How to Use NineData to Regularly Clean Up Historical Data in Databases?
After a considerable period of operation, corporate databases tend to accumulate historical data, which includes outdated, duplicate, erroneous, and missing (empty fields) data, occupying valuable database space for an extended period. With the upsurge of cloud computing, the vast majority of companies have migrated their business data and services to the cloud. This transformation brings greater flexibility to companies but also poses challenges in managing and maintaining historical data.
Take the author's company database as an example; the space usage threshold for database alerts is typically set at 85%. When this threshold is reached, an alert is triggered, and then it is necessary to check if there is any historical data that can be cleaned up. If not, an application for database disk expansion is required.
This process of the company is actually the database space management process of many companies. As the business develops and storage space becomes critical, the frequency of alerts will inevitably become more frequent. Moreover, for cost considerations, it is not feasible to continuously purchase storage space indefinitely. Therefore, checking and cleaning up historical data has become an effective means of increasing database storage space, while also avoiding a series of database performance issues caused by the accumulation of historical data.
Effective Solutions for Cleaning Historical Data
For business data itself, it may not be valid for a long time. We need to clean out the expired historical data from the business database, save it in another database instance for long-term storage, and delete this part of the data in the business database to free up space for new business data.
The overall plan is in place, but how to execute it? If it is merely checked and cleaned manually, it will take a lot of time and may lead to some mistakes, resulting in the deletion of important data. Most importantly, cleaning up historical data is a periodic task, and we need to automate this task to be executed at regular intervals, allowing storage space to be continuously freed up.
It seems complex, but in fact, it is not simple at all. However, if you use NineData's data archiving feature, it can be easily accomplished.
Simple Demonstration of Configuration Method
First, we need to ensure that the table to be archived has a time field. This is very important, as the system needs to determine whether the data needs to be archived based on this time field. It is recommended to add the following two fields to the design of each table, which is beneficial for data archiving and data correction scenarios, and improves the maintainability of the table.
`created_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Creation Time',
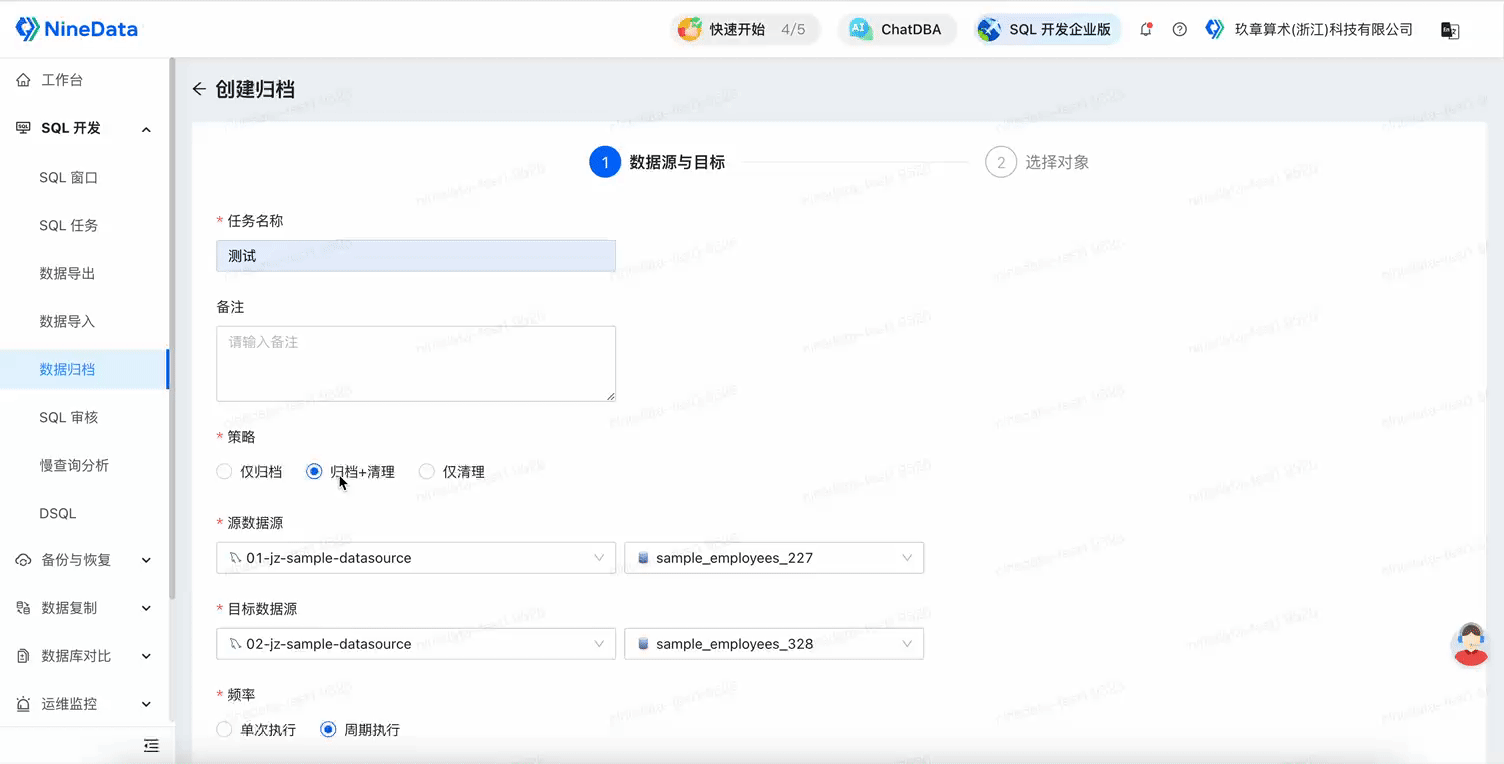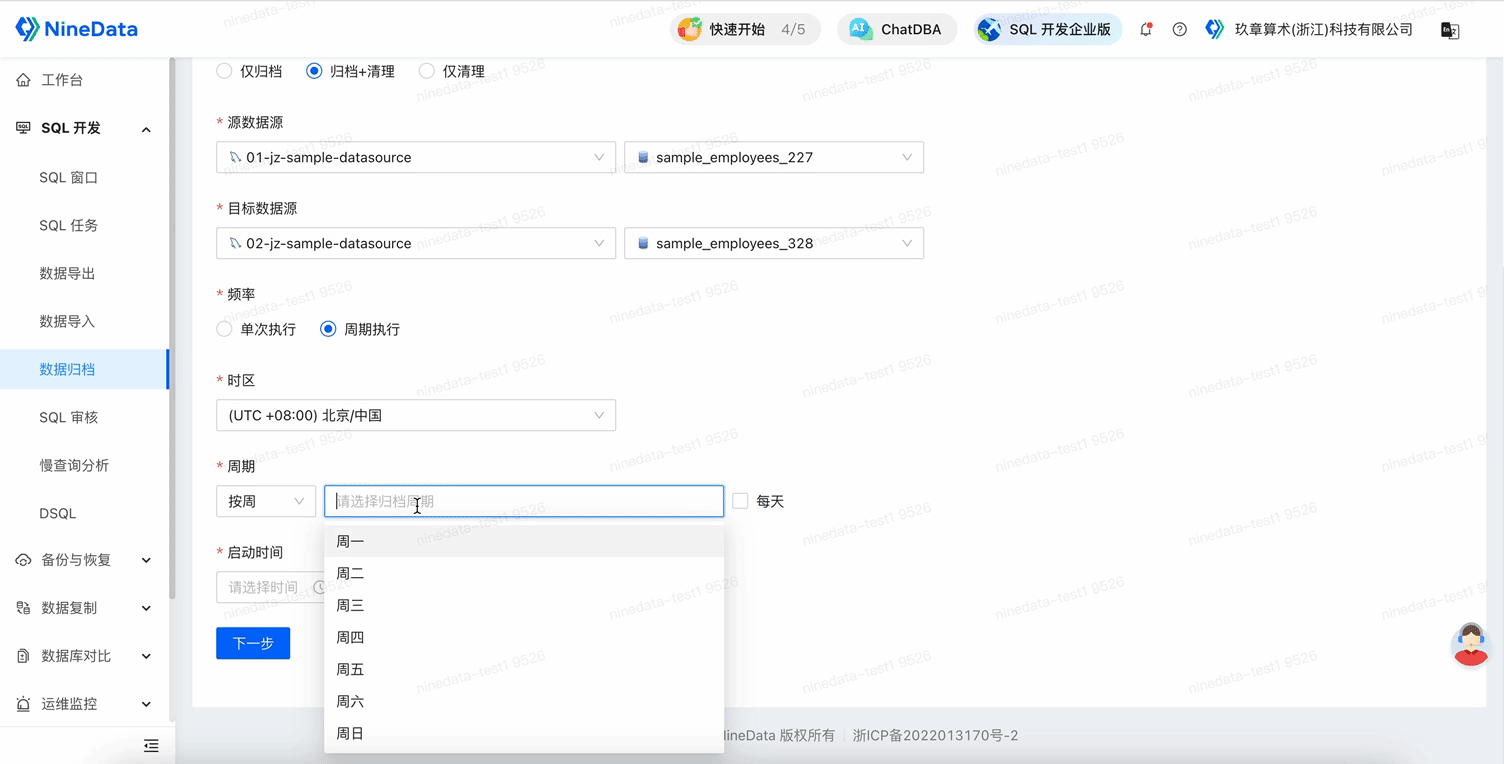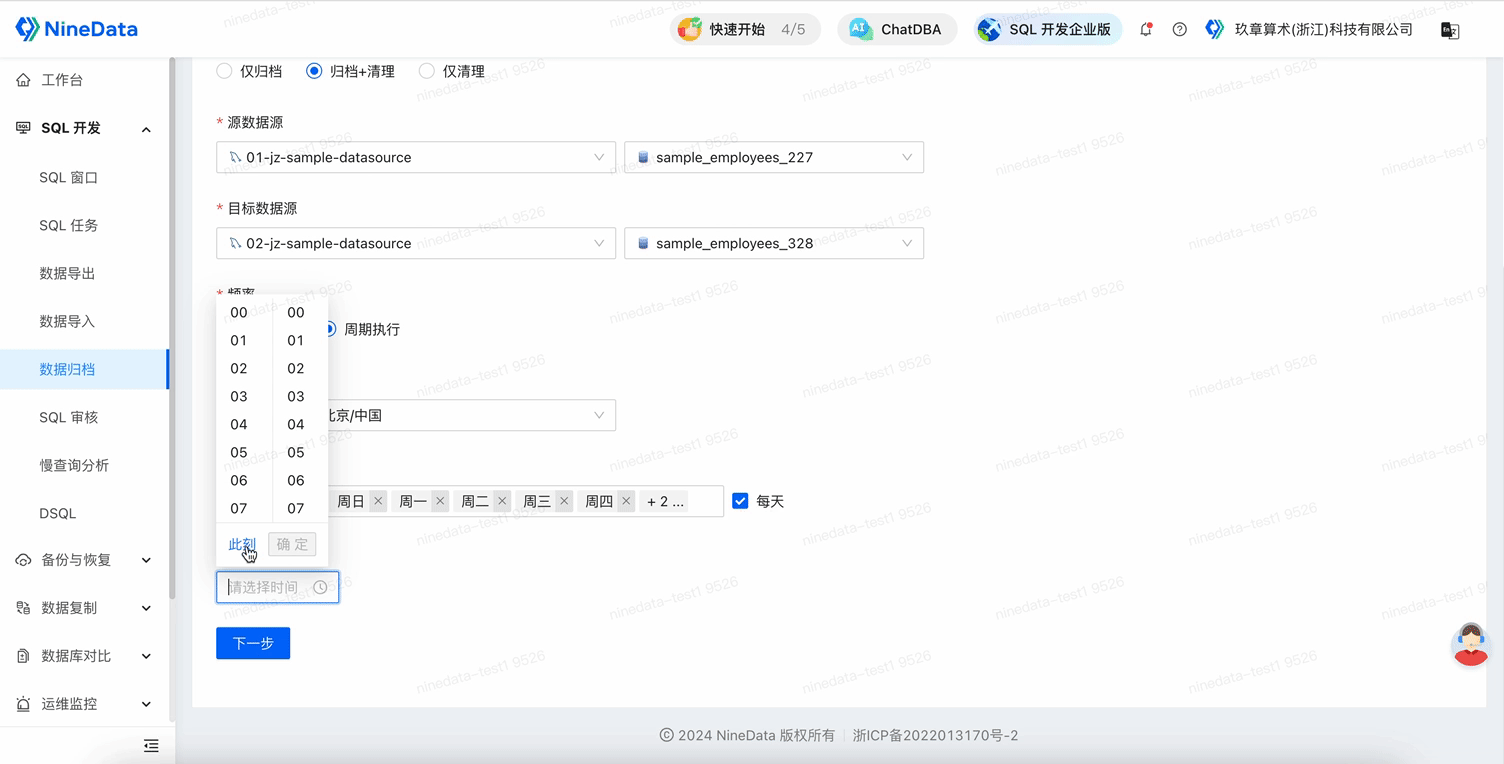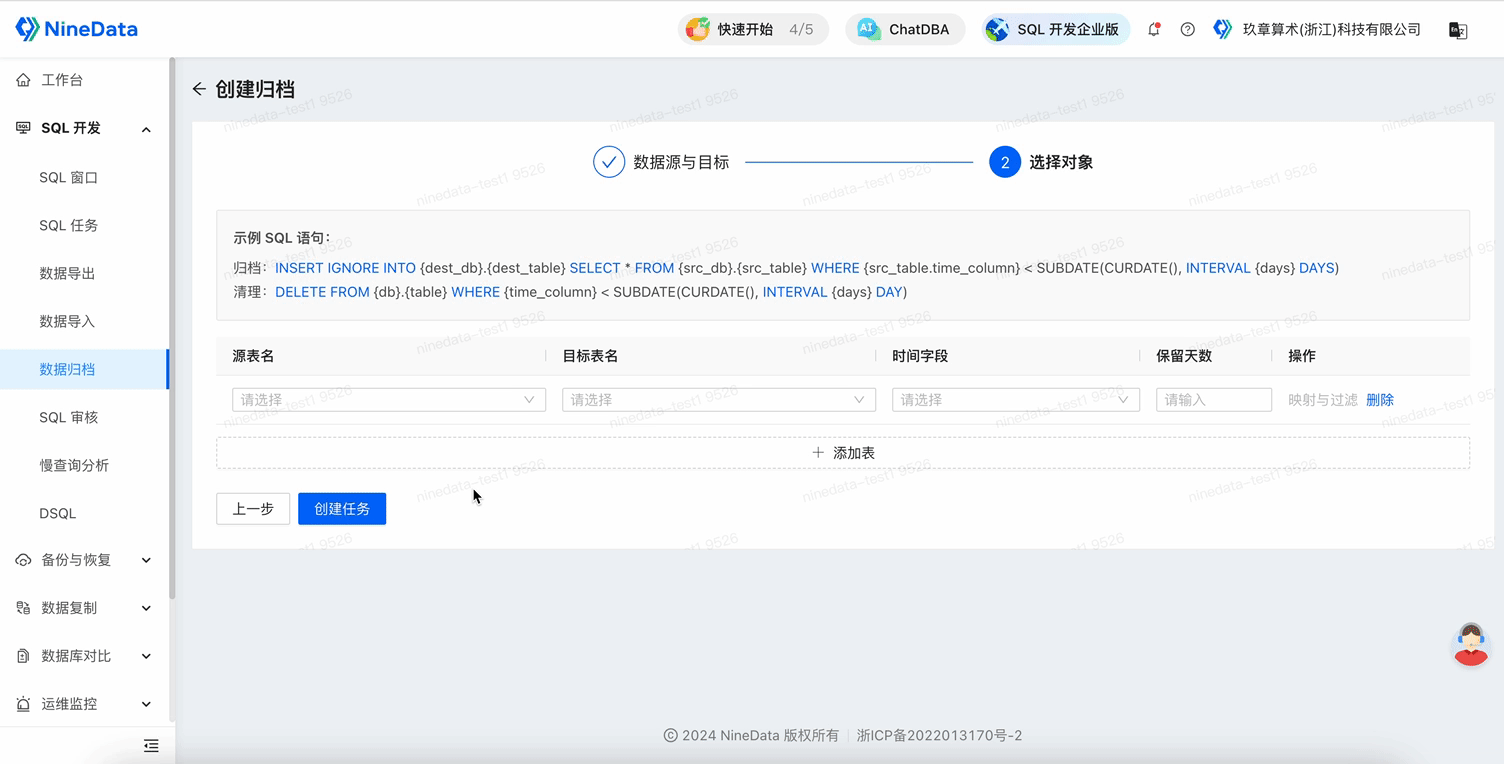
`updated_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Update Time'Create an archiving task, select Archiving + Cleaning as the archiving strategy, select the source and target data sources (for long-term storage), Frequency select Periodic Execution, and choose the cycle and start time for the automatic execution of the task.
Select the table name to be archived and the target table name, the target table name is the table where the archived data is stored; Time Field is the basis for judging the archived data, such as the order generation time, etc.; Retention Days is the number of days of data to be archived, if you need to archive data from a year ago, enter 365 here.
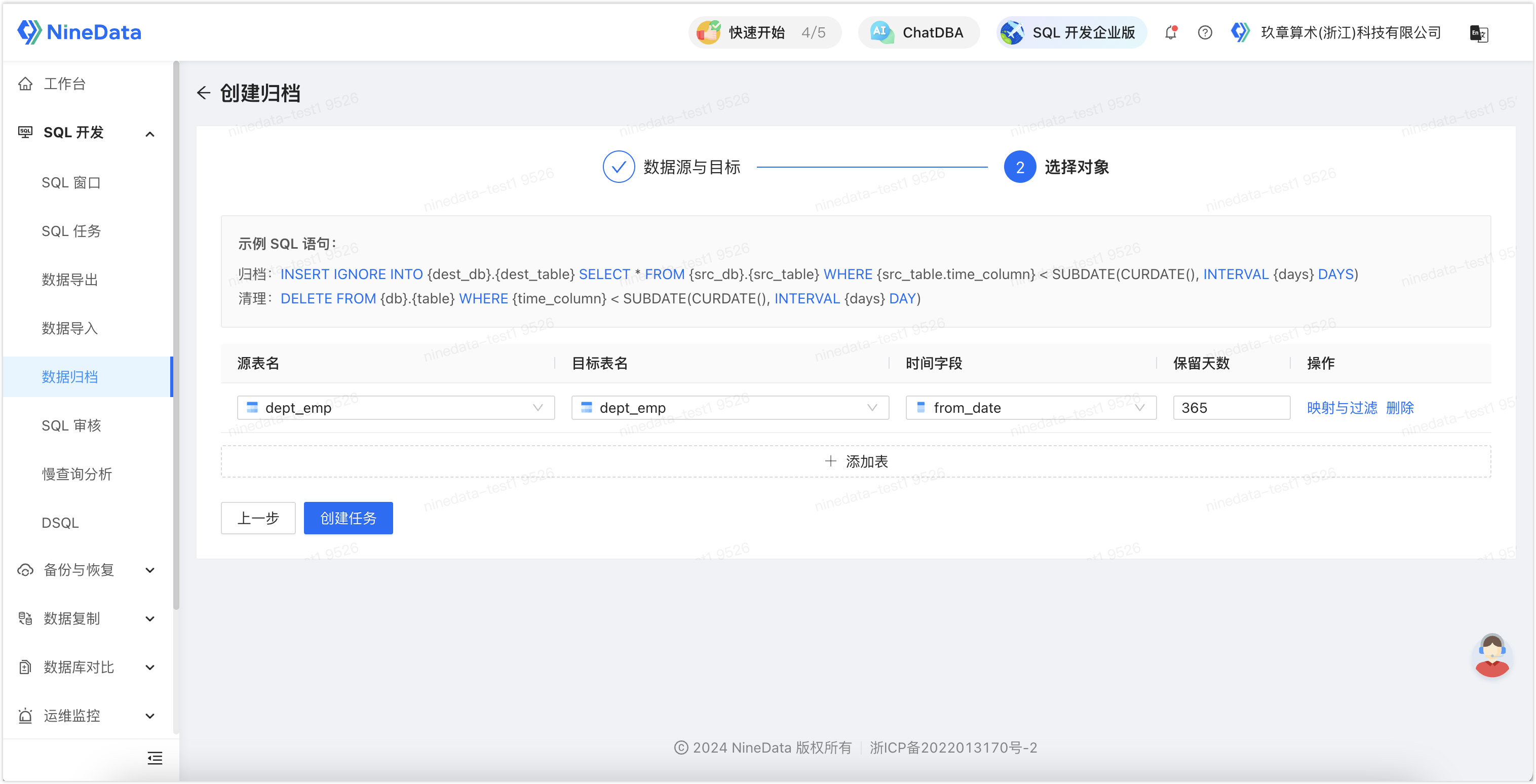
This feature also supports setting filtering conditions, and only data that meets the filtering conditions will be archived. Click Mapping and Filtering, and enter the operation expression in Data Filtering Conditions. In the scenario of the figure below, only rows with
dept_no = 0will be archived.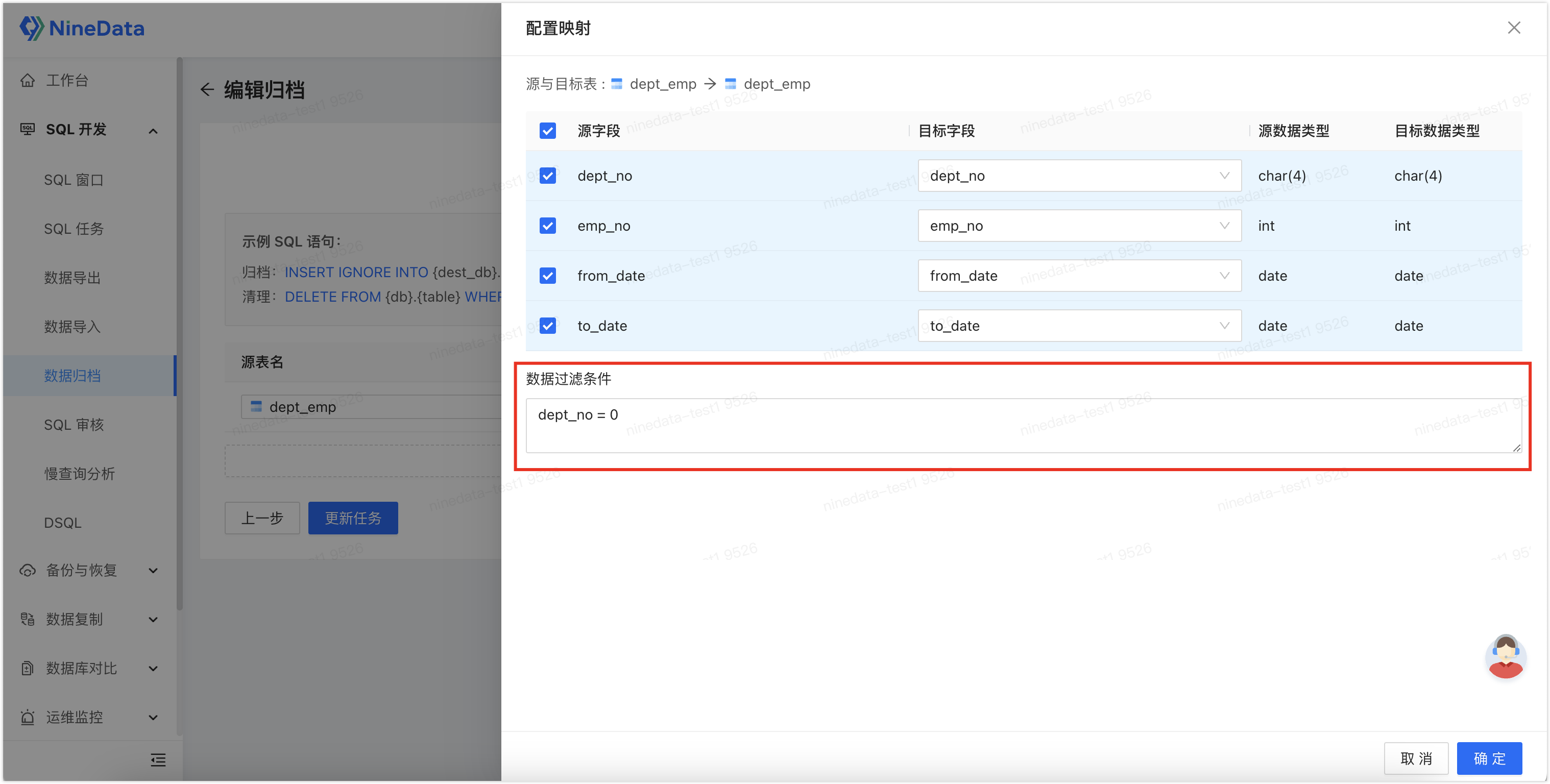
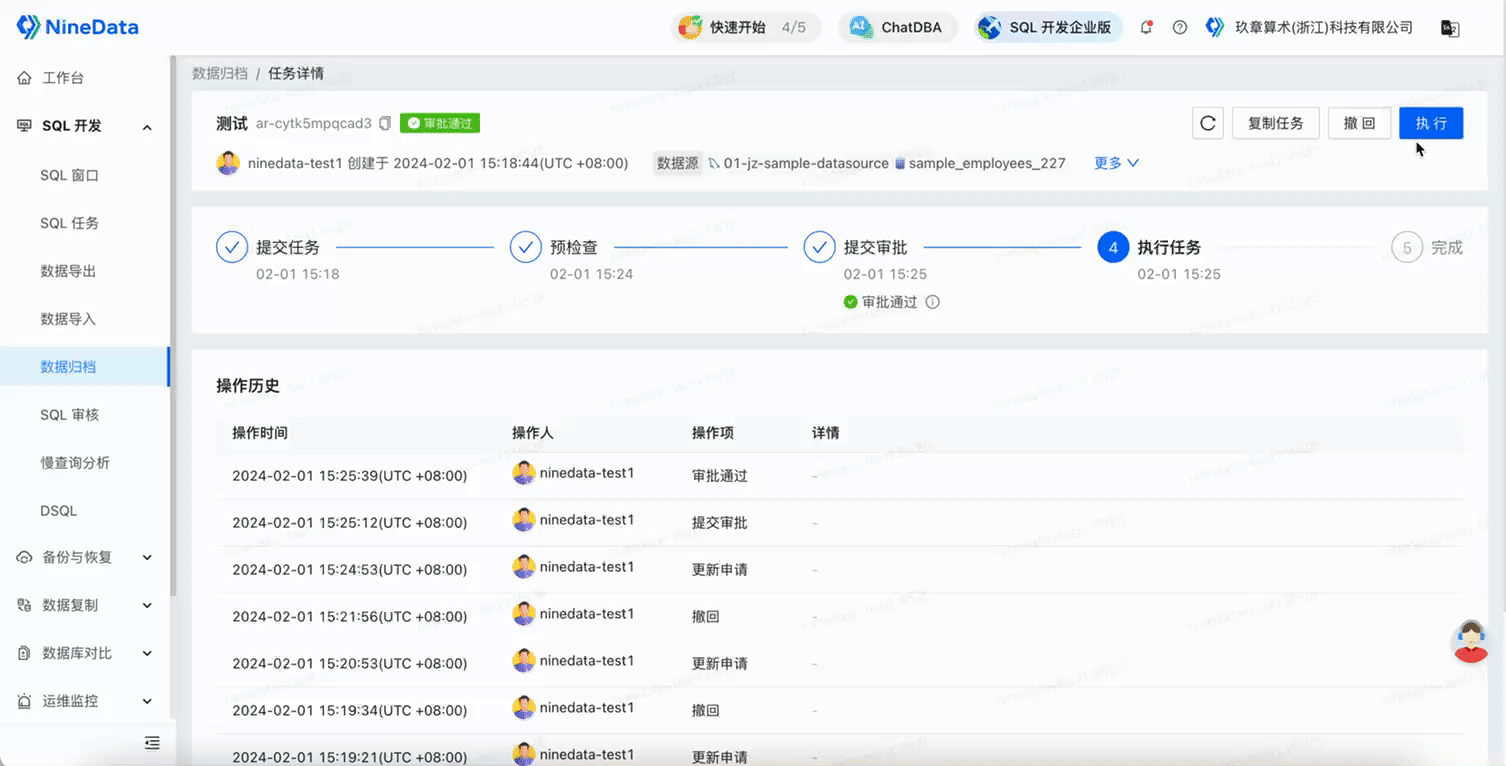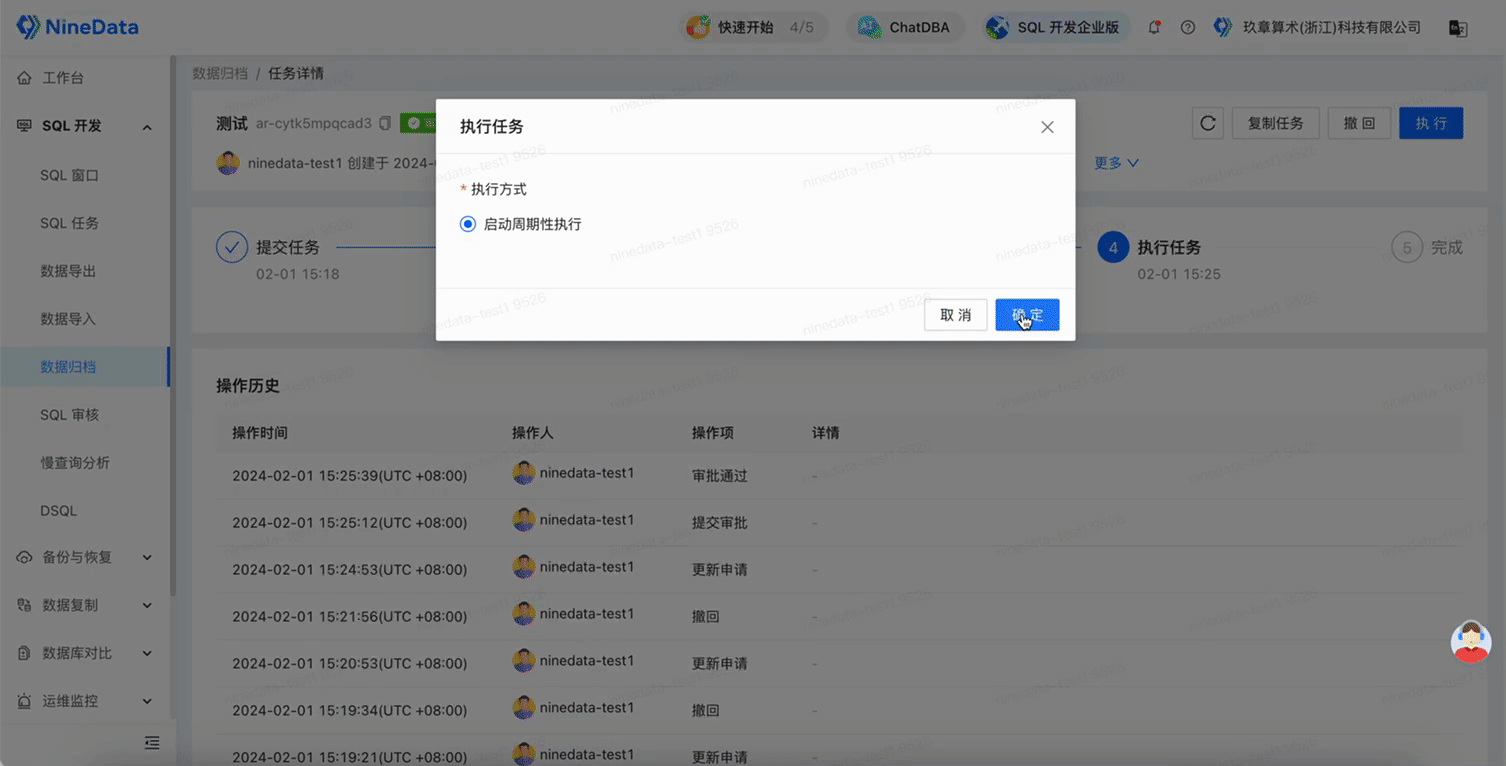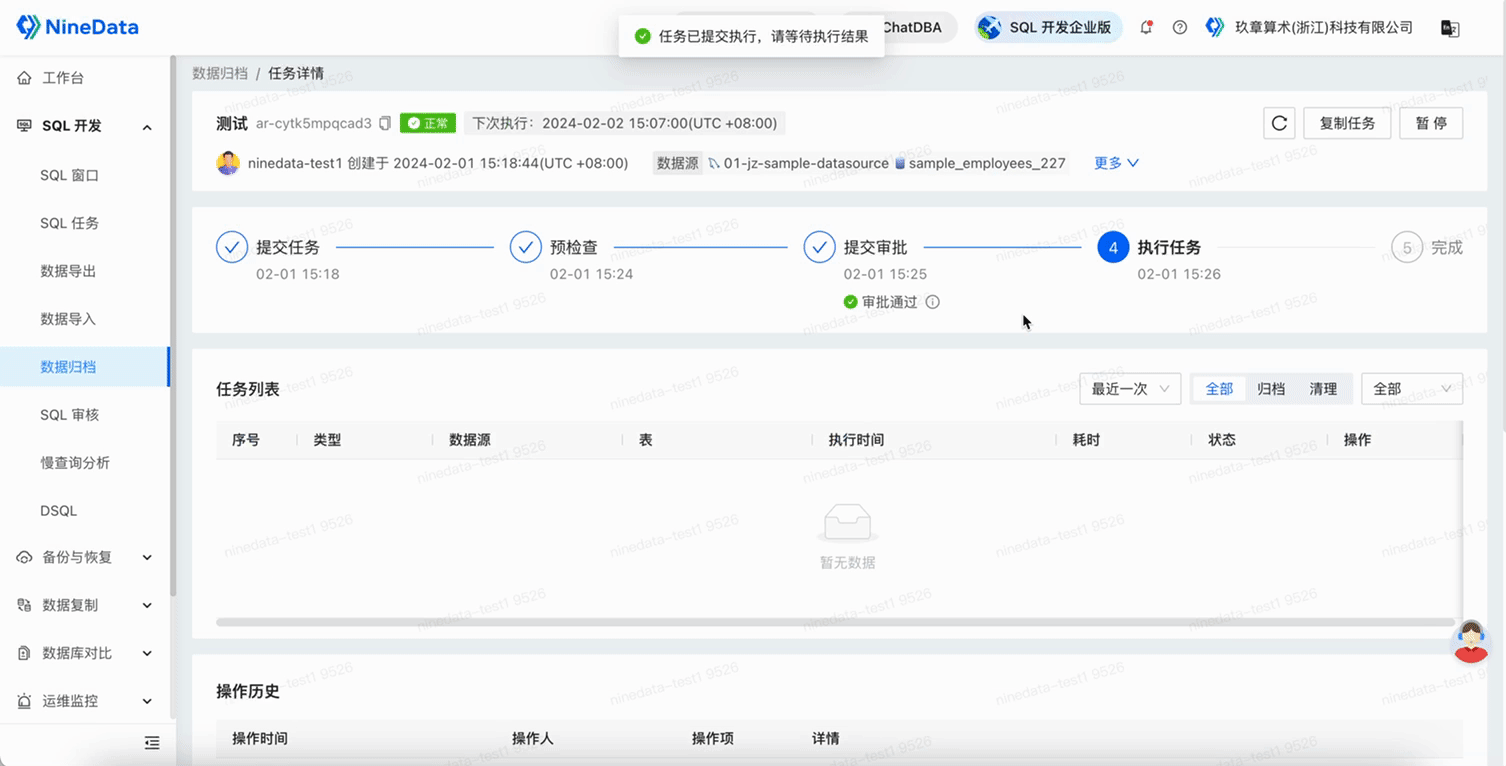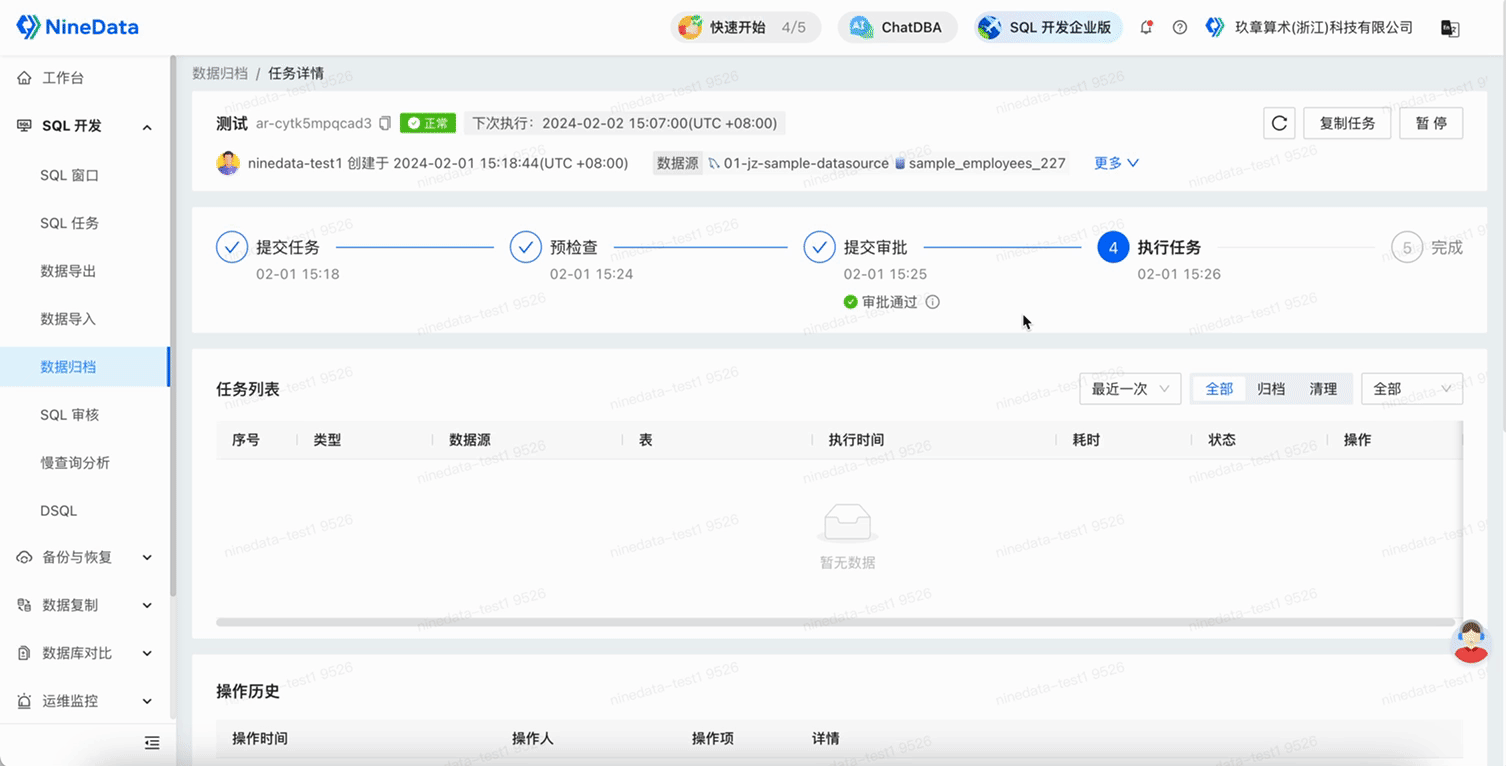
After clicking Create Task, it enters the approval process phase, the system will first pre-check the task, and after approval, the archiving task can be executed.
Summary
After the above process configuration is completed, the data archiving task will periodically scan the database based on the configured cycle, find data that meets the archiving conditions, and move it to the archive storage, and then clean up the archived data in the business database. In this way, only active and frequently accessed data is retained in the business database, which not only improves the performance of the database but also saves storage space and reduces storage costs.
Regarding concerns about the impact on performance, the author has conducted actual tests and found that NineData will automatically execute tasks in batches according to primary key indexes and unique indexes, with very little impact on the database.
By configuring a data archiving task only once, you can achieve automated operation and maintenance management of database space, without the need for manual intervention, easily simplifying the data cleaning work of DBAs, while also improving the compliance of database operations, helping companies achieve cost reduction and efficiency improvement, why not do it?