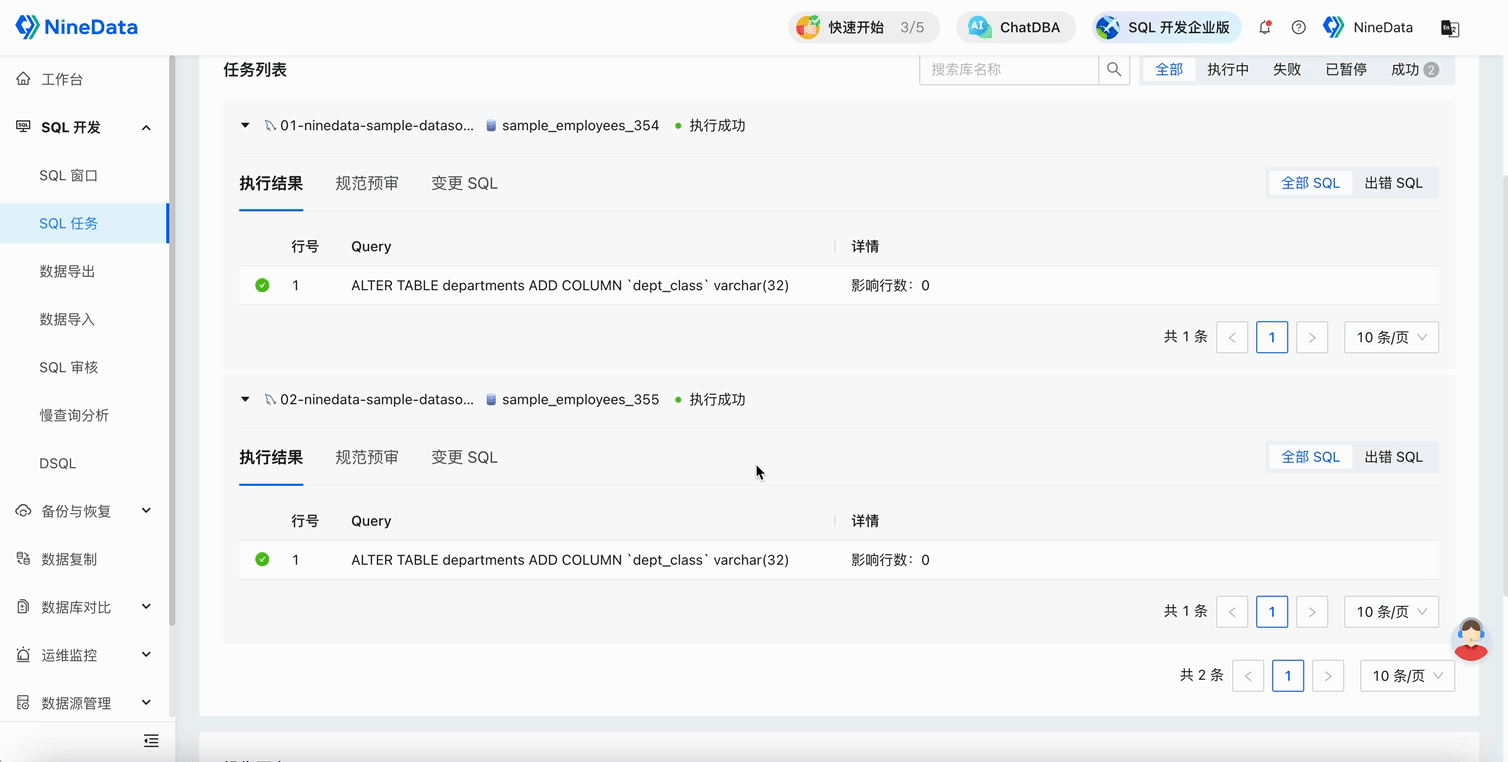
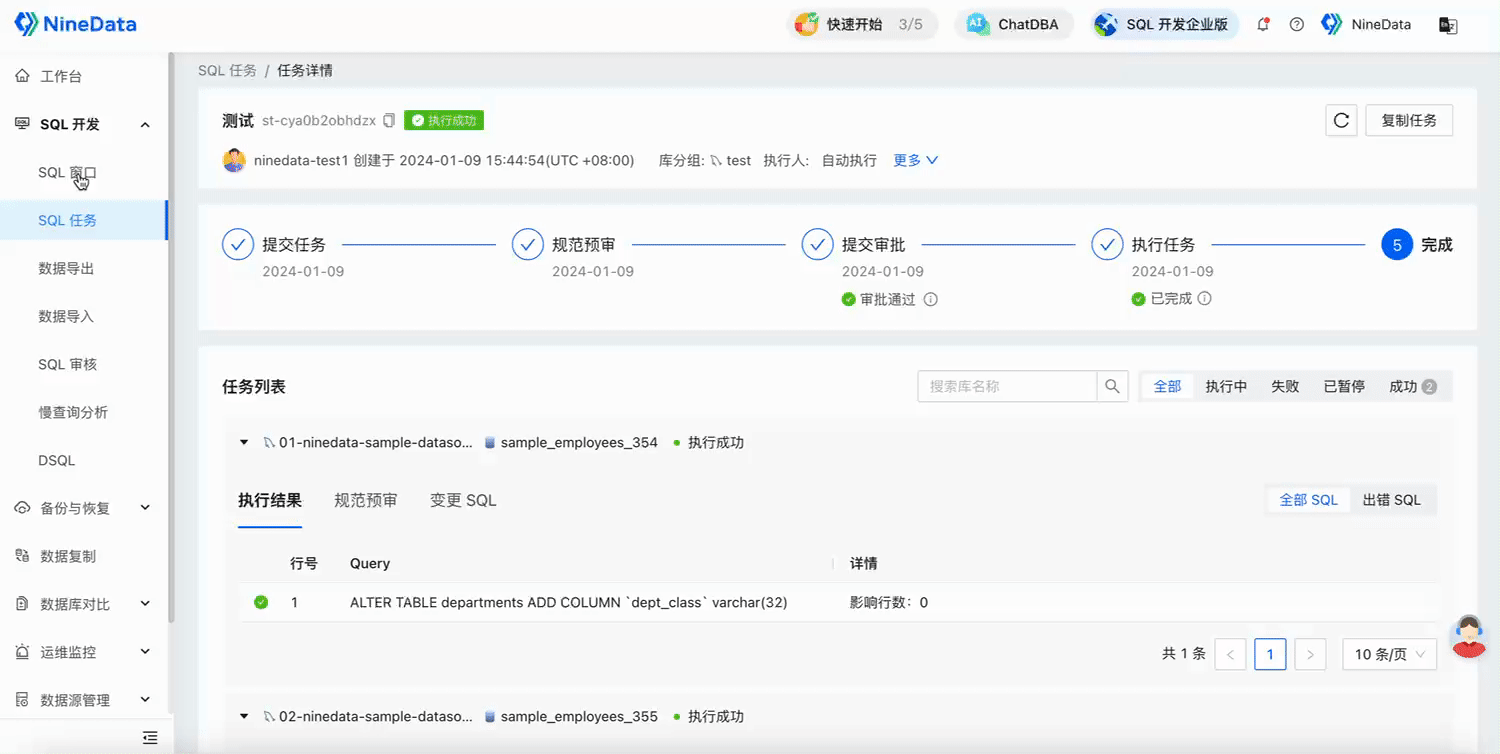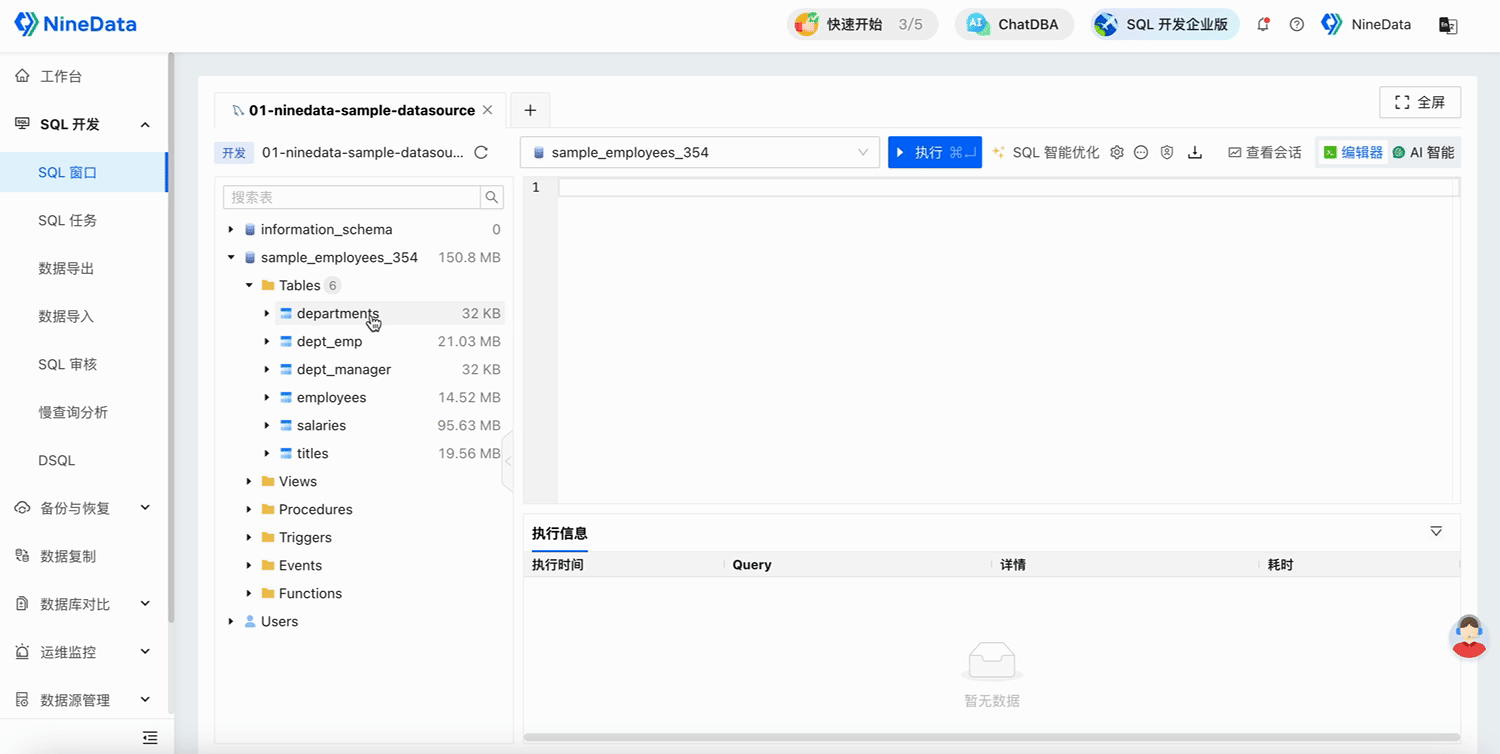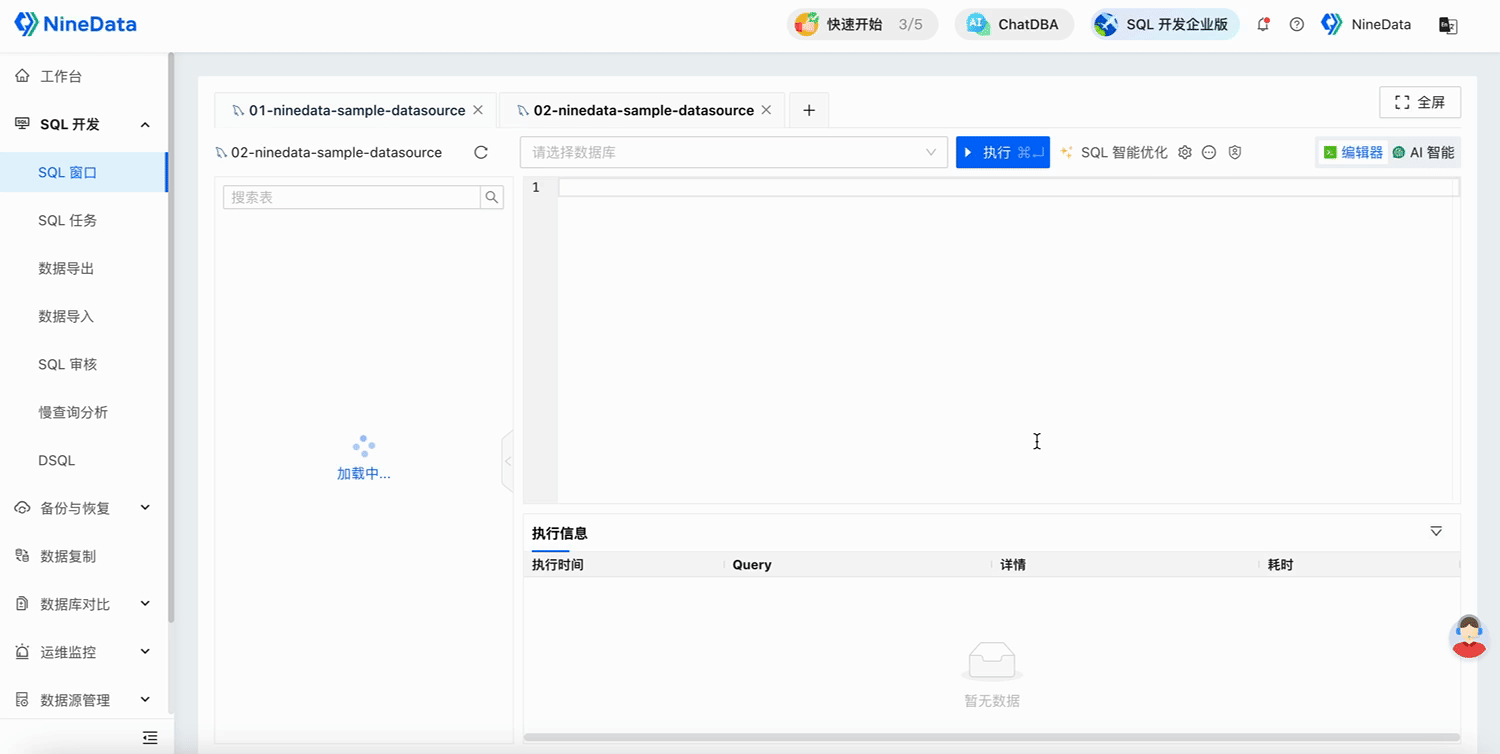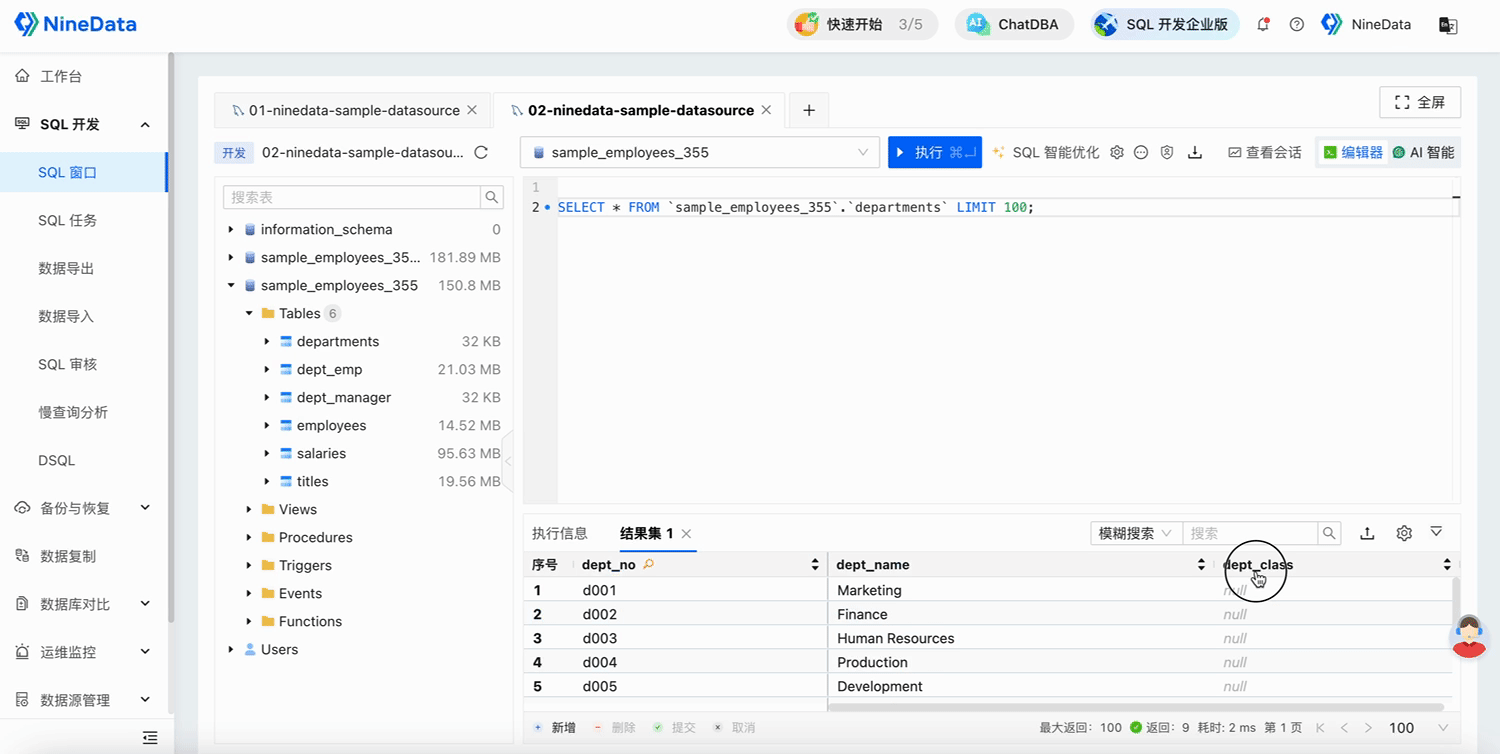
Open the SQL Console to verify the execution results.