Kafka Replication to ClickHouse
NineData's data replication supports copying data from Kafka to ClickHouse, enabling real-time integration of data.
Background Information
Kafka is a distributed message queue known for its high throughput, low latency, high reliability, and scalability. It is suitable for scenarios that require real-time data processing and distribution and has become a core data source for upstream data warehouses.
ClickHouse, on the other hand, is a columnar database management system (DBMS) that can efficiently handle and analyze large amounts of real-time data when integrated with Kafka.
Prerequisites
- Source and target data sources have been added to NineData. For instructions on adding data sources, refer to Creating a Data Source.
- Source data source is Kafka version 0.10 or above.
- Target data source is ClickHouse version 20.3 or above.
- Based on the field names in the Kafka JSON objects, corresponding databases, tables, and columns have been created on the target ClickHouse.
Steps
NineData’s data replication product has been commercialized. You can still use 10 replication tasks for free, with the following considerations:
Among the 10 replication tasks, you can include 1 Incremental task, with a specification of Micro.
Tasks with a status of Terminated do not count towards the 10-task limit. If you have already created 10 replication tasks and want to create more, you can terminate previous replication tasks and then create new ones.
When creating replication tasks, you can only select the Spec you have purchased. Specifications that have not been purchased will be grayed out and cannot be selected. If you need to purchase additional specifications, please contact us through the customer service icon at the bottom right of the page.
Log in to the NineData Console.
Click on Replication > Data Replication in the left navigation bar.
On the Replication page, click Create Replication.
On the Source & Target tab, configure as per the table below and click Next.
Parameter Description Name Enter a meaningful name for the data synchronization task. It is recommended to use a name that is easy to identify and manage. Maximum 64 characters. Source Data source where the synchronization object is located. Choose the Kafka data source where the data to be copied is located. Target Data source that receives the synchronization object. Choose the target ClickHouse data source. Kafka Topic Select the Kafka topic to be copied. Message Format Choose the format in which data will be copied to ClickHouse. Currently, only Canal-JSON is supported. Replication Started - Earliest (Copy Earliest Message from Topic): Find the earliest message in the Kafka topic and copy it to ClickHouse in order.
- Latest (Copy Latest Message from Topic after Starting): Ignore existing data in the Kafka topic and only copy new messages generated after the task starts.
- Customer Offset (Start From Customer Offset): Customize the message position in the Kafka topic, i.e., the Offset number. The system will start copying messages from this Offset number in order.
Target Table Exists Data - Pre-Check Error and Stop Task: Stop the task if data is detected in the target table during the pre-check stage.
- Ignore existing target data and append to it.: Ignore the data detected in the target table during the pre-check stage and append other data.
- Clear target existing data before write: Delete the data detected in the target table during the pre-check stage and rewrite it.
On the Objects tab, configure the parameters below and click Next.
Parameter Description ClickHouse Replicate Objects Choose the storage location after Kafka data is copied to ClickHouse. You can choose All Objects to include all databases in ClickHouse, or Customized Object to select the location where Kafka data should be stored. Select the desired location(s) from the Source Object list, and click > to add them to the Target Object list on the right. On the Mapping tab, you can individually configure the mapping between key-value pairs in Kafka messages and columns in each ClickHouse table. As long as the Kafka message meets the configured conditions, it will be saved in the corresponding location in ClickHouse. For more information, refer to Appendix.
tipWhen Message Format is Canal-JSON, you need to configure the mapping of the $.database and $.table fields in each ClickHouse database and table. For example, if you configure $.database as
ninedata_m2cand $.table assbtest1, all messages in Kafka that meet this condition will be copied to the corresponding columns in the target ClickHouse database table.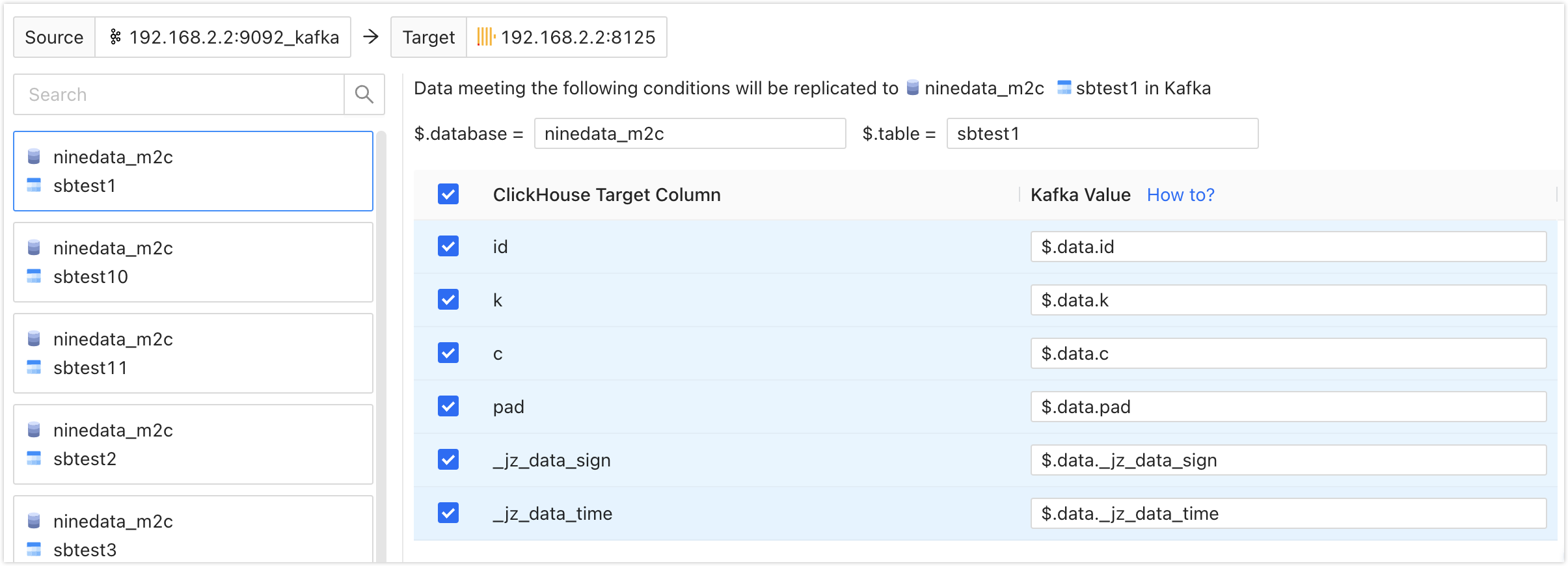
On the Pre-check tab, wait for the system to complete the pre-check. After the pre-check passes, click Launch.
tipIf the pre-check fails, click Details to the right of the target check item, troubleshoot the failure cause manually, and click Check Again to re-run the pre-check until it passes.
For items with Result as Warning, you can fix or ignore them based on the specific situation.
On the Launch page, when prompted with Launch Successfully, the synchronization task starts running. At this point, you can perform the following operations:
- Click View Details to view the execution status of each stage of the synchronization task.
- Click Back to list to return to the Replication task list page.
Viewing Sync Results
Log in to the NineData Console.
Click on Replication > Data Replication in the left navigation bar.
On the Replication page, click on the ID of the target sync task to open the Details page. The page is explained below.

Number Feature Description 1 Sync Delay The data synchronization delay between the source and target data sources. 0 seconds means there is no delay between the two ends, indicating that Kafka currently has no consumed data. 2 Configure Alerts After configuring alerts, the system will notify you through your chosen method in case of task failure. For more information, see Operation and Maintenance Monitoring Introduction. 3 More - Pause: Pause the task. Only tasks with a status of Running can be selected.
- Terminate: End a task that is unfinished or listening (i.e., in incremental synchronization). After terminating the task, it cannot be restarted. Proceed with caution.
- Delete: Delete the task. Once a task is deleted, it cannot be recovered. Proceed with caution.
4 Incremental Copy Display various monitoring indicators for incremental copy. - Click on Log on the right side of the page to view the execution log of incremental copy.
- Click on the
 icon on the right side of the page to view the latest information.
icon on the right side of the page to view the latest information.
5 Modify Object Display modification records of the synchronization object. - Click on Modify Objects on the right side of the page to configure the synchronization object .
- Click on the icon on the right side of the page to view the latest information.
6 More Display detailed information about the current copy task, including the Kafka Topic and Message Format currently being synchronized, Started, etc.
Appendix 1: Definition of JSON_PATH
Kafka to ClickHouse replication is achieved by extracting data from Kafka JSON objects and storing it in the corresponding databases and tables in ClickHouse. JSON_PATH is a path expression used to locate specific elements in a JSON object. This section introduces the definition of JSON_PATH.
JSON_PATH consists of two main parts: Scope and pathExpression.
- Scope: Represented by the dollar sign ($), it signifies the root of the JSON.
- pathExpression: Used to match the path of specific elements in the JSON object. It consists of one or more pathLegs, which can be member, arrayLocation, or doubleAsterisk. Multiple pathLegs represent multiple levels.
- member: Matches the key in the JSON object. The format is
.<Key Name>or.*, where the former looks for the specified key name in the JSON object, and the latter represents all keys in the JSON object. - arrayLocation: Matches array elements in the JSON object. The format is
[<non-negative integer>]or[*], where the former locates array elements based on the specified non-negative integer, and the latter represents all array elements in the JSON object. - doubleAsterisk: Matches keys or array positions at any level. The format is
.**.
- member: Matches the key in the JSON object. The format is
Examples:
$.data: Matches the JSON object with the name data.$.data.order_id: Matches the key named order_id under the data JSON object.$[1]: Matches the array element with index 1 in the JSON object.$[*]: Matches all array elements in the JSON object.$.**: Matches any key or array position at any level in the JSON object.
Appendix 2: Pre-Check Item Checklist
| Check Item | Check Content |
|---|---|
| Target Database Data Existence Check | Check if data exists for the objects to be replicated in the target database |
| Source Data Source Connection Check | Check the status of the source data source gateway, instance accessibility, and accuracy of username and password |
| Target Data Source Connection Check | Check the status of the target data source gateway, instance accessibility, and accuracy of username and password |
| Target Database Permission Check | Check if the account permissions in the target database meet the requirements |
| Check if Target Table Contains System Fields | Check if the target table contains system fields _sign and _version |
| Target Database Same Name Object Existence Check | Check if the objects to be replicated already exist in the target database |