Product architecture
This chapter introduces the overall product architecture and core functional components of NineData.
Architecture Description
NineData provides a distributed, highly reliable, multi-tenant architecture on top of cloud native technology with high elasticity and scalability. The product architecture diagram is as follows.
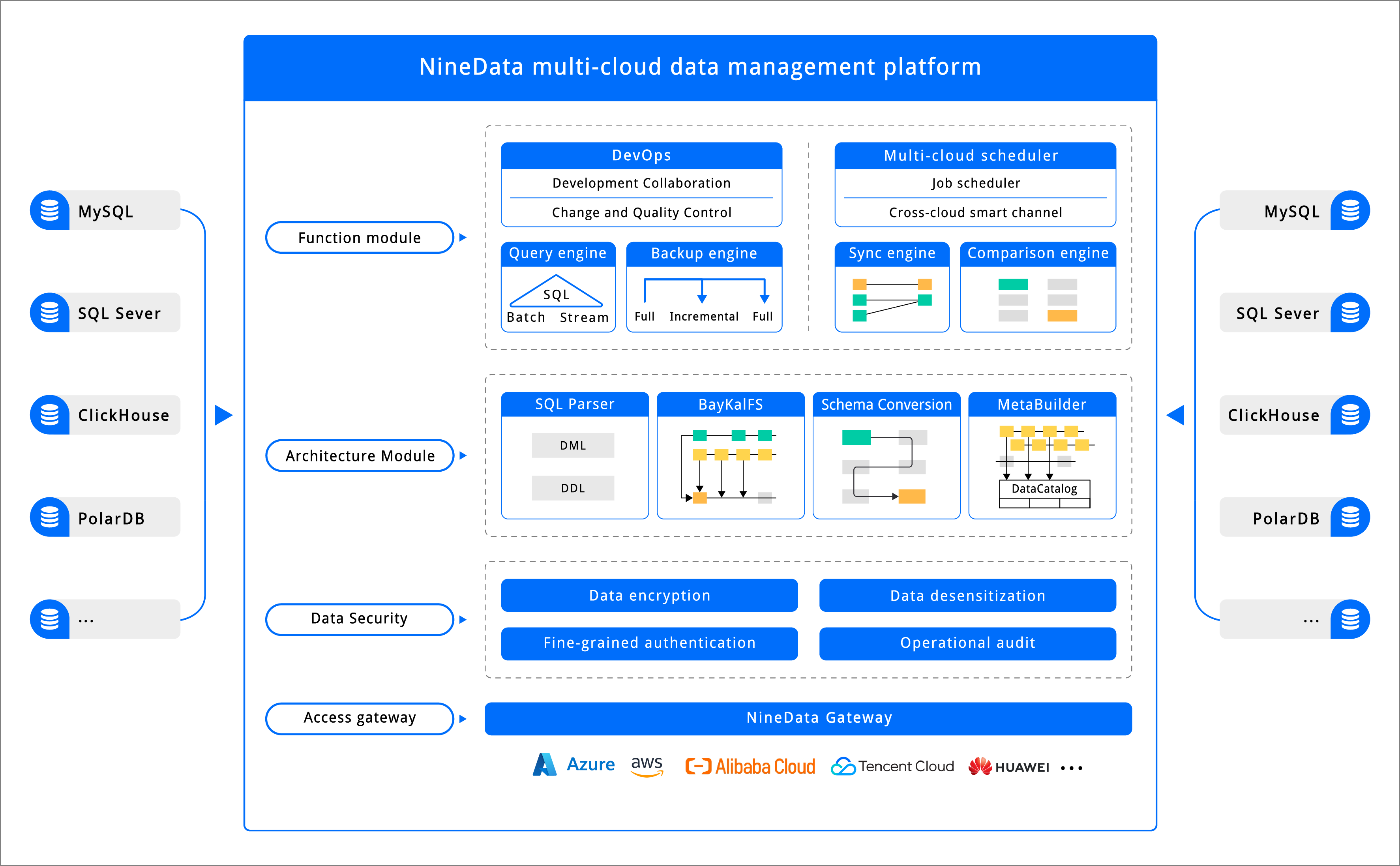
The entire product architecture contains five layers:
- Access layer : User interaction layer, which manages life cycle of tasks, and maintenance of data management. The service is mainly provided in the form of an interactive console.
- Function engine layer : Responsible for specific data management work, including DevOps, query engine, backup engine, synchronization engine, comparison engine and scheduling engine. For details on the capabilities of each engine, see Engine Introduction .
- Core component layer : Public layer components, serving the upper-layer functional engine, providing log parsing, data conversion, and data storage engine capabilities.
- Data security layer : Provides data security protection capabilities covering the entire data life cycle and throughout the data management process. Components include fine-grained permission control, sensitive data management and desensitization, data encryption and security operation auditing.
- Data connection layer : Responsible for providing connection access to multiple data sources for the upper engine.
Functional Components
| Engines and Components | Description |
|---|---|
| DevOps and query engines | DevOps :
|
| Query engine : Receive SQL requests sent by users. | |
| Scheduling engine | Responsible for the overall task and resource scheduling of the platform.
|
| Backup engine | Responsible for backup and recovery tasks, and onitor of task status. |
| Synchronization engine | Responsible for data replication tasks, and automatically schedule related dependent tasks in a pipeline manner according to the replication type configured by the user, and onitor of task status. |
| Comparison engine | Responsible for structure and data comparison tasks between two data sources, and monitor of task status. |
| SQL Parser | SQL parsing module. Responsible for the analysis of SQL statements and logs in the overall platform, and assist the engine to complete tasks such as data reading and data security access. |
| Sensitive data management | Responsible for providing sensitive data metadata and masking functions for the query engine, backup engine, synchronization engine, and comparison engine. Dozens of sensitive data recognition algorithms are built-in, and when enabled, the sensitive fields in the data source are automatically scanned and marked. |