Data Import
NineData supports data import functionality, which allows files containing SQL scripts or data content to be imported into the target database, with a maximum file size of 5 GB.
Background
NineData's SQL task supports basic SQL script operations, providing a convenient way for batch execution of a small amount of SQL. However, for importing large amounts of data, it can take a lot of time and effort to process, so other efficient tools are needed to simplify this process. To address this issue, NineData offers powerful data import functionality to help users easily import large amounts of data from files into the target database.
Functionality
NineData's data import functionality allows users to import files containing large amounts of data into the target database. The specific functionality details are as follows:
Supported Data Sources: Currently supports MySQL (including MySQL-compatible data sources), SQL Server, PostgreSQL, Oracle, OceanBase Oracle, Db2, Dameng, KingbaseES for PostgreSQL, TiDB, OceanBase MySQL, GreatSQL, Vastbase, GoldenDB, KingbaseES for Oracle, MariaDB, MongoDB, Lindorm, and TDSQL MySQL Edition.
Supported import types and corresponding file formats:
Import Type File Formats SQL ZIP, SQL, TXT CSV ZIP, CSV EXCEL ZIP, XLS, XLSX JSON JSON Maximum file size supported: 5 GB
Supported character sets: UTF-8, GBK
Data security guarantee: Under the organizational modelThe organizational model supports assigning different roles and resource management permissions to each user under the organization, which is suitable for multi-user collaborative development under the same organization. It ensures data security while improving overall production efficiency., strict permission control is supported for data, and data import requires approval process to ensure data security.
- Approval Process (Approvers): By default, data import tasks must be approved by the System Administrator before they can be executed. The administrator role supports adjusting the approval process as needed.
- Approval Process (Executors): It supports configuring the executor of the import task after approval, which can be set as System Executor, Applicant Executor, or Approver Executor (the last approver in the approval process).
- Development Standards: If the imported data file (SQL) contains multiple types of import statements, to ensure database security, only
INSERTstatements are executed by default. The administrator role supports adjusting the development standards as needed. - Execution Time: After the import task is approved, the Executor can choose to execute it immediately or schedule it according to specific execution time requirements.
Use Cases
NineData's data import functionality can play an important role in the following scenarios:
- External data source import: In the scenario where an enterprise needs to obtain data from an external source, NineData's data import functionality can help users import the data from the external source into the target database for subsequent processing and management. For example, some e-commerce platforms need to import product data from their supplier's system, and NineData's data import functionality can help them quickly import the data into the database.
- Data initialization: When setting up a new database or resetting the database structure, the initial data needs to be imported into the database. NineData's data import functionality can help users import the initial data from files into the target database, thereby quickly initializing the database.
- Large-scale data updates: The scenario where a large-scale data update needs to be executed on the database.
- Example 1: An enterprise needs to import a large amount of platform order data into their database for storage and analysis purposes.
- Example 2: An enterprise needs to delete or merge duplicate or invalid data, or format or convert the data.
- Example 3: An enterprise needs to update product prices, inventory, or other key business data in bulk.
- Example 4: An enterprise needs to update the timestamps or data formats for troubleshooting purposes.
Precautions
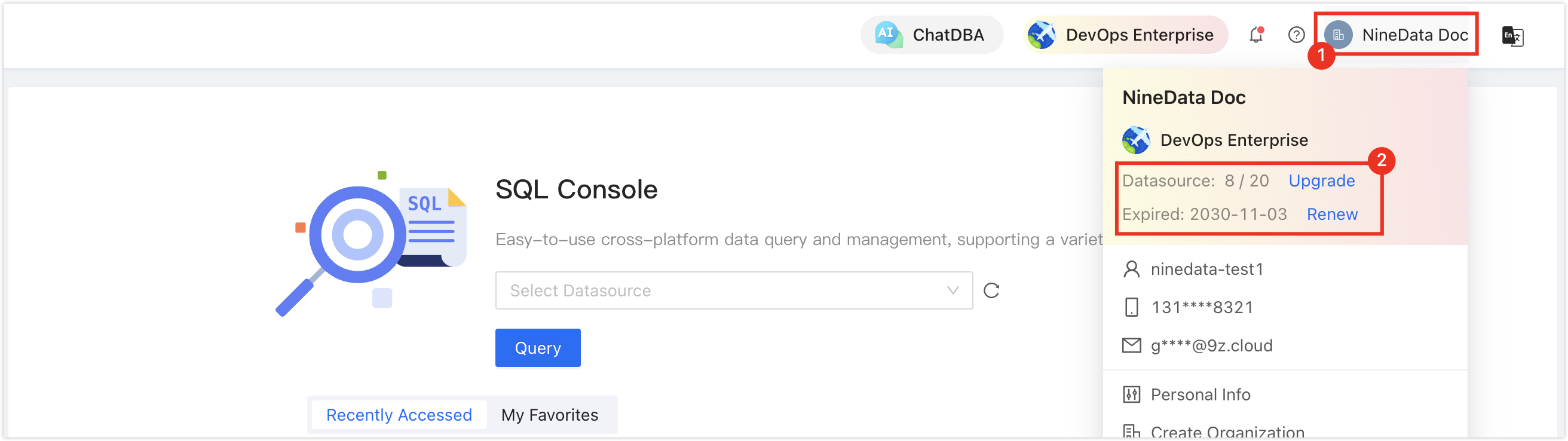
In the commercial versions (DevOps Pro, DevOps Enterprise), please ensure that your monthly/yearly subscription is not expired, as it may result in the inability to use the Database DevOps service. You can quickly check the remaining quota and expiration date at the top right corner of the NineData console page.
Limitations
- Non-SQL type data files must be imported into a specified table, and all columns in the data file must exist in the target table, otherwise the import task will fail.
- When importing SQL type files that do not contain structure, please make sure that the table corresponding to each statement in the file already exists in the target database.
- The current data import function does not support specification validation (pre-check), so caution should be exercised when using it.
Submitting a Task
Prerequisites
- The permissions to the target database and tables have been granted. If not, please apply for them. For more information, see Permission Application and Approval.
- The module permission Data Import is granted (which is granted by default). If you cannot see this entry, please contact your system administrator.
- The permission Data Import - Submit is granted. For information on how to apply for this permission, see Permission Application and Approval.
Steps
Log in to the NineData Console.
Click DevOps>Data Import in the left navigation pane.
On the Data Import page, click Create Import in the upper-right corner of the page.
On the Create Import page, configure the settings according to the table below.
Parameter Description Name Enter a name for the data import task. This is only required in organization mode. For ease of subsequent search and management, please use a meaningful name. The name can be up to 64 characters long. Datasource/Database Select the target data source and database for the data import task. When Import Type is not SQL, you also need to select the specific target table for the import (SQL Server, Oracle, OceanBase Oracle, Db2 requires selecting the corresponding Schema before choosing the target table for import).
Note: If you do not have permissions for this data source or database, a prompt will appear on the page. You can click the Apply Permission button in the prompt box to apply for permissions. For more information, see Authorization and Approval Process.Import Type Select the data import type, which supports the following three types: - SQL: A file containing a series of SQL statements that are imported into a MySQL database through SQL playback.
- CSV: A text file format where each line represents a record, where each field is usually separated by commas.
- EXCEL: The format of an Excel file, where each table cell contains a field value.
- JSON:MongoDB only.
Upload Click the Upload button to select the data file you need to import into the database. Supports uploading .zipcompressed packages containing multiple data files for batch upload (except for JSON type).
Note: Please ensure that the column names and column numbers in the data file are consistent with those in the target table for the import, otherwise the import may fail.File Encoding Select the character set of the data file to import: - Auto-Recognize (default): The system automatically detects the character set of the data file.
- UTF-8: A variable-length Unicode character encoding.
- GBK: A Chinese character encoding that extends from the GB2312 encoding.
Import Reason Enter the reason for the import. This is only required in organization mode and is used for the approval process. Batch Mode When enabled, the system does not perform specification pre-checks on the task, but only performs permission checks on its data source. This mode merges multiple SQL statements into one batch statement for submission, which can reduce network overhead and improve import performance. This mode is fixedly enabled in the current version. Executor The person responsible for executing the task after it has been approved, which is only required in organization mode.
Note: The options in the Executor list depend on the following two situations:- The SQL Dev policy for the current data source have been configured: The options in the list are based on the Import Executor Config rule configured in the current policy. This rule is located on the SQL Task & Console tab. For information on how to configure development specifications, see Edit policy.
- The current data source has not been configured with development specifications: The options in the list are users who have permission for Data Import - Exec on the current data source. For more information on authorization, see Configuring user permissions.
Advanced Clicking on Advanced will expand the configuration options. MySQL, TiDB, GreatSQL
- Column Setting (optional when Import Type is CSV or EXCEL):
- First Row as Field Name (selected by default): Choose whether the first row of the data file contains field names. Please check or uncheck based on the actual content of your import file.
- Field Delimiter (In CSV format only, optional and selected by default): Choose the delimiter for each field in the data file. Select based on the actual content of your import file.
- Columns: This option allows you to select which column(s) from the data file to import into the target table. Multiple selections are supported. When selecting multiple columns, the system will import them in the order of the selected column names. This feature is useful when the column names or the number of columns in the data file and the target table are different.
- Import Mode (optional when Import Type is CSV or EXCEL):
- Insert (default): Insert data into the table. If a similar row already exists in the table, the insertion will fail and an error message will be displayed.
- Insert Ignore: Insert data into the table. If a similar row already exists in the table, the insertion operation will skip that row without making any changes.
- Replace Into: Insert data into the table. If a similar row already exists in the table, it will be directly overwritten.
- Exec Config:
- Ignore Foreign Key: Select this option to skip checking restrictions imposed by foreign key constraints.
PostgreSQL
- Column Setting (optional when Import Type is CSV or EXCEL):
- First Row as Field Name (selected by default): Choose whether the first row of the data file contains field names. Please check or uncheck based on the actual content of your import file.
- Field Delimiter (In CSV format only, optional and selected by default): Choose the delimiter for each field in the data file. Select based on the actual content of your import file.
- Columns: This option allows you to select which column(s) from the data file to import into the target table. Multiple selections are supported. When selecting multiple columns, the system will import them in the order of the selected column names. This feature is useful when the column names or the number of columns in the data file and the target table are different.
- Import Mode (optional when Import Type is CSV or EXCEL):
- Insert (default): Insert data into the table. If a similar row already exists in the table, the insertion will fail and an error message will be displayed.
- Insert Ignore: Insert data into the table. If a similar row already exists in the table, the insertion operation will skip that row without making any changes.
SQL Server
- Column Setting (optional when Import Type is CSV or EXCEL):
- First Row as Field Name (selected by default): Choose whether the first row of the data file contains field names. Please check or uncheck based on the actual content of your import file.
- Field Delimiter (In CSV format only, optional and selected by default): Choose the delimiter for each field in the data file. Select based on the actual content of your import file.
- Columns: This option allows you to select which column(s) from the data file to import into the target table. Multiple selections are supported. When selecting multiple columns, the system will import them in the order of the selected column names. This feature is useful when the column names or the number of columns in the data file and the target table are different.
- Import Mode (displayed when Import Type is CSV or EXCEL):
- Insert (fixed): Insert data into the table. If a similar row already exists in the table, the insertion will fail and an error message will be displayed.
- Exec Config:
- Ignore Foreign Key: Select this option to skip checking restrictions imposed by foreign key constraints.
Oracle|Oceanbase Oracle
Column Setting (optional when Import Type is CSV or EXCEL):- First Row as Field Name (selected by default): Choose whether the first row of the data file is the field name. Please check or uncheck based on the actual situation of your import file.
- Field Delimiter (optional and selected by default, for CSV only): Choose the delimiter for each field in the data file. Please select based on the actual situation of your import file.
- Columns: This option allows you to select which column(s) in the data file to import into the target table, supporting multiple selections. When selecting multiple columns, the system will import according to the order of the column names chosen by the user. This feature is suitable for situations where the column names in the data file and the target table are inconsistent or the number of columns is different.
Db2|DaMeng
Column Setting (optional when Import Type is CSV or EXCEL):- First Row as Field Name (selected by default): Choose whether the first row of the data file is the field name. Please check or uncheck based on the actual situation of your import file.
- Field Delimiter (optional and selected by default, for CSV only): Choose the delimiter for each field in the data file. Please select based on the actual situation of your import file.
- Columns: This option allows you to select which column(s) in the data file to import into the target table, supporting multiple selections. When selecting multiple columns, the system will import according to the order of the column names chosen by the user. This feature is suitable for situations where the column names in the data file and the target table are inconsistent or the number of columns is different.
Lindorm
Exec Config:- Ignore Foreign Key: Select this option to skip checking restrictions imposed by foreign key constraints.
MongoDB
Import Mode:- INSERT: Inserts all documents from the file into the target collection. If a document with the same
_idalready exists, an error will be reported and the process will exit. - UPSERT: Inserts all documents from the file into the target collection. If a document with the same
_idalready exists, the existing document's values will be updated/overwritten. - MERGE: Inserts all documents from the file into the target collection. If a document with the same
_idalready exists, the documents are merged upon insertion, meaning the old data from the target and the new data are both retained.
Click Save to automatically jump to the Details page.
- If you are in Personal modeBy default, after registering a NineData account, you are in Personal mode, which allows you to use the four modules provided by NineData without any obstacles. Personal mode is suitable for individual developers, such as backup, recovery, synchronization, comparison of their own databases, and daily development work combined with SQL Console., the import task will start and execute automatically. Wait for the task status to change to Success, then the step is completed.
- If you are in Organization modeOrganization mode supports assigning different roles and resource management permissions to each user under the organization, which is suitable for collaborative development by multiple users in the same organization, while ensuring data security and improving overall productivity., please follow the steps below.
At the Policy Pre-check node, wait for the task status to change to Pending, and then click the Submit Approval in the upper right corner of the page to enter the Submit Approval node. In the Policy Pre-check node, you can also perform the following operations:
- Click the
 icon in the upper right corner of the page to refresh the task status.
icon in the upper right corner of the page to refresh the task status. - Click Check Again in the upper right corner of the page to perform the check again.
- Click Withdraw in the upper right corner of the page to directly withdraw the task or edit the task and submit it again.
- Click Duplicate in the upper right corner of the page to copy a new task with the same configuration.
tip- Policy Pre-check will automatically check the imported task, including syntax error check (when Import Type is SQL), estimated row count check, and library permission check. If any issues are found during the process, specific information will be prompted for you to locate and modify.
- Under Batch Mode, this node will be skipped automatically, and the task will come to Submit Approval node, and the task status will change to Pending.
- If the approval process is not configured for this data source, the task will automatically skip the Policy Pre-check and Submit Approval nodes and come to the Execute Task node, and the task status will change to Approved. You can directly execute step 9.
- Click the
Click on Submit Approval in the upper right corner of the page, select the approvers in the pop-up window, and click OK.
tip- Depending on the configuration of the approval process, the number of approvers to be selected here may vary. Please select according to the actual situation.
If the Not Specifying Approvers feature is enabled in the current approval process, this section will display After submission, all approvers can review. Please check the results in the approval process.. You do not need to manually specify an approver; all personnel authorized to approve the current work order will receive approval notifications and be able to approve it.
The task status will change to Pending Approval. Before the approval, you can perform the following operations:
- Click the icon in the upper right corner of the page to refresh the task status.
- Click Withdraw in the upper right corner of the page to directly withdraw the task or edit and submit the task again.
- Click Transfer in the upper right corner of the page to change the approver of the task.
- Click Duplicate in the upper right corner of the page to copy a new task with the same configuration.
- Click the
When the task status changes to Approved, click Execute of the task's Executor in the upper right corner of the page, select Execution Method, and click OK.
- Execute Now: Execute the data import task immediately.
- Scheduled Execution: Select a time to execute the data import task.
Wait for the task status to change to Success.
Approve Tasks
Prerequisites
- Created or joined an organization. For more information, see Manage Organizations.
- The NineData console is in organization mode. For information on switching from personal mode to organization mode, see Switch to Organization.
- The current data import task is in status Pending Approval.
- You are the Administrator or the Approver of the current data import task.
Procedure
Log in to the NineData Console.
Click DevOps and then Data Import on the left navigation pane.
On the Data Import page, find the target task and click the task ID or Details in the Actions column on the right of the task.
tipYou can also hover over the
 icon at the top of the page and click the target task in the Todo tab.
icon at the top of the page and click the target task in the Todo tab.On the Details page, review the approval request and choose Transfer, Approved, or Rejected based on the actual situation.
Operation Description Transfer Transfer the approval request to another user. Approved Approve the request. After clicking Approved, you can optionally enter the Reason, and click OK. Rejected Reject the request. After clicking Rejected, you also need to enter the Reason for rejection and click OK.