What is Data Replication
The term "Data Replication" can actually be directly associated with the practical funtion it serves. It refers to the process of copying data from one database to another, ensuring consistency and availability across multiple systems.
But data replication is just one piece of the puzzle. Companies often need data migration, data transformation, and data synchronization to seamlessly move and integrate data between systems.
When it comes to data replication, there are several critical challenges that must be addressed...
Ensuring Business Availability:Data Migration has to happen without disrupting business operations. In other words, there’s no room for downtime. But that’s easier said than done. Fully migrating both existing and real-time data? Not so simple. Managing performance fluctuations during migration? Another challenge. And let’s not forget about achieving a smooth application switchover—far from straightforward.
Schema Initialization and Change Synchronization:When dealing with a massive number of tables, things get even trickier. If DDL changes occur on the source database during migration, ensuring a stable and efficient migration process becomes a major challenge.
Maintaining Data Quality During Migration:With large-scale data transfers, keeping data consistent is no small feat. And what if something goes wrong during the migration switchover? Implementing an effective rollback to maintain business availability is a problem that must be solved.
Minimizing Loss in Case of Migration Failure:Migrating between heterogeneous databases is especially complex because the source and target systems behave differently in terms of functionality and performance. If a migration fails, how do you ensure business continuity and minimize the impact? That’s a critical concern that needs serious attention.
If you’re working with data in any capacity, you’re bound to run into these challenges sooner or later. And when you do, NineData Data Replication will be your go-to solution, helping you tackle every single one of them with ease.
NineData All-in-One Solution
NineData is your all-in-one solution for handling data replication across a wide range of homogeneous and heterogeneous data sources, making it easy to meet diverse enterprise needs.
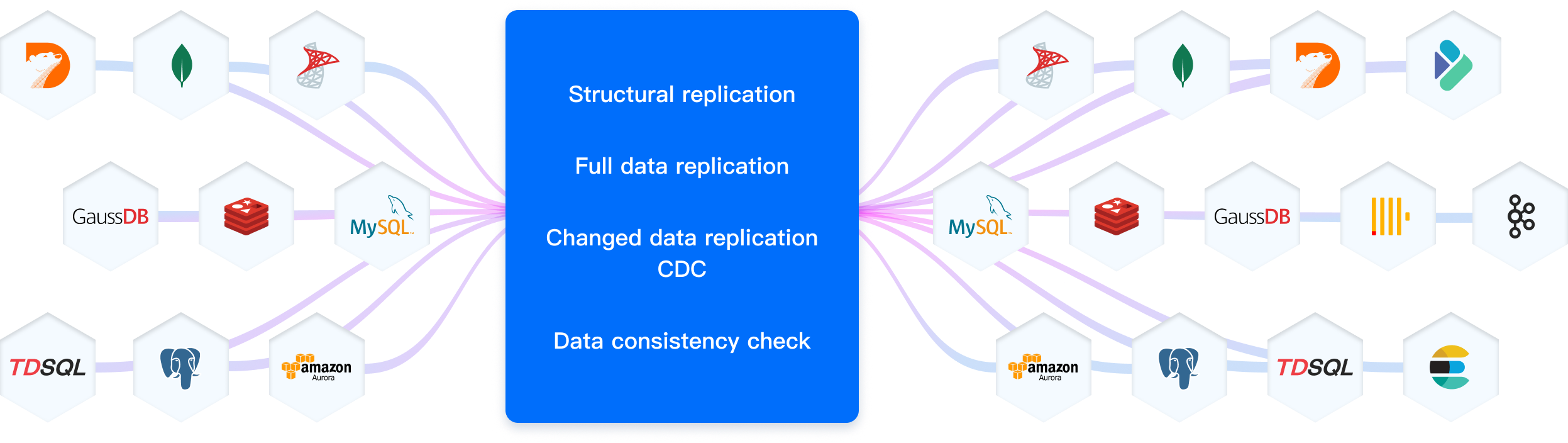
Works Across Multiple Environments: Whether your data is on-premises in an IDC, hosted in the cloud, or managed by a cloud service, NineData has you covered.
Supports One-Way and Bi-Directional Sync: From smart schema initialization to full data replication and real-time change data capture (CDC), NineData enables flexible replication architectures, including both one-way and bi-directional synchronization.
Secure and Stable: With built-in observability and intervention capabilities, NineData ensures your replication tasks stay reliable and stable at all times
Real-time replication for mainstream databases
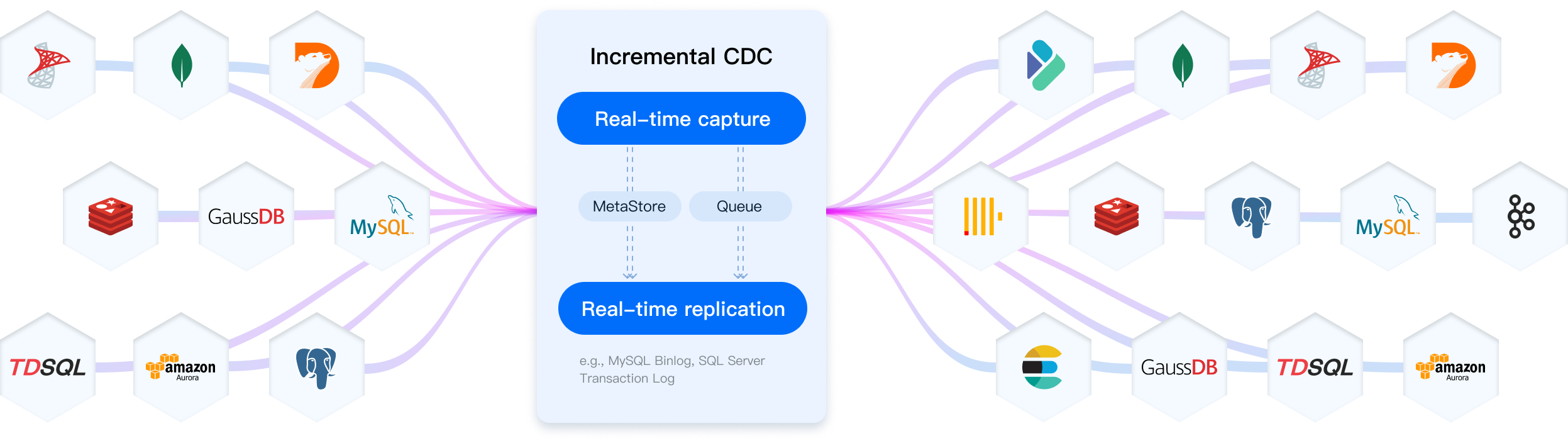
- Log-Based Change Data Capture (CDC): NineData makes real-time data replication effortless. It uses log-based Change Data Capture (CDC) to monitor and capture database changes instantly, ensuring your data stays up to date with minimal system impact.
- Seamless Cross-Platform Sync: No matter where your data lives, whether in the same type of database or across completely different systems. NineData ensures seamless synchronization across both homogeneous and heterogeneous data sources.
- Optimized Performance: Performance is a top priority. NineData delivers superior replication speed and efficiency compared to open-source solutions, reducing latency and maximizing throughput for even the most demanding workloads.
Easy to Use
fully automated and ready to go in just one minute!
- Quick and Simple Setup: Configure and start your replication tasks in under a minute, no hassle, no complex steps.
- Real-Time Monitoring: Keep an eye on everything with comprehensive metrics tracking.
- Smart Anomaly Detection & Auto-Fix: If something goes wrong, built-in mechanisms catch issues early and help you step in when needed.
Real-World Impact: How NineData Transforms Data Management
Our customers rely on NineData to streamline data replication, data migration, data transformation, and data synchronization across their enterprises. Here’s how some of our partners have leveraged NineData to solve complex data challenges:
Volvo: Ensuring Real-Time Data Consistency

Volvo needed a robust solution for real-time data replication between its on-premises databases and cloud infrastructure. With NineData’s log-based Change Data Capture (CDC), they achieved seamless data synchronization, ensuring consistent and up-to-date information across global operations.
Minimax: Optimizing Data Migration for Cloud Adoption

As part of a major cloud migration project, Minimax required an efficient way to move large volumes of data while maintaining business continuity. NineData’s high-speed data migration capabilities enabled a smooth transition with zero downtime, ensuring full operational stability.
ECMS Express: Overcoming Cross-Cloud and Long-Distance Data Replication Challenges

ECMS Express faced a complex data replication challenge—its databases were distributed across multiple cloud providers, making cross-cloud data synchronization difficult. Additionally, long-distance replication introduced performance bottlenecks due to network limitations.
With NineData’s intelligent cross-cloud replication and network optimization capabilities, ECMS Express successfully established a seamless, high-performance data synchronization framework. This ensured real-time data consistency across global operations, improving logistics tracking accuracy and operational efficiency.
Hong Kong Hospital Authority: Zero-Downtime Database Migration from Sybase to PostgreSQL

The Hong Kong Hospital Authority needed to replace its legacy Sybase database with PostgreSQL, but with hospitals running 24/7, downtime was not an option. With NineData’s real-time data replication and zero-downtime migration capabilities, they seamlessly transitioned to PostgreSQL without disrupting critical hospital operations. The result? A modern, high-performance database infrastructure with uninterrupted patient services.
From automotive and logistics to manufacturing, finance, and healthcare, NineData continues to drive innovation in data management, empowering enterprises to unlock the full potential of their data.