How to Compare the Consistency of MySQL Master-Slave Data?
As business scope expands, many companies choose the MySQL master-slave architecture to ensure the high availability of core businesses. This solution typically includes master-slave data synchronization, data backup and recovery, read-write separation, and high availability switching, making it a mature and reliable database architecture. However, under certain circumstances, this solution may have issues with inconsistent master-slave data, which may be caused by the following reasons:
- Binlog Loss: The master database fails, leading to the accidental loss of Binlog. The slave database, which relies on Binlog for data synchronization, will not be able to synchronize the latest data, causing inconsistency between the master and slave.
- Non-deterministic Operations in the Master Database: The master database performs non-deterministic operations, such as executing the RAND() function or operations involving timestamps. Due to the different execution timing in the slave database, this leads to the occurrence of master-slave inconsistency.
- Unauthorized Operations: Due to operational errors or other unforeseen reasons, personnel directly connect to the slave database to perform data operations using account passwords, leading to inconsistent master-slave data.
Problems Caused by Master-Slave Inconsistency
- Business Interruption: When the master database fails and triggers a master-slave switch, the slave database is upgraded to the new master database. Due to the inconsistency between the new master database and the original master database, it will cause business logic confusion or interruption.
- Data Loss: If the master-slave switch is executed without the slave database fully synchronizing the data from the master database, it may lead to the permanent loss of that part of the data.
To avoid the above problems and ensure the stability of the MySQL master-slave architecture and data consistency, additional monitoring and synchronization solutions are needed to address potential data inconsistencies in different scenarios. NineData's data comparison feature perfectly solves these issues.
Challenges of Existing Solutions
To verify the consistency of MySQL master-slave database data, companies usually use some open-source tools. However, in some scenarios, these tools may face some challenges:
- Performance Overhead: Running data comparison tools on large-scale data tables may bring significant performance overhead. Especially in high-concurrency production environments, ensuring consistency may require a long execution time, thereby affecting the normal operation of the database.
- Real-time: Most open-source tools run offline and cannot provide real-time monitoring mechanisms. In scenarios where it is necessary to discover problems and take measures in a timely manner, many issues may arise.
- Manual Triggering: Since most comparison tools need to be triggered manually, this requires DBAs or operations personnel to perform regular check operations. In frequently changing environments, there may be forgotten or missed operations, leading to potential data consistency issues.
- Operational Complexity: Many tools require full command-line operations and need to go through multiple steps of configuration and execution, making the usage threshold relatively high. For non-professional developers or operations personnel, a lot of time is needed to learn and adapt, which invisibly increases the cost for companies.
NineData's Solution
NineData's database comparison feature can quickly compare data between master and slave databases. In addition to one-time comparisons, it can also configure long-term periodic comparison tasks according to business needs, helping you track changes in master-slave databases in real-time, discover problems, and fix them quickly. Compared to other data comparison tools, NineData's database comparison has the following advantages:
Comprehensive Comparison Features: Supports consistency comparison of database table structure and data, and provides one-time comparison, periodic comparison, quick comparison, and other comparison features suitable for various usage scenarios.
Powerful Performance: Based on large server clusters, it supports comparison of data exceeding 1 TB, with a comparison data volume of hundreds of megabytes per second.
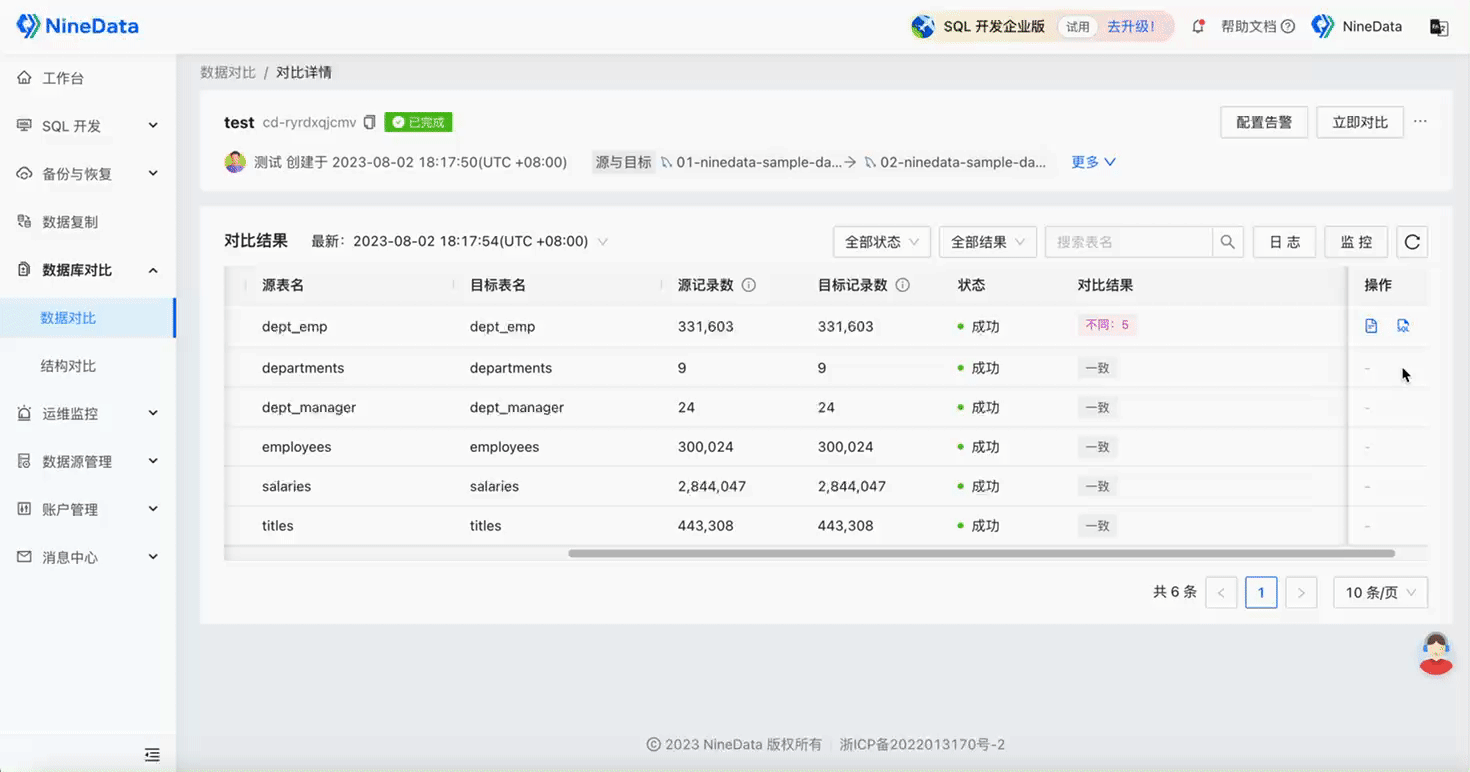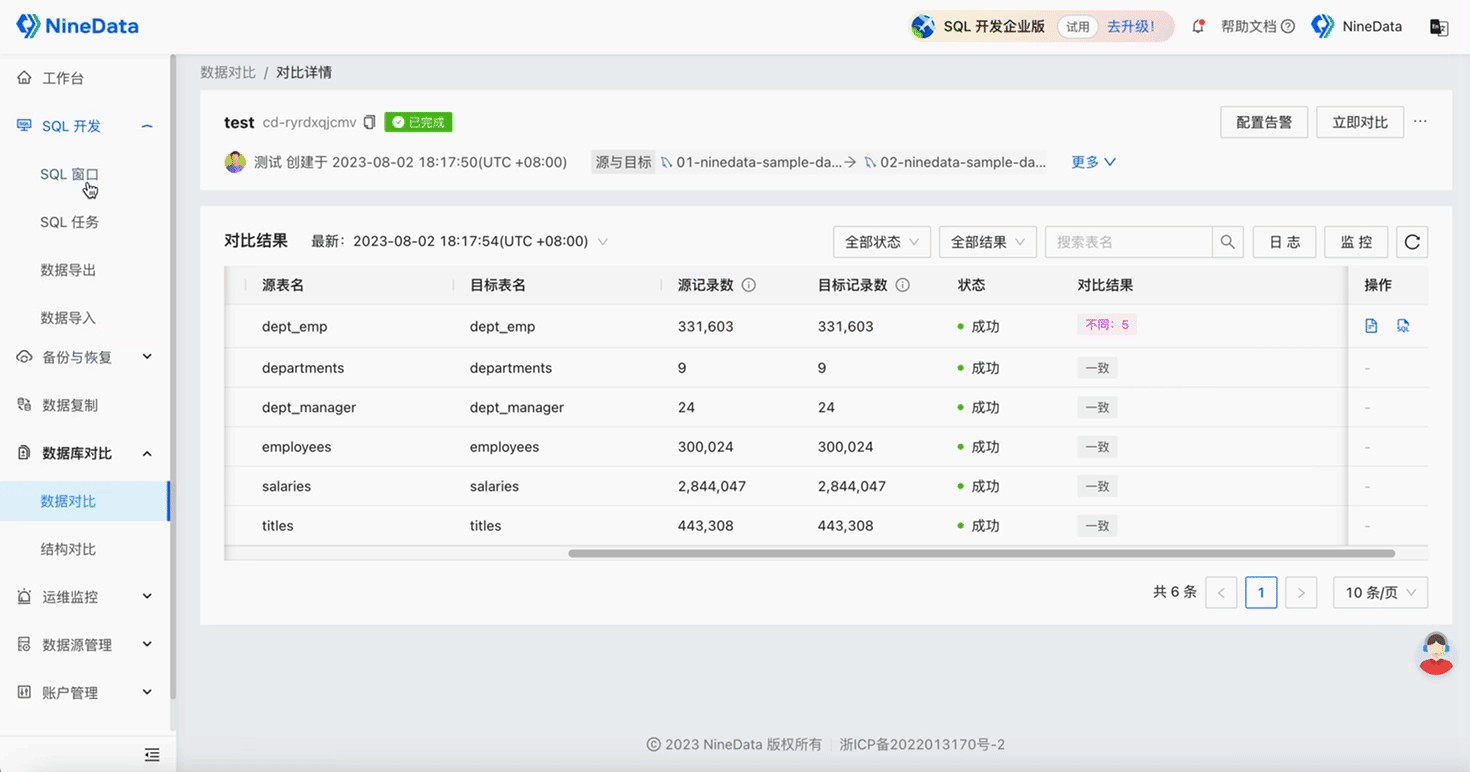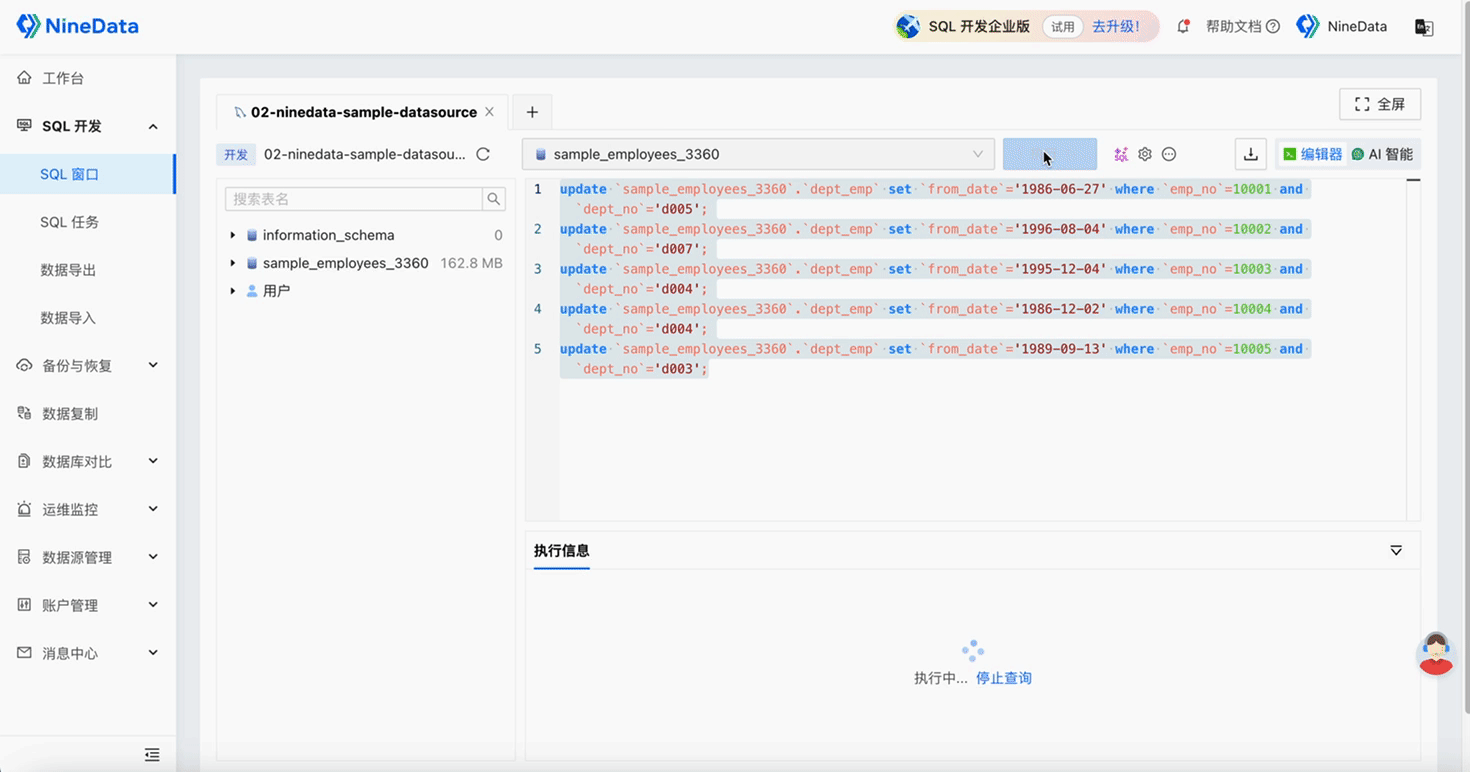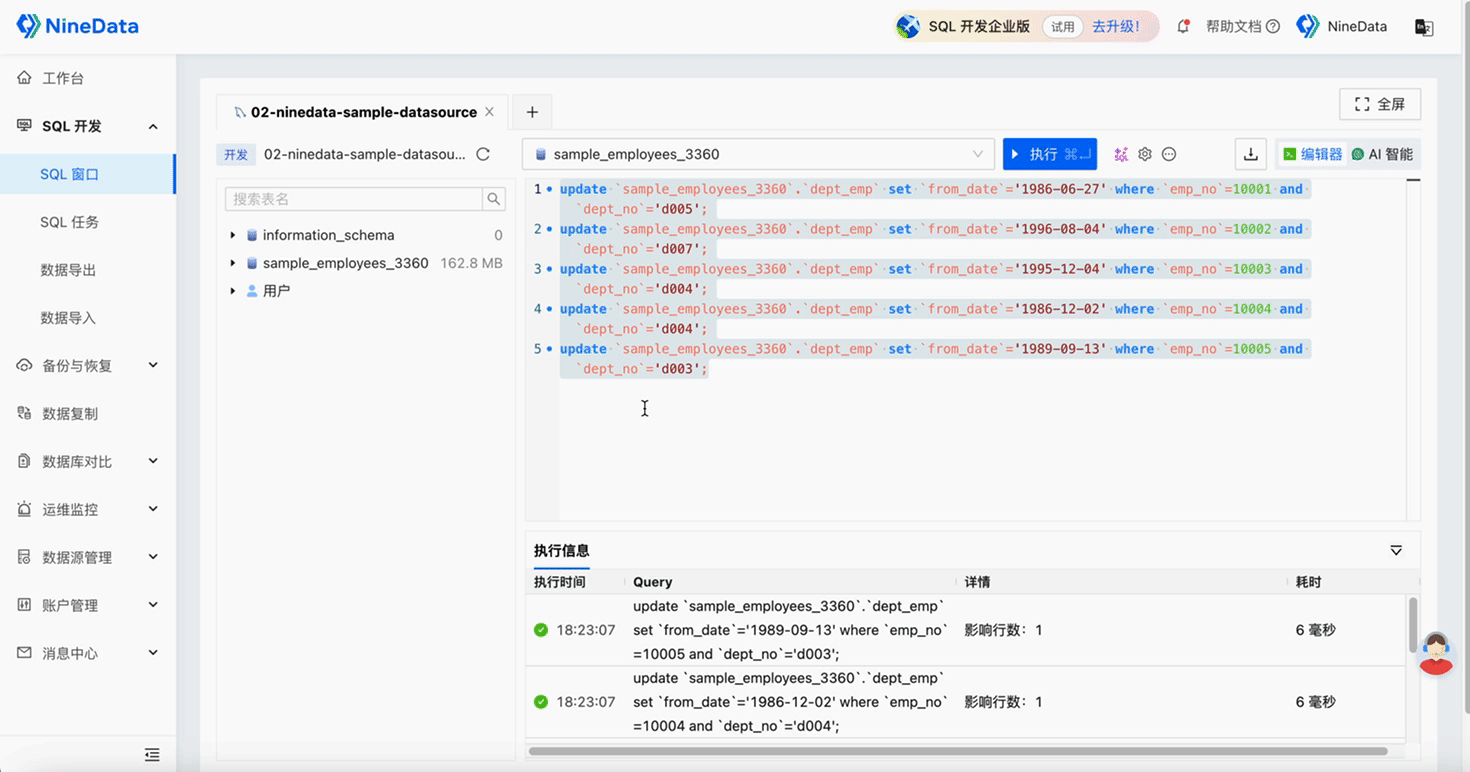
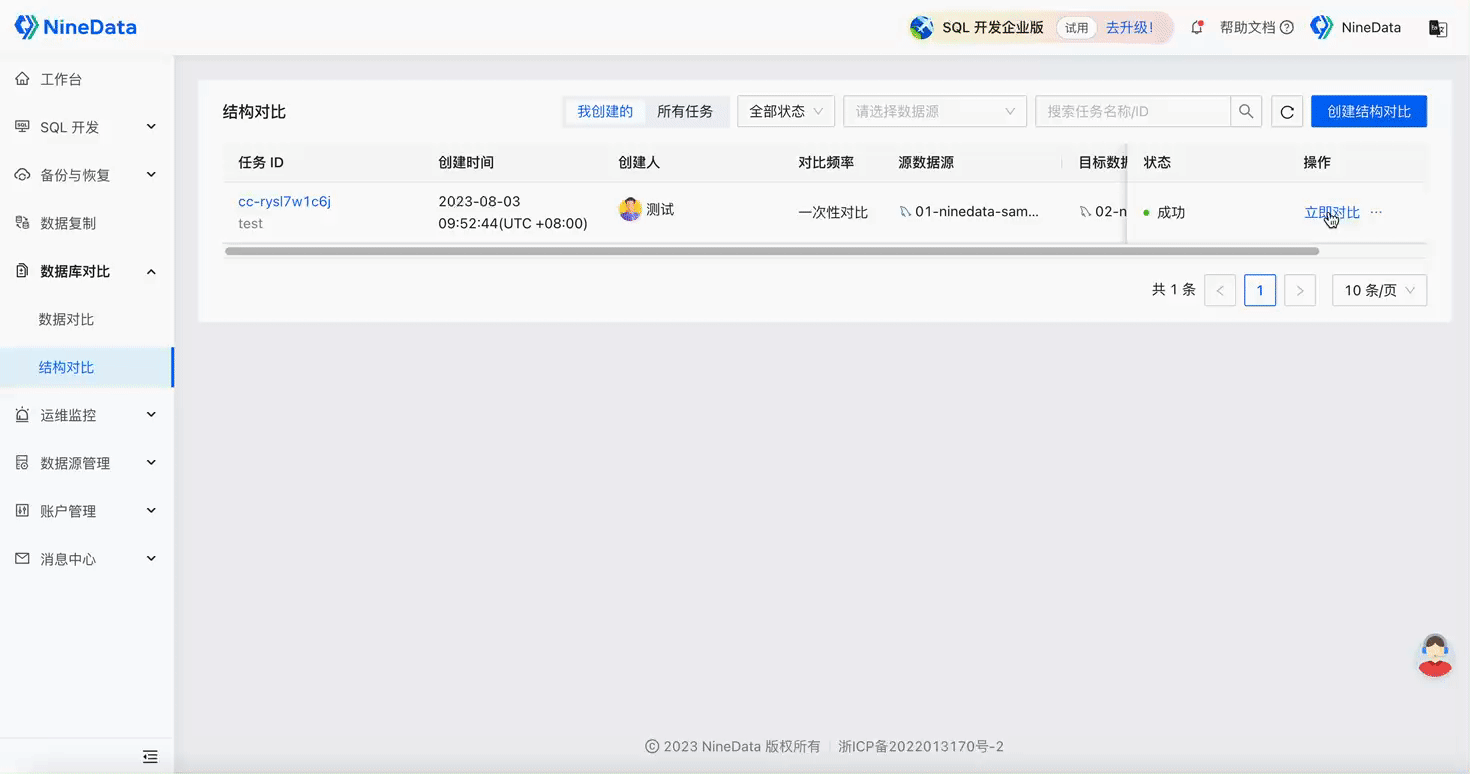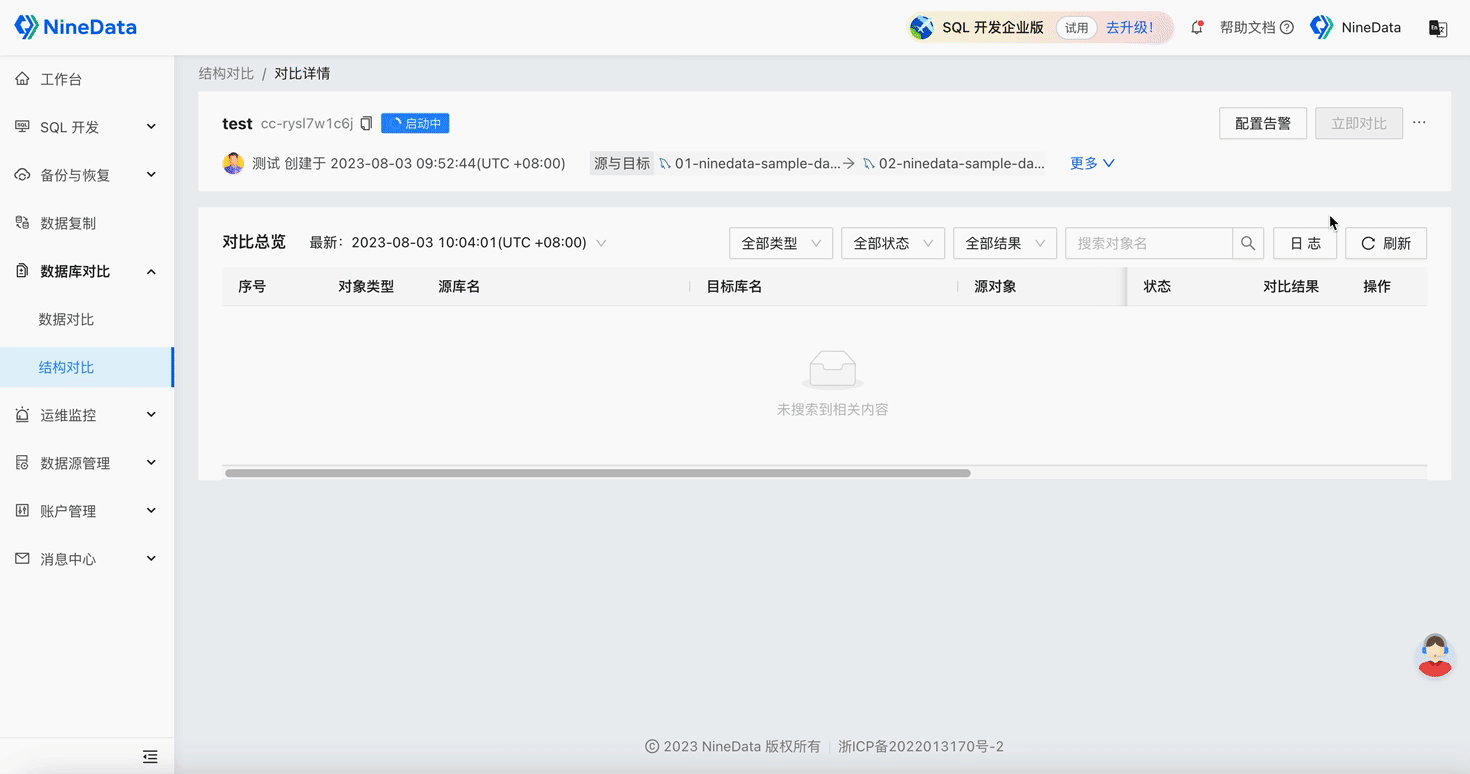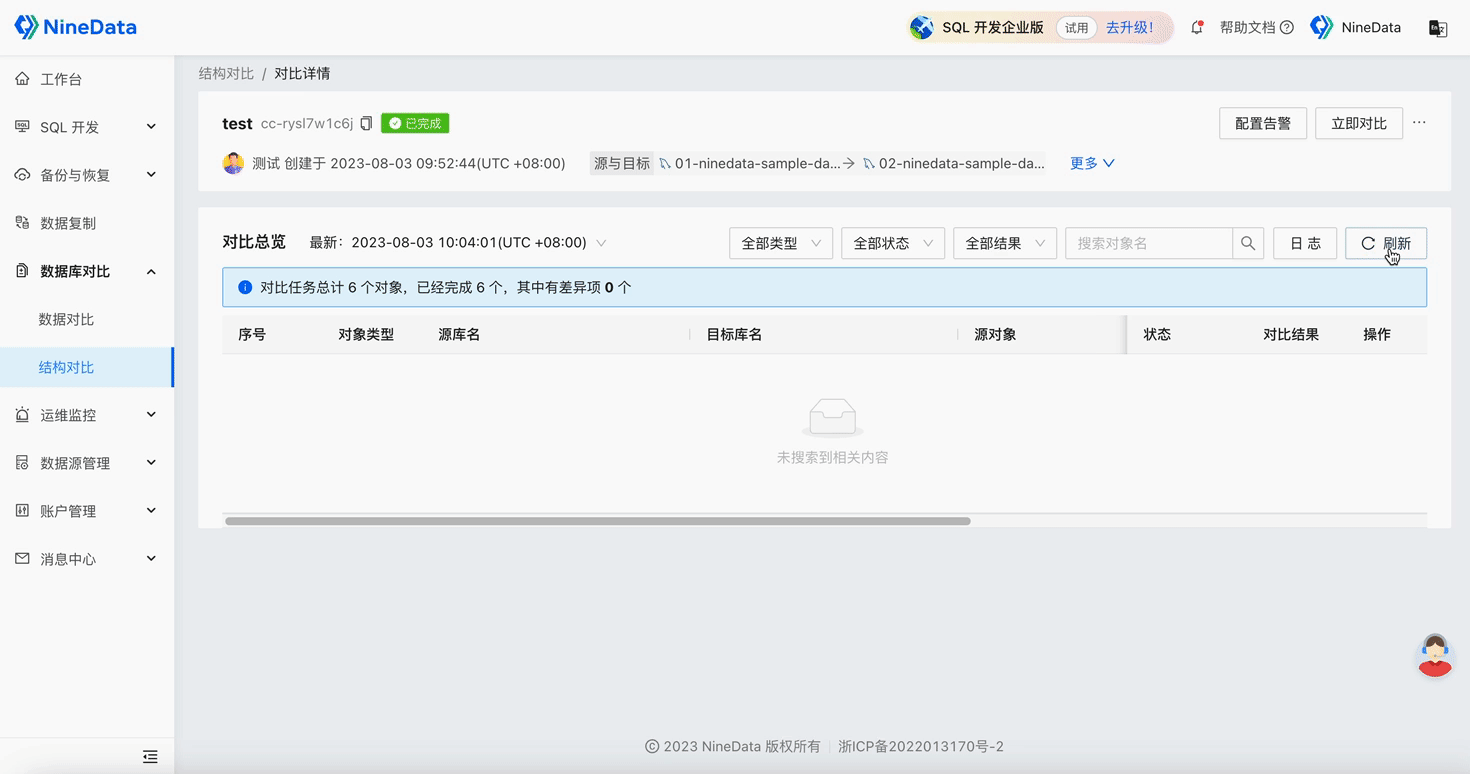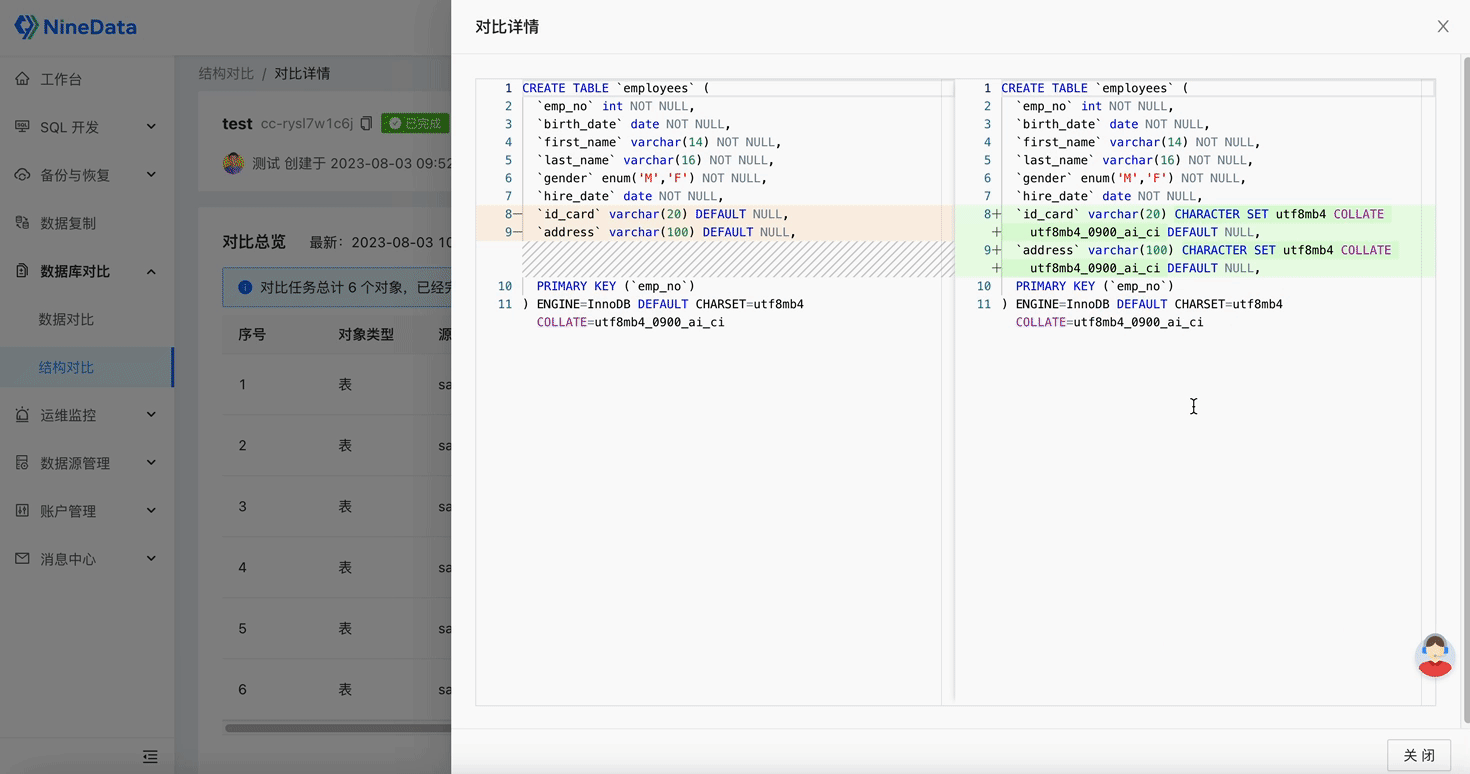
One-click Difference Repair: Automatically generates repair SQL for inconsistent content, and inconsistent data can be repaired by simply copying and pasting, saving a lot of time and effort.
Comprehensive Data Source Support: Supports various data sources such as MySQL, SQL Server, PostgreSQL, ClickHouse, Doris, SelectDB, Redis, etc.
Visual Interface: Has a simple and intuitive user interface, which can perform data comparison without complex settings, and presents comparison results in intuitive charts and reports, making it easy for you to understand data differences.
Step One: One-minute Quick Configuration of Comparison Task
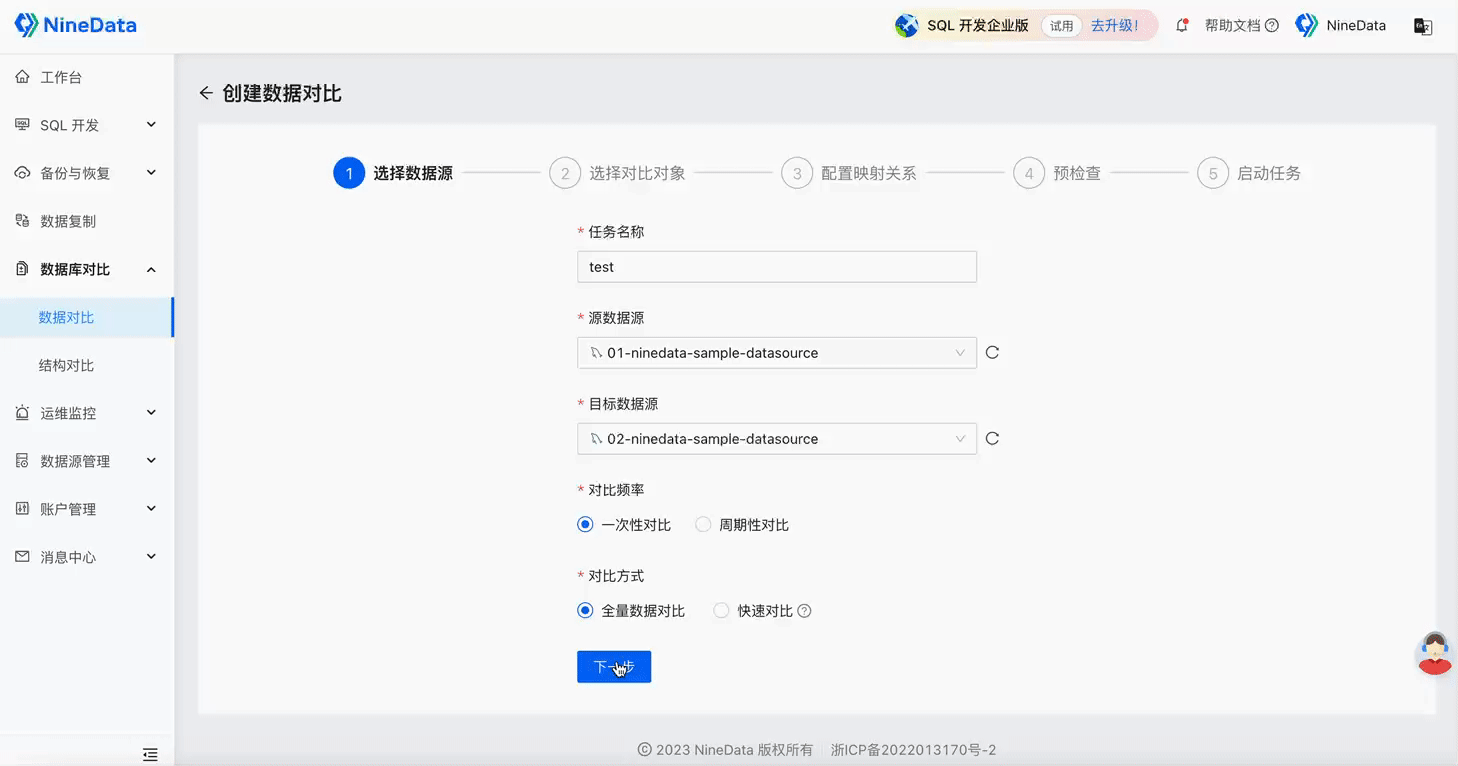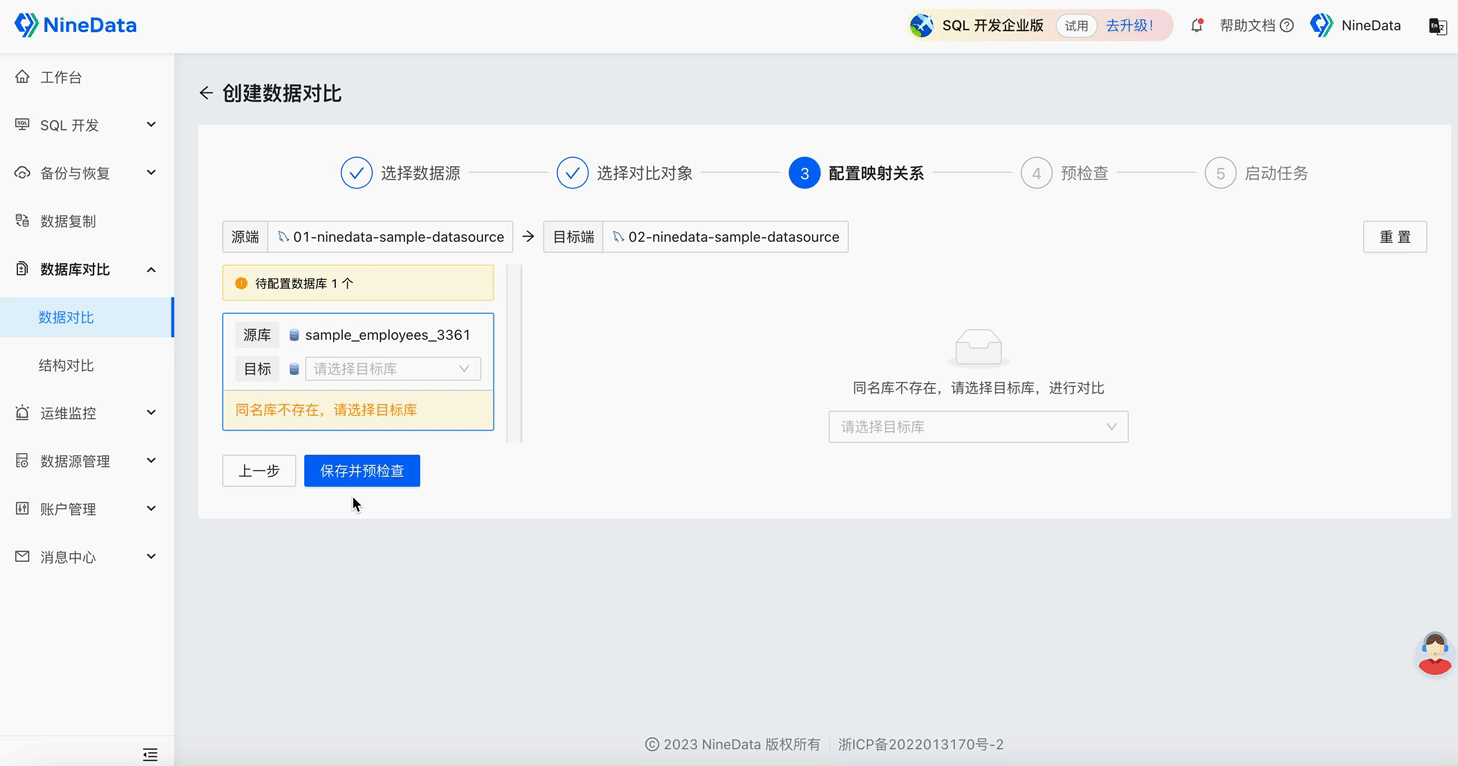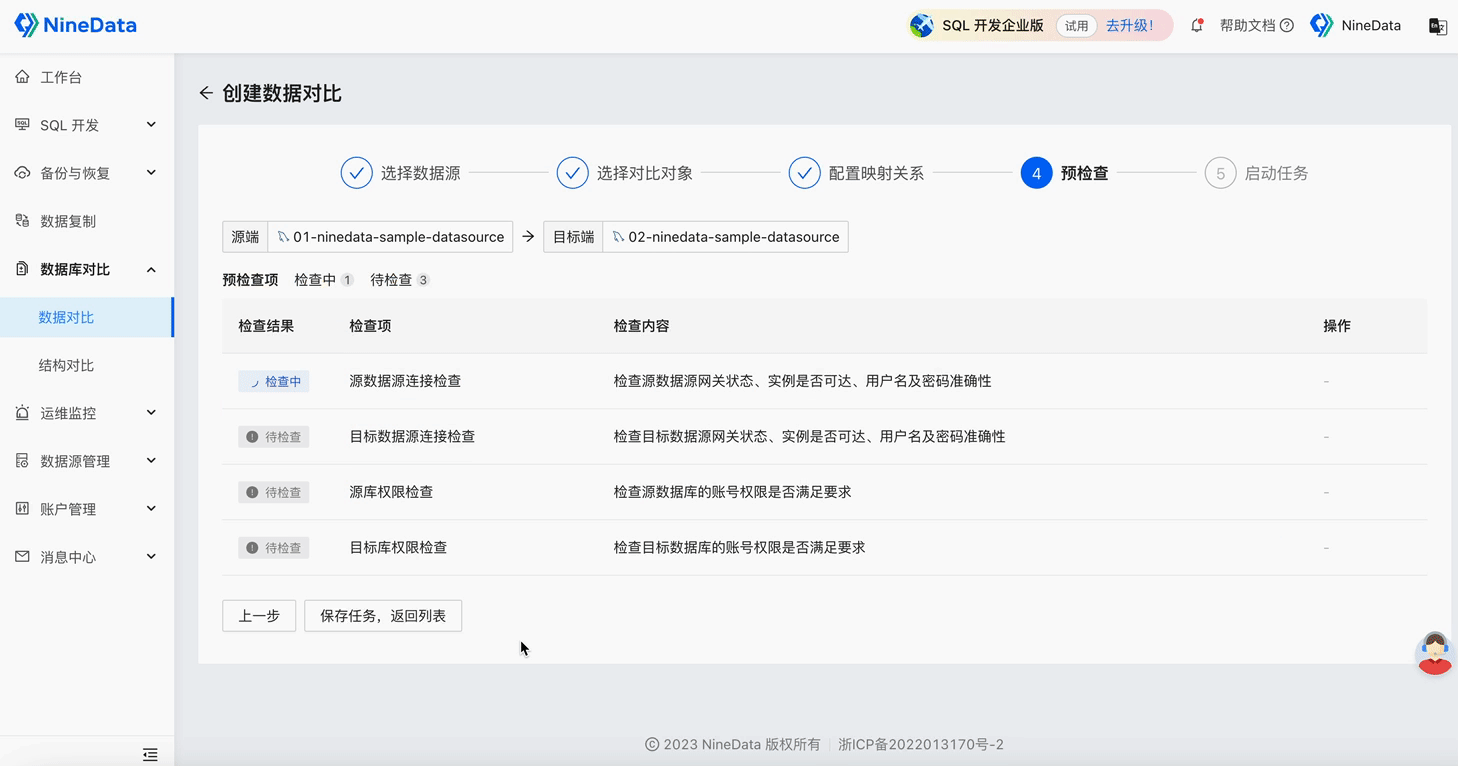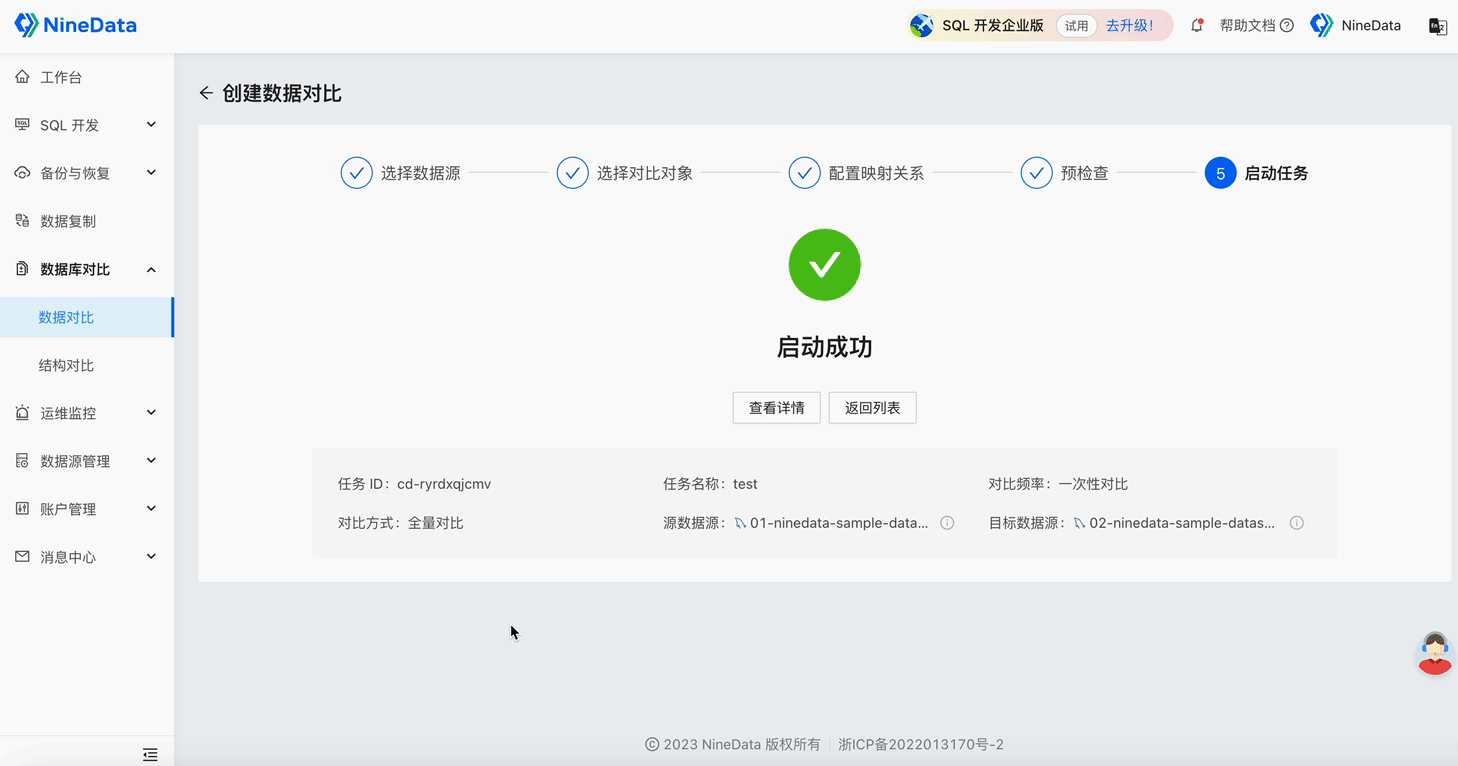
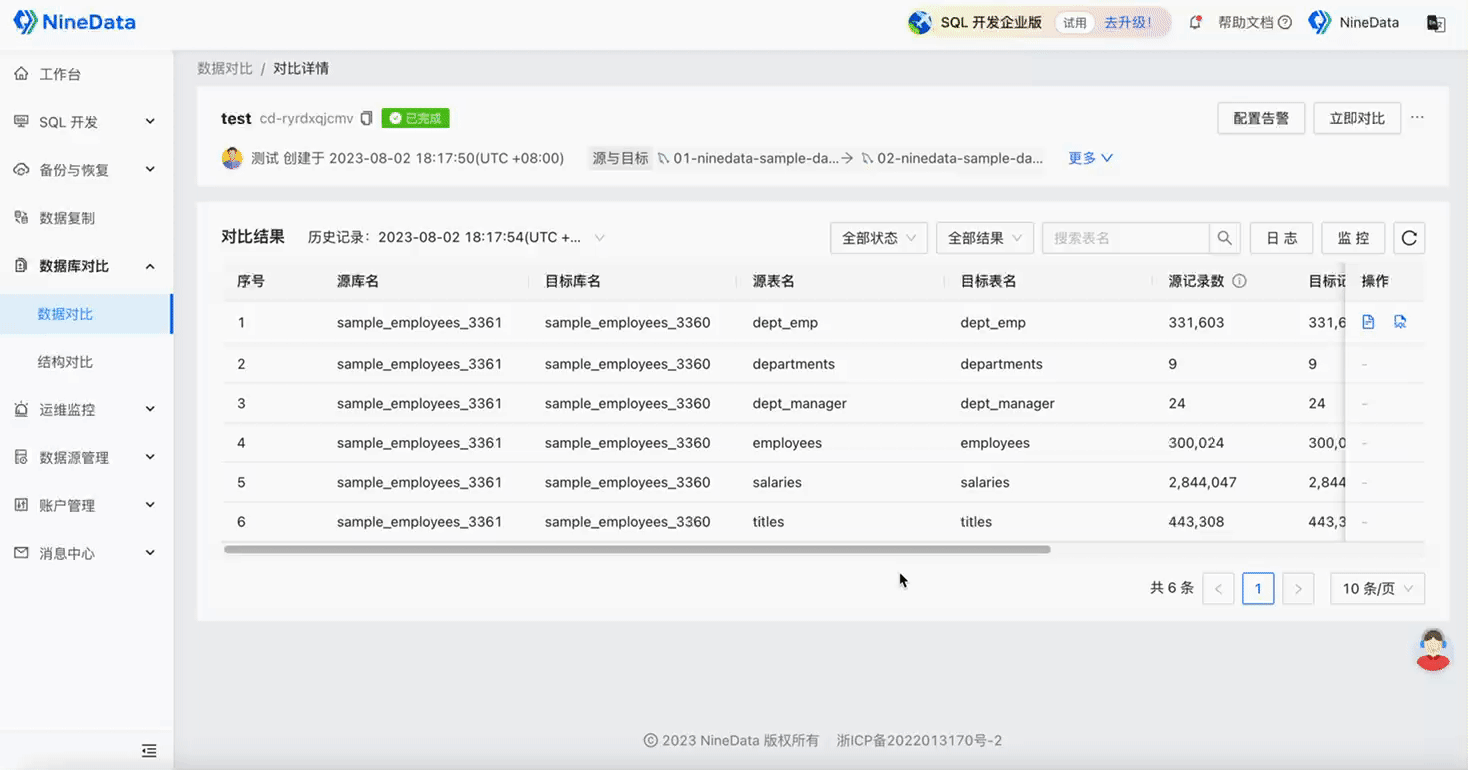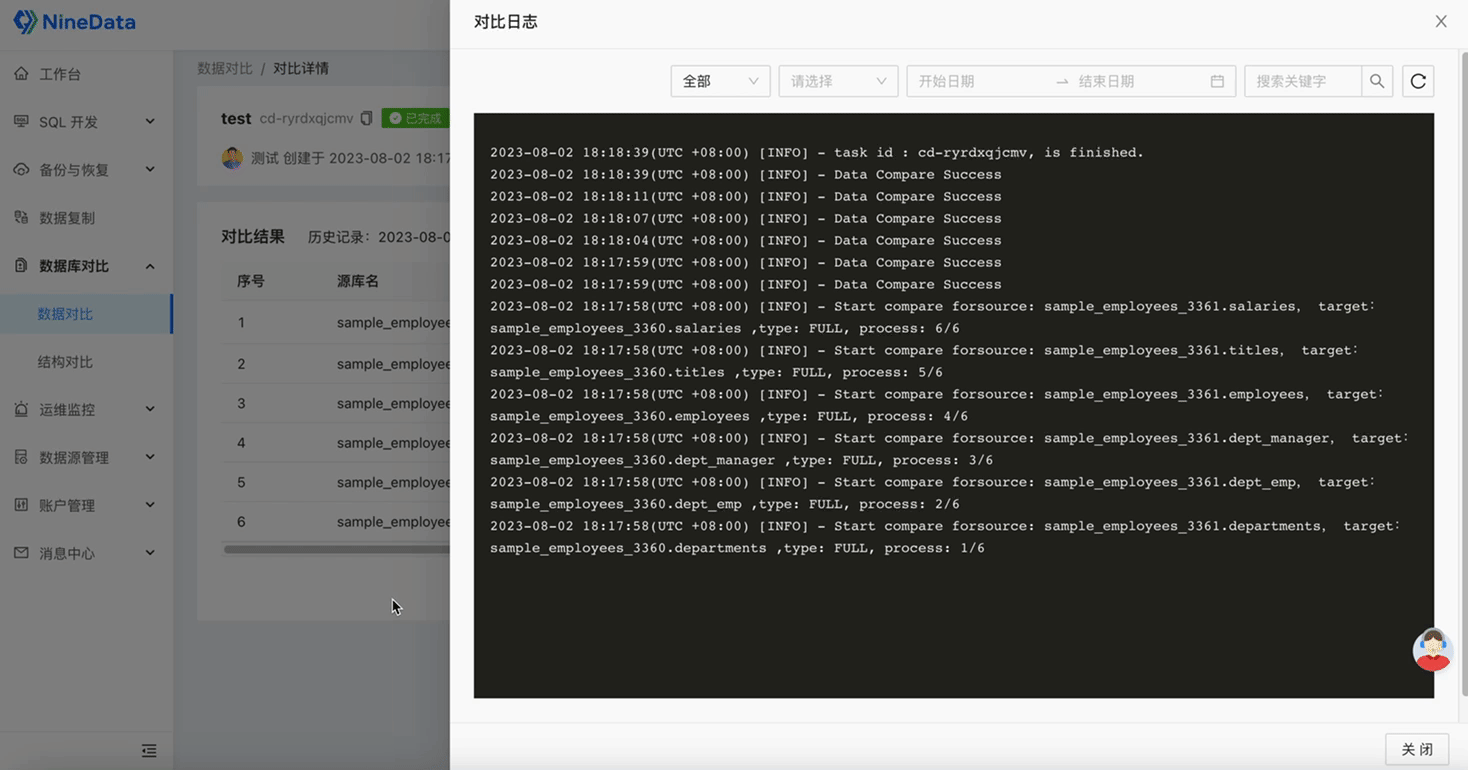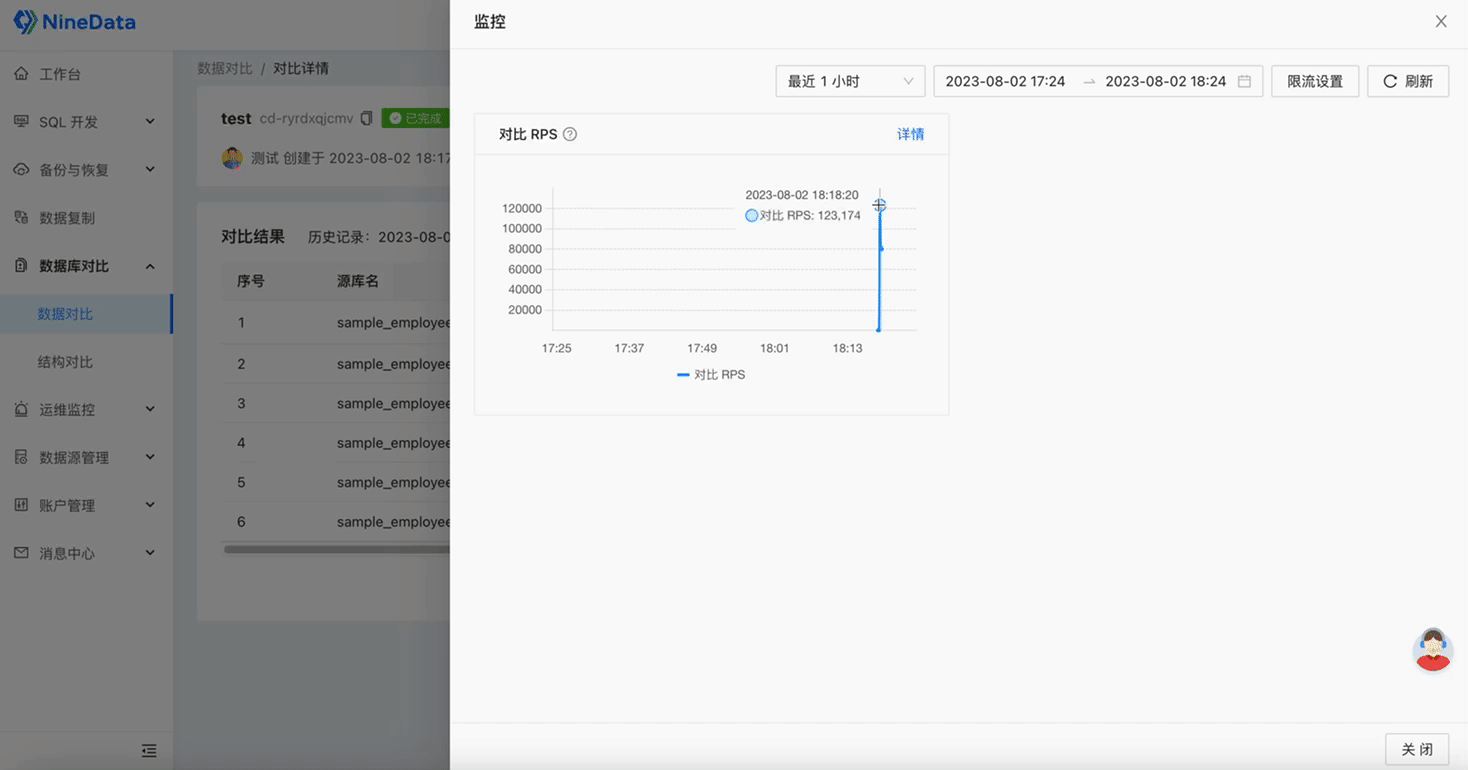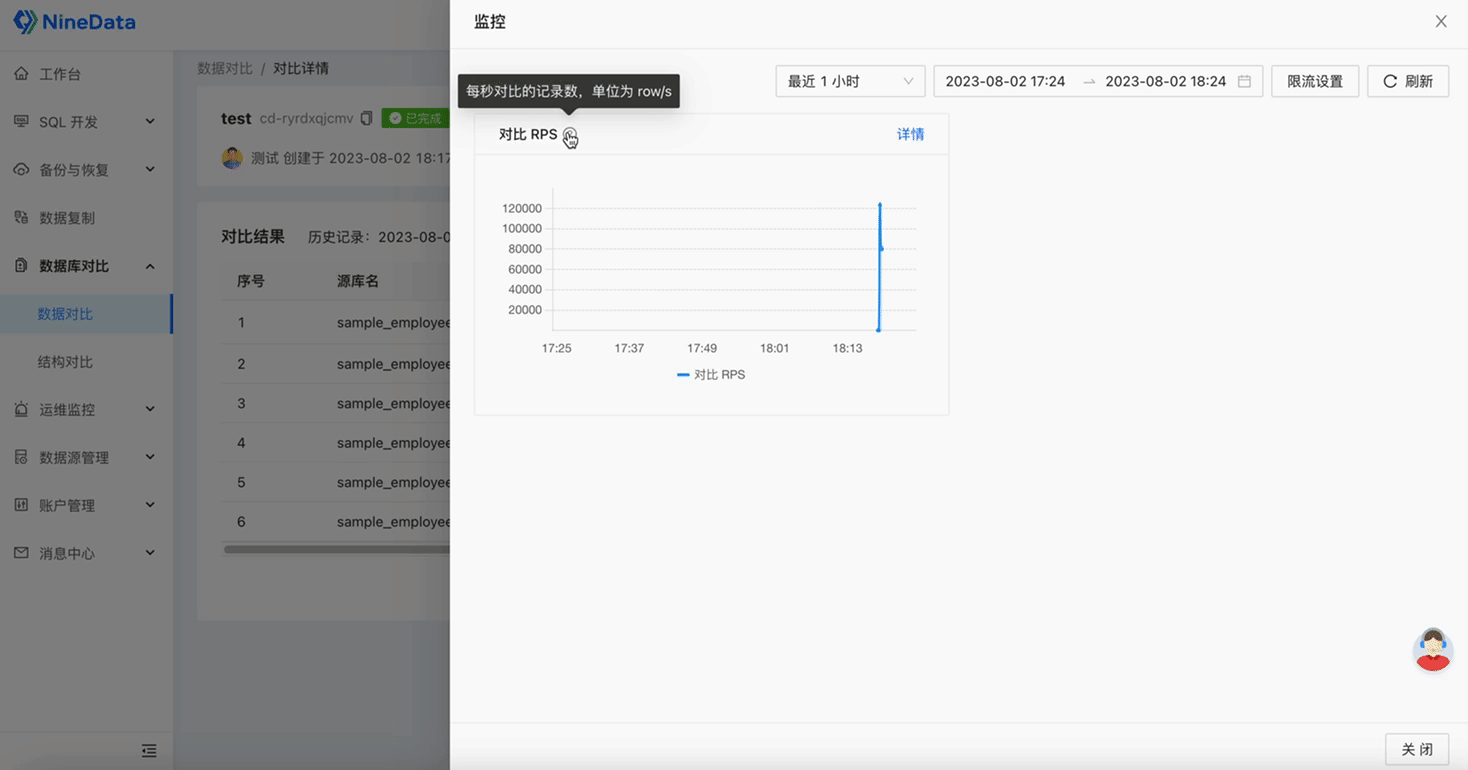
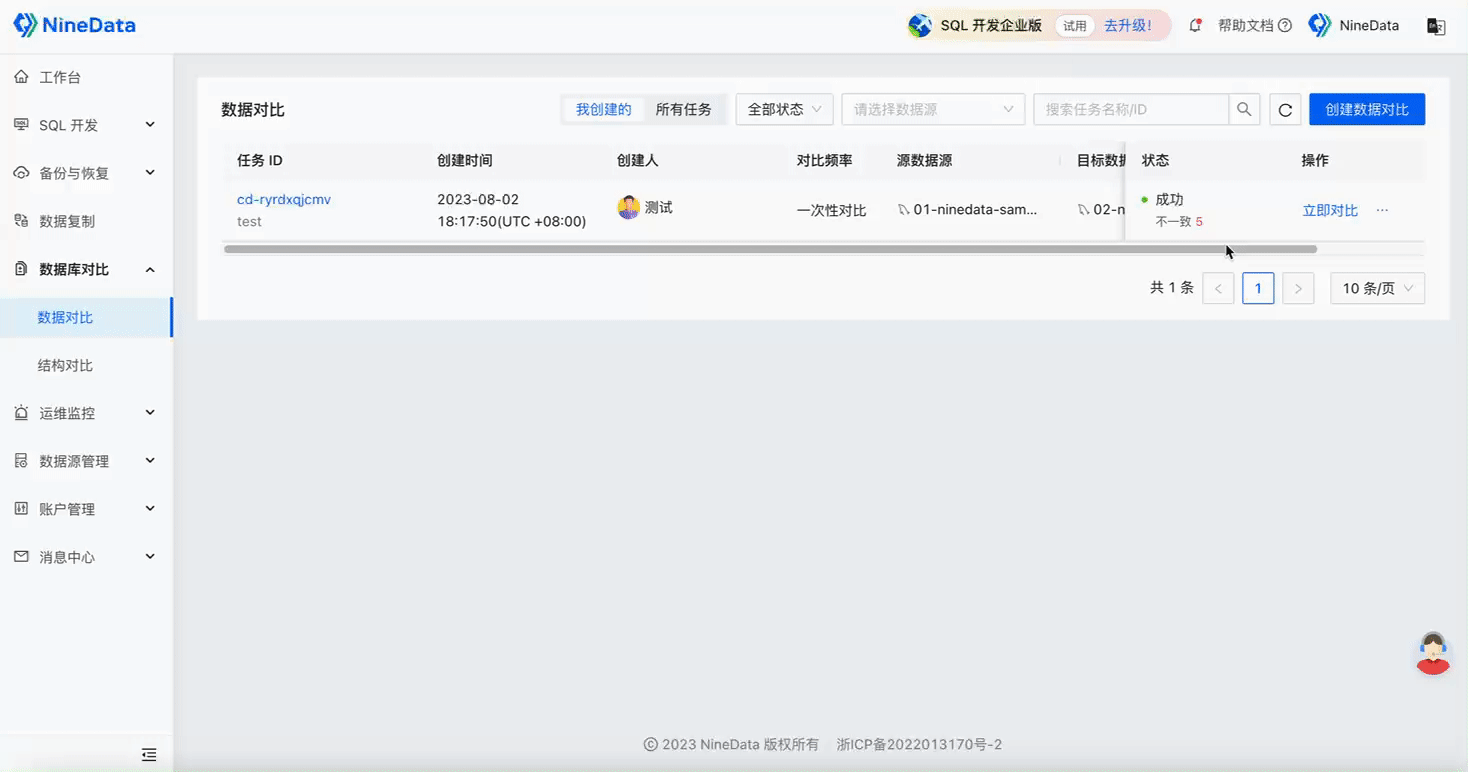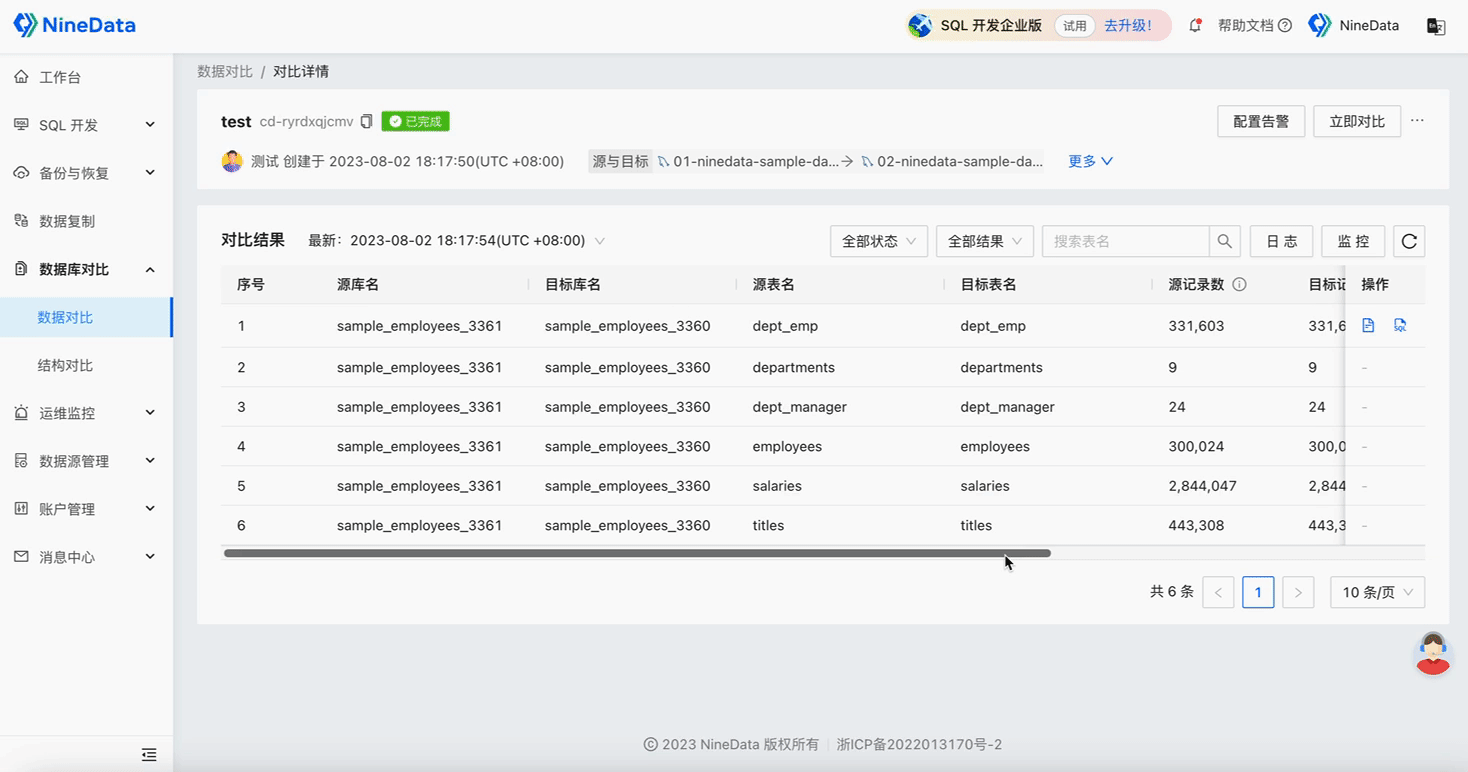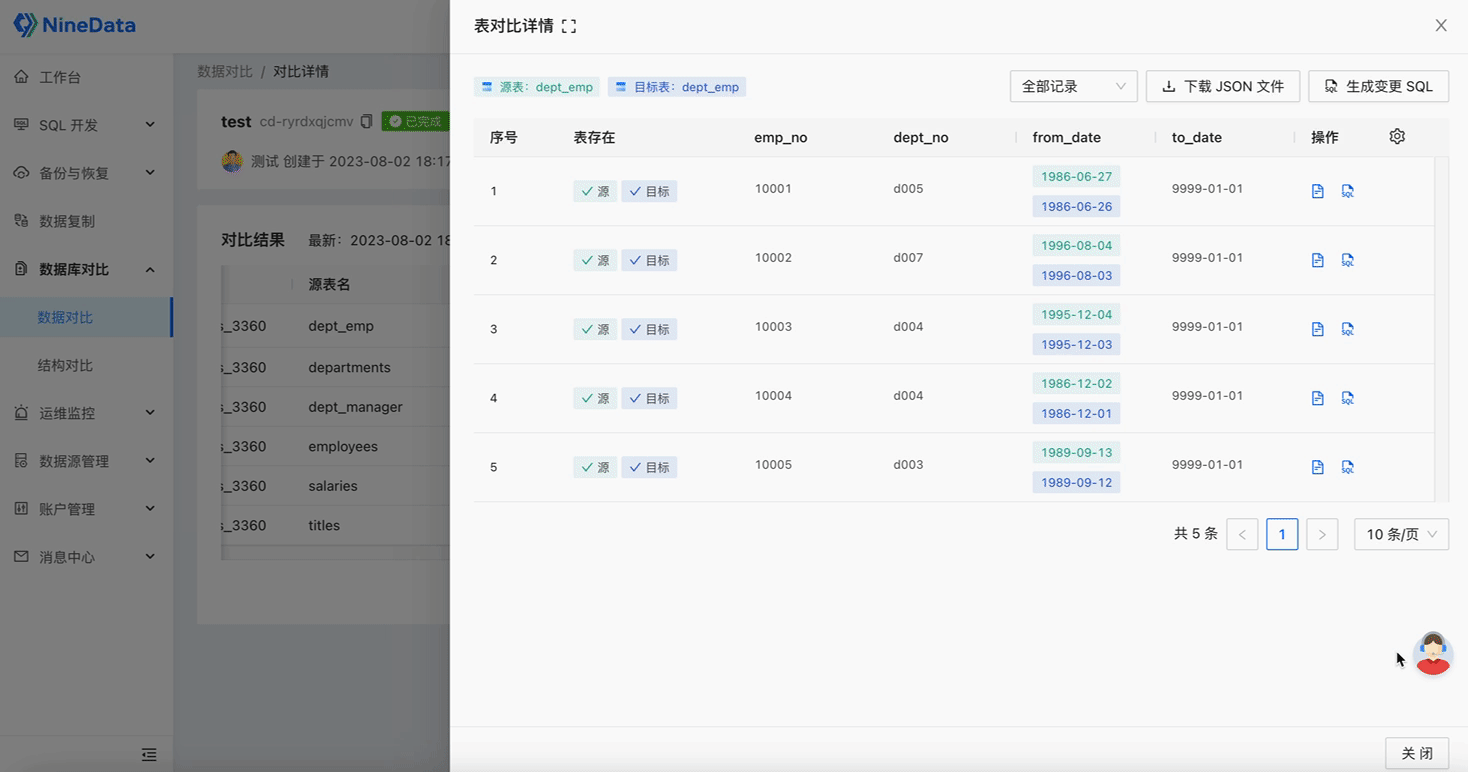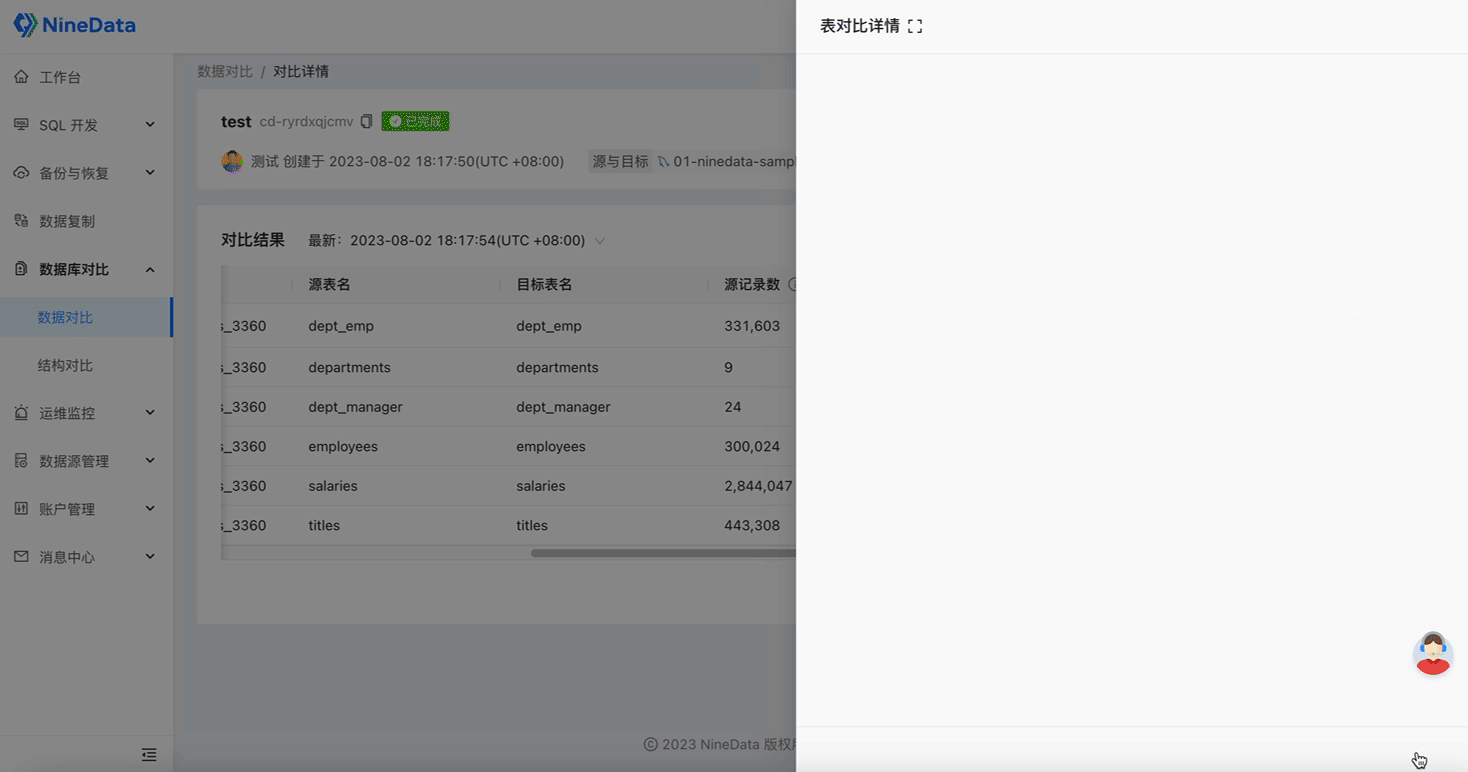
Step Two: View Comparison Results
Data Comparison
Structure Comparison
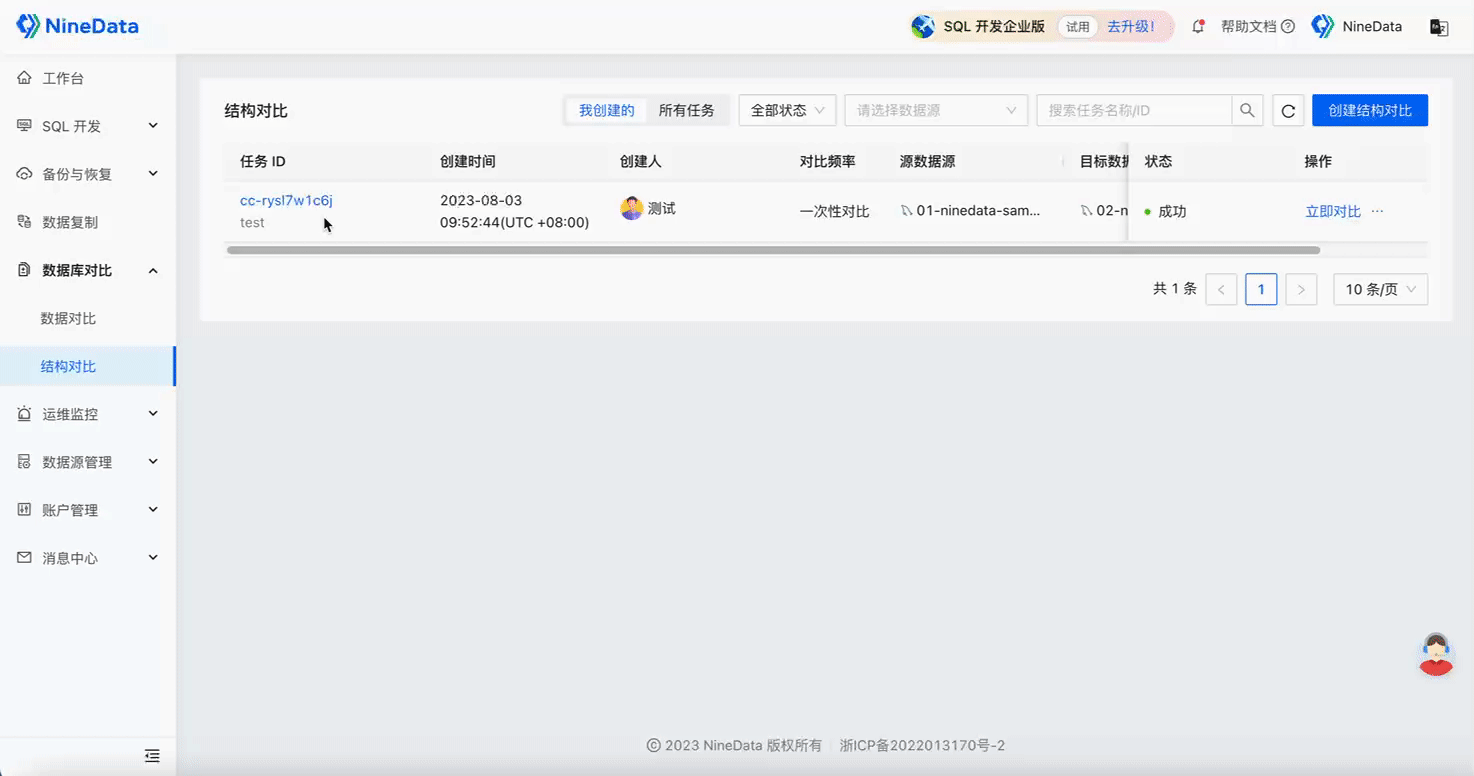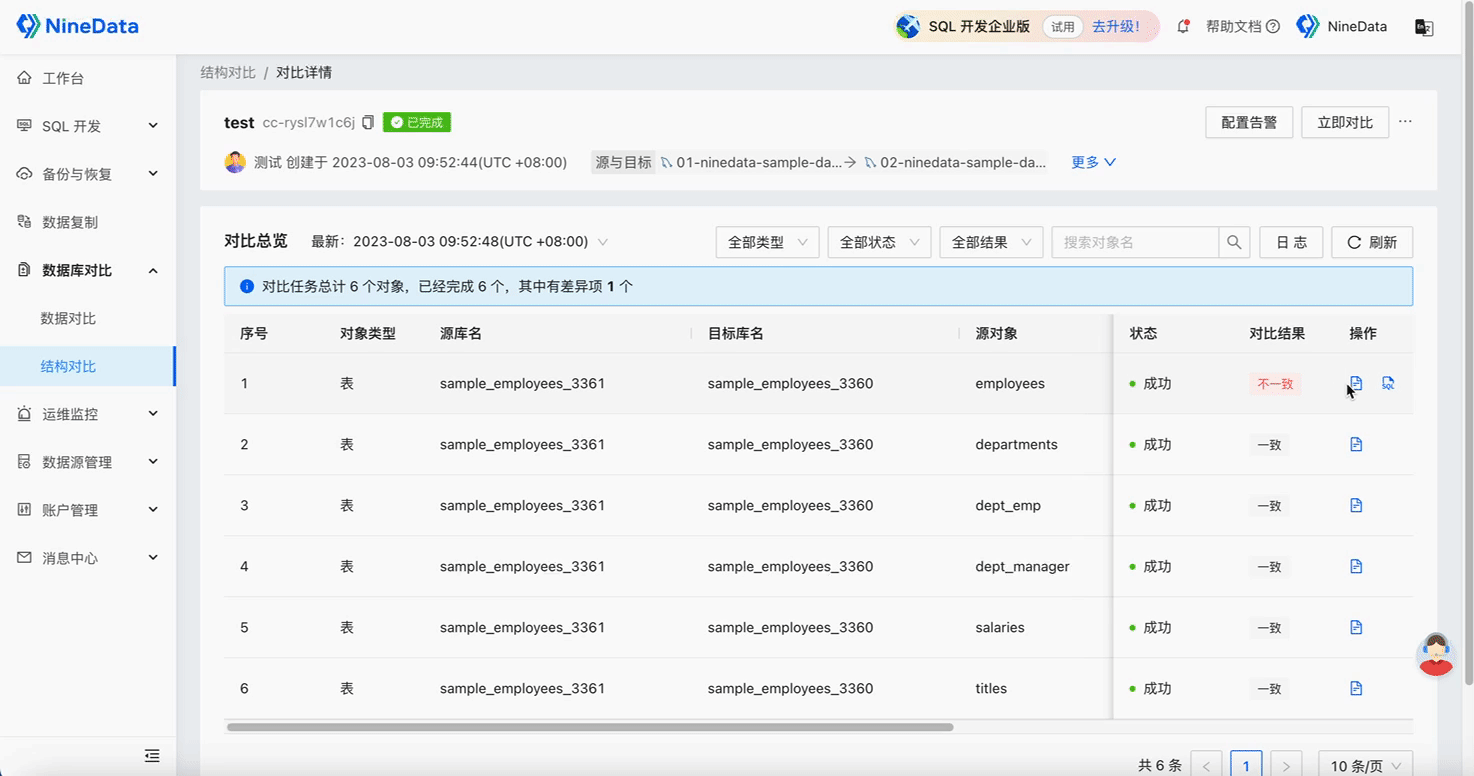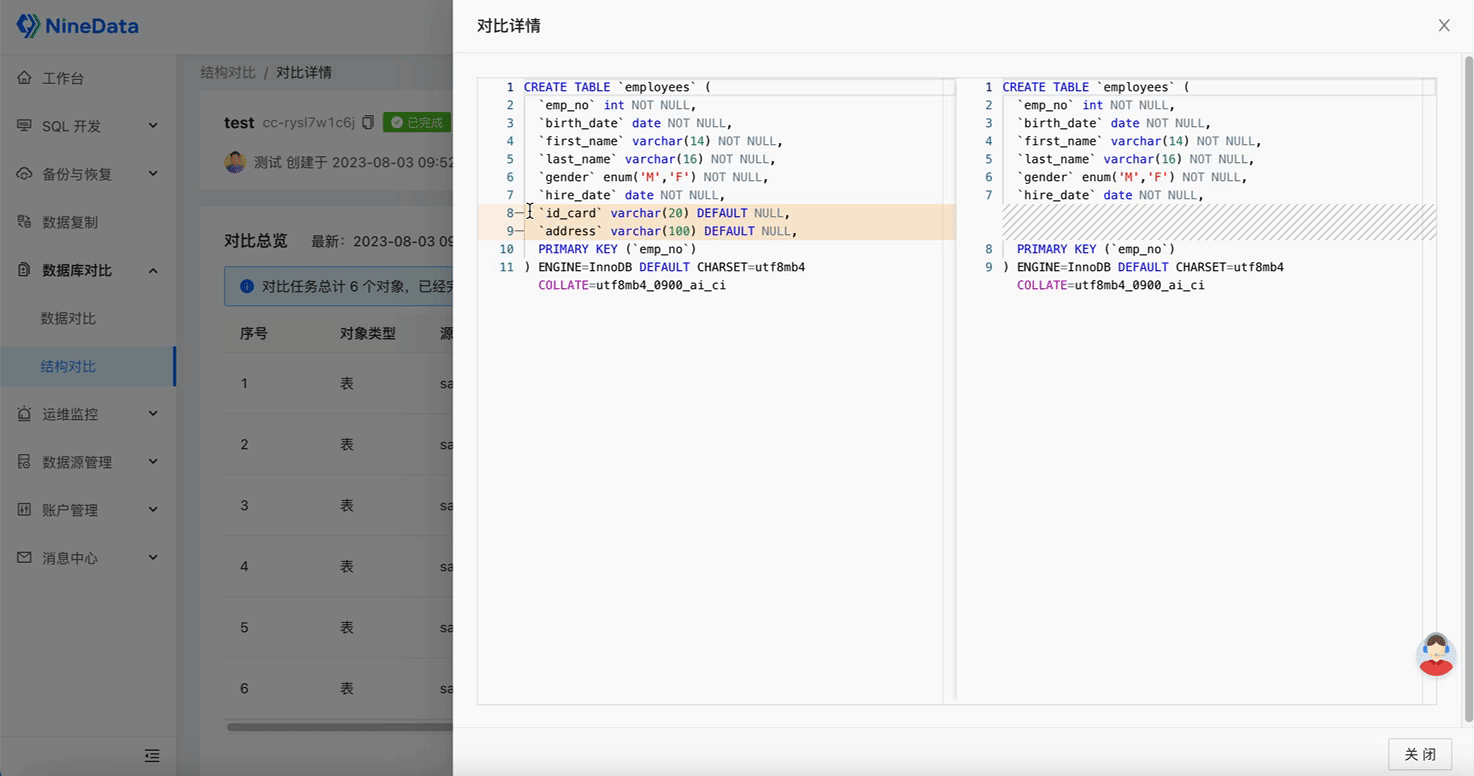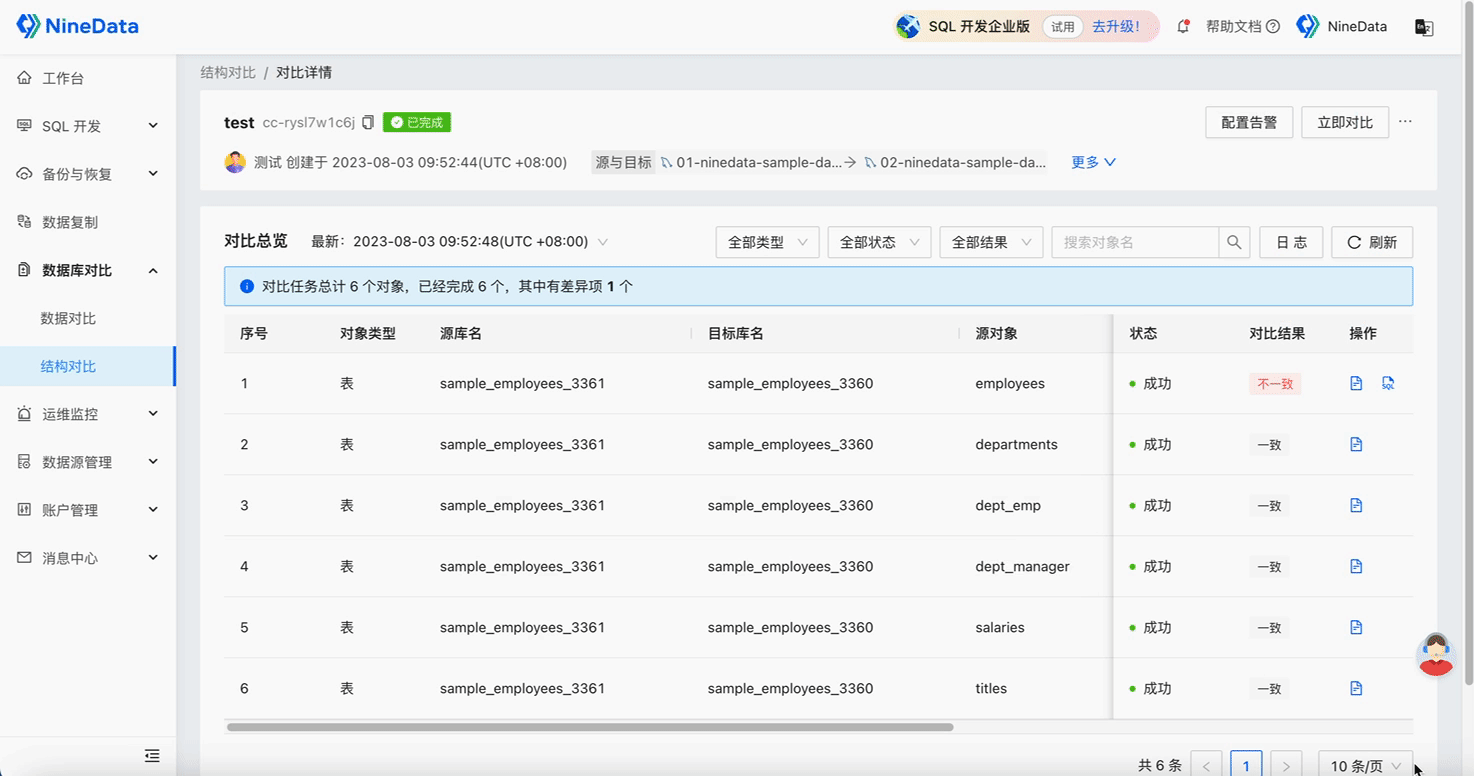
Step Three: Quick Repair of Inconsistent Content
Repair Data
Repair Structure
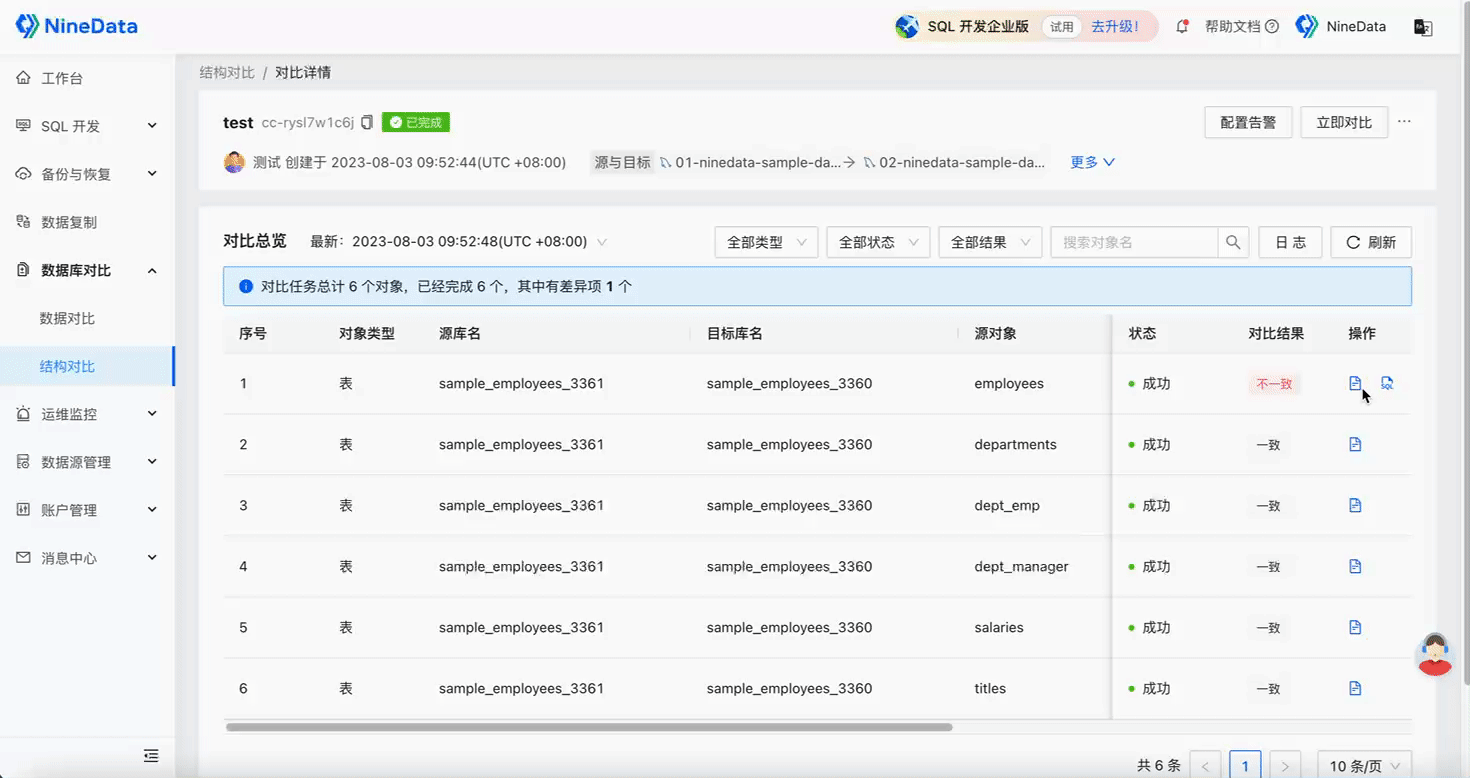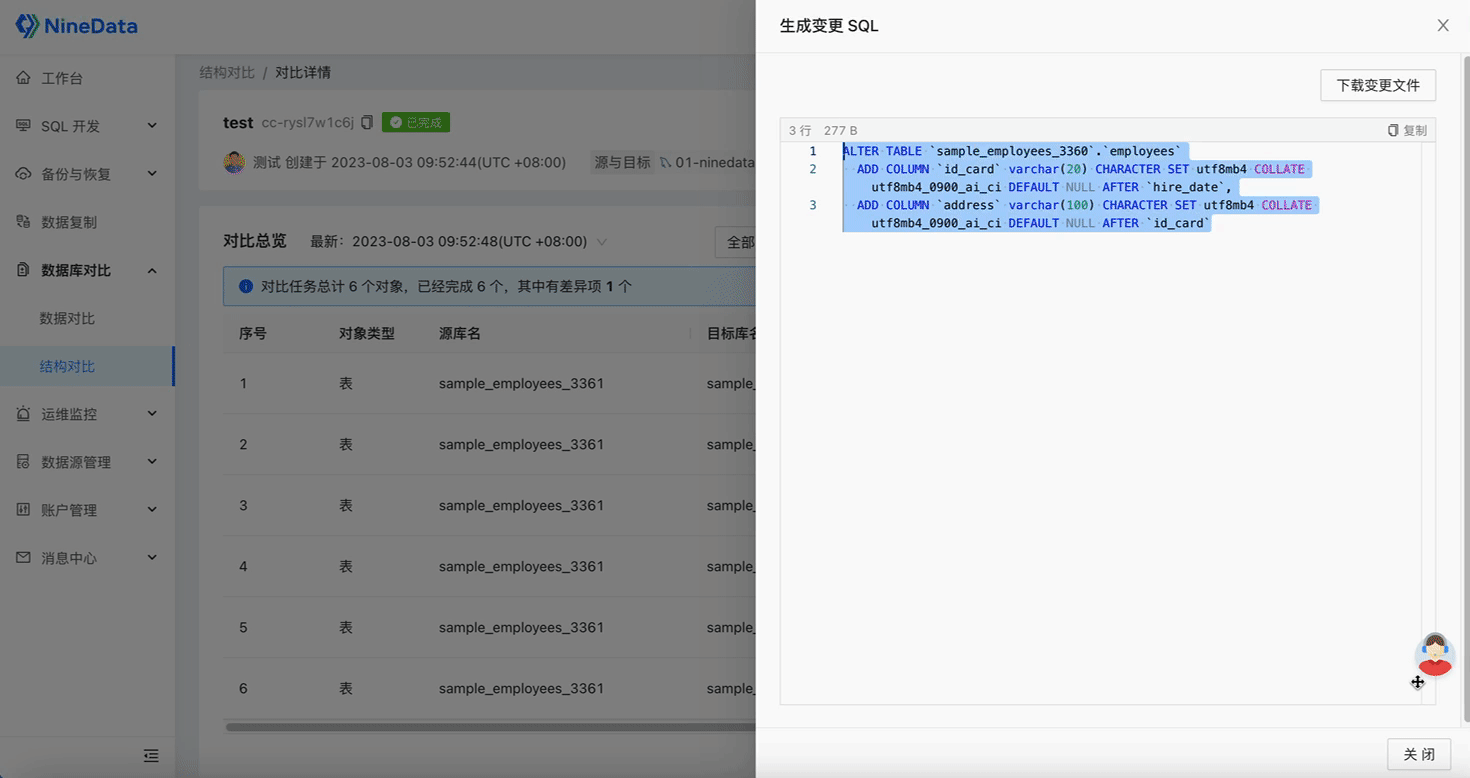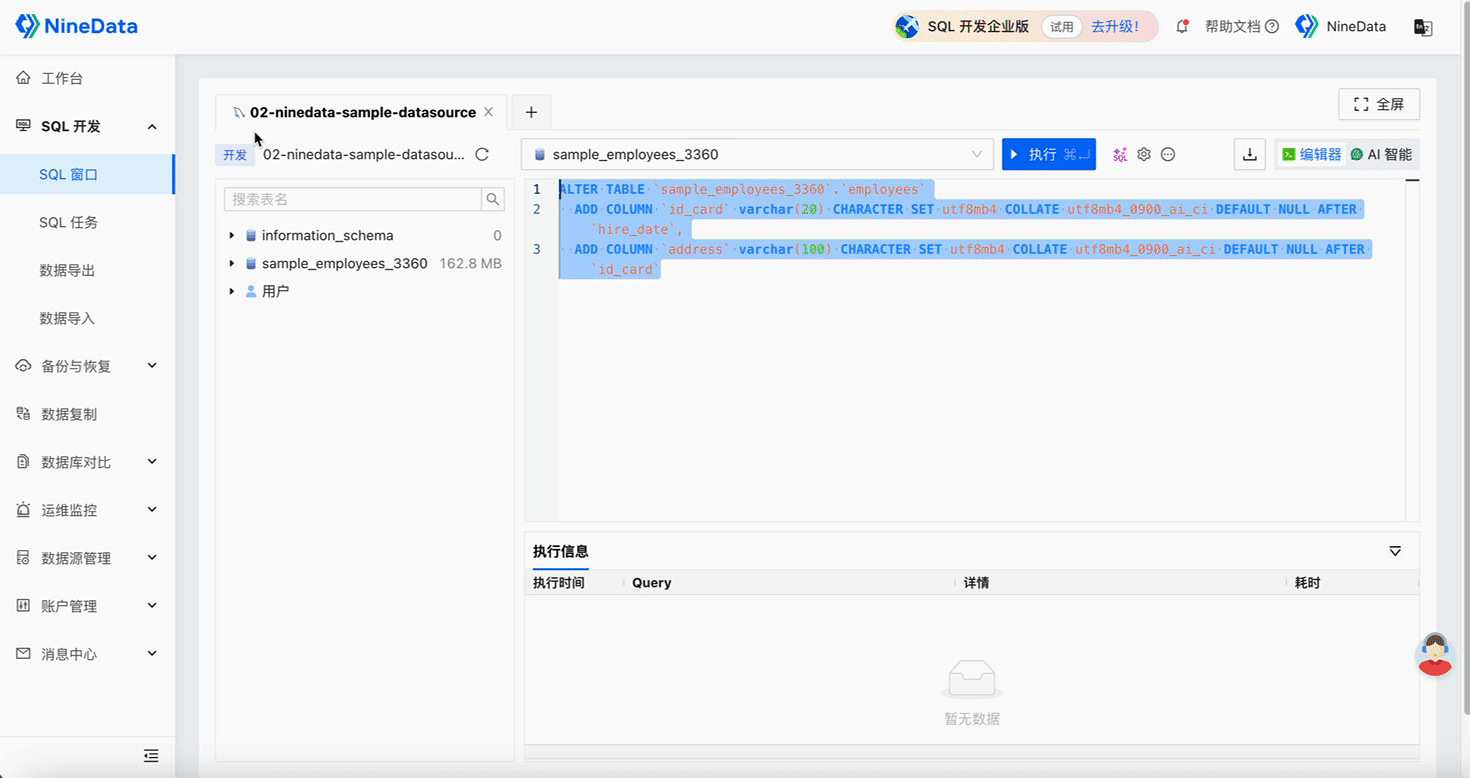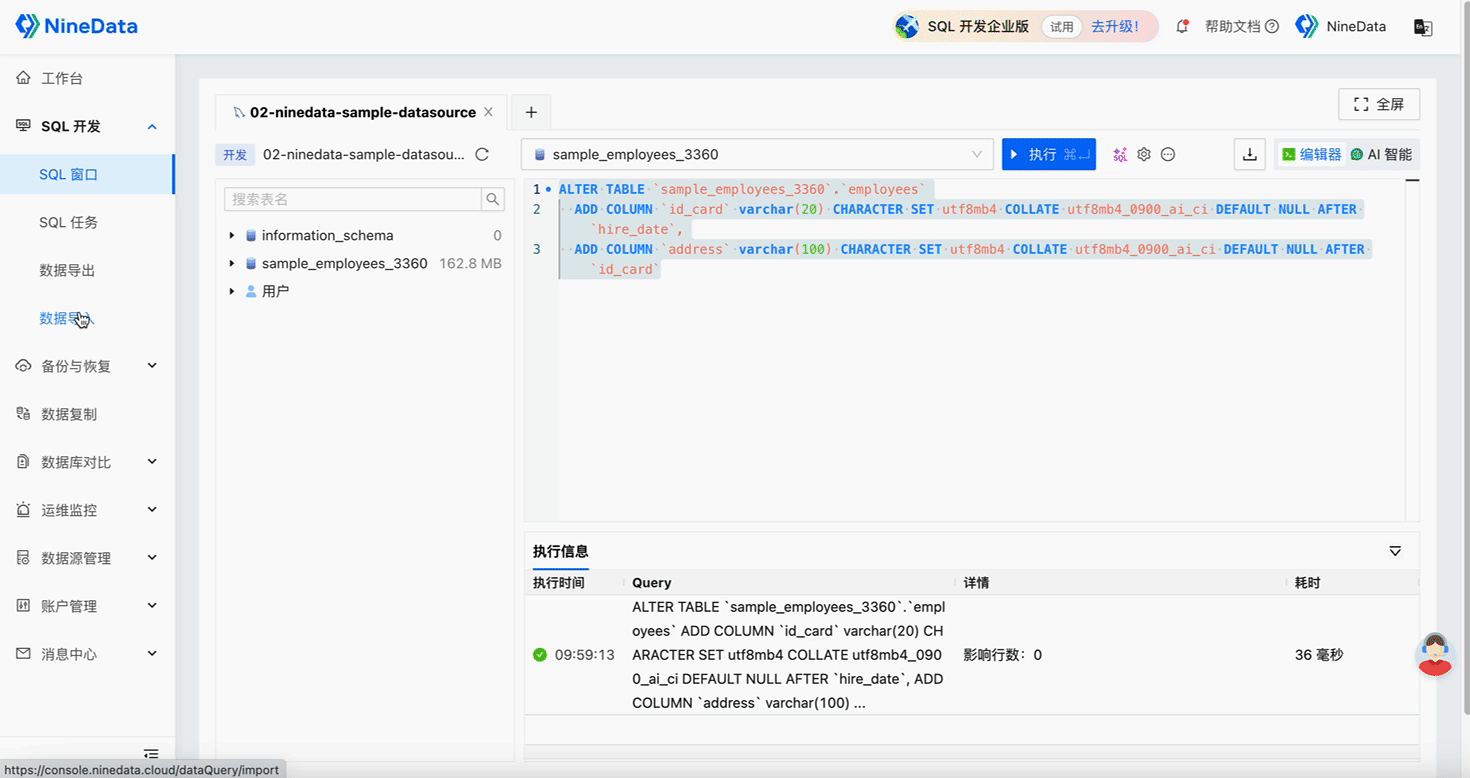
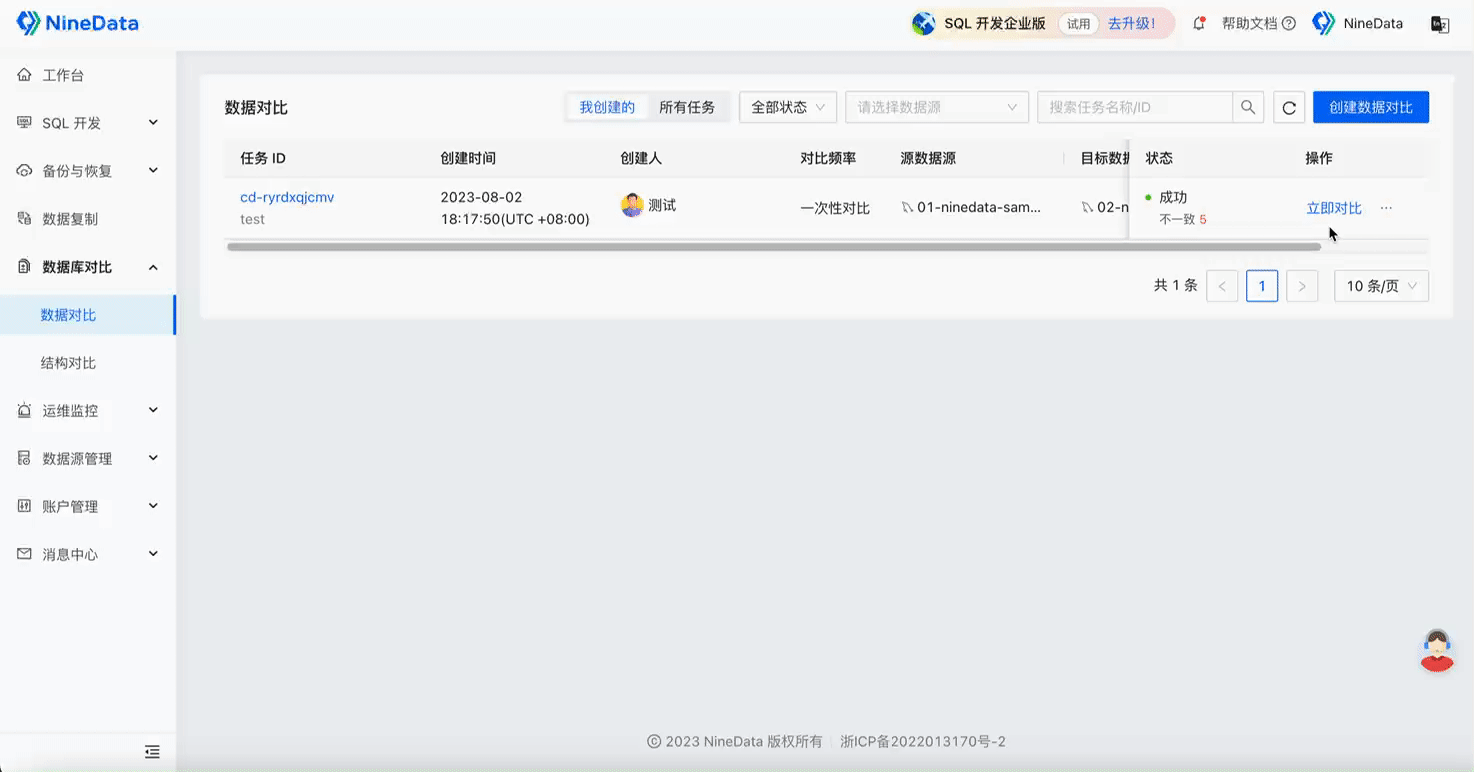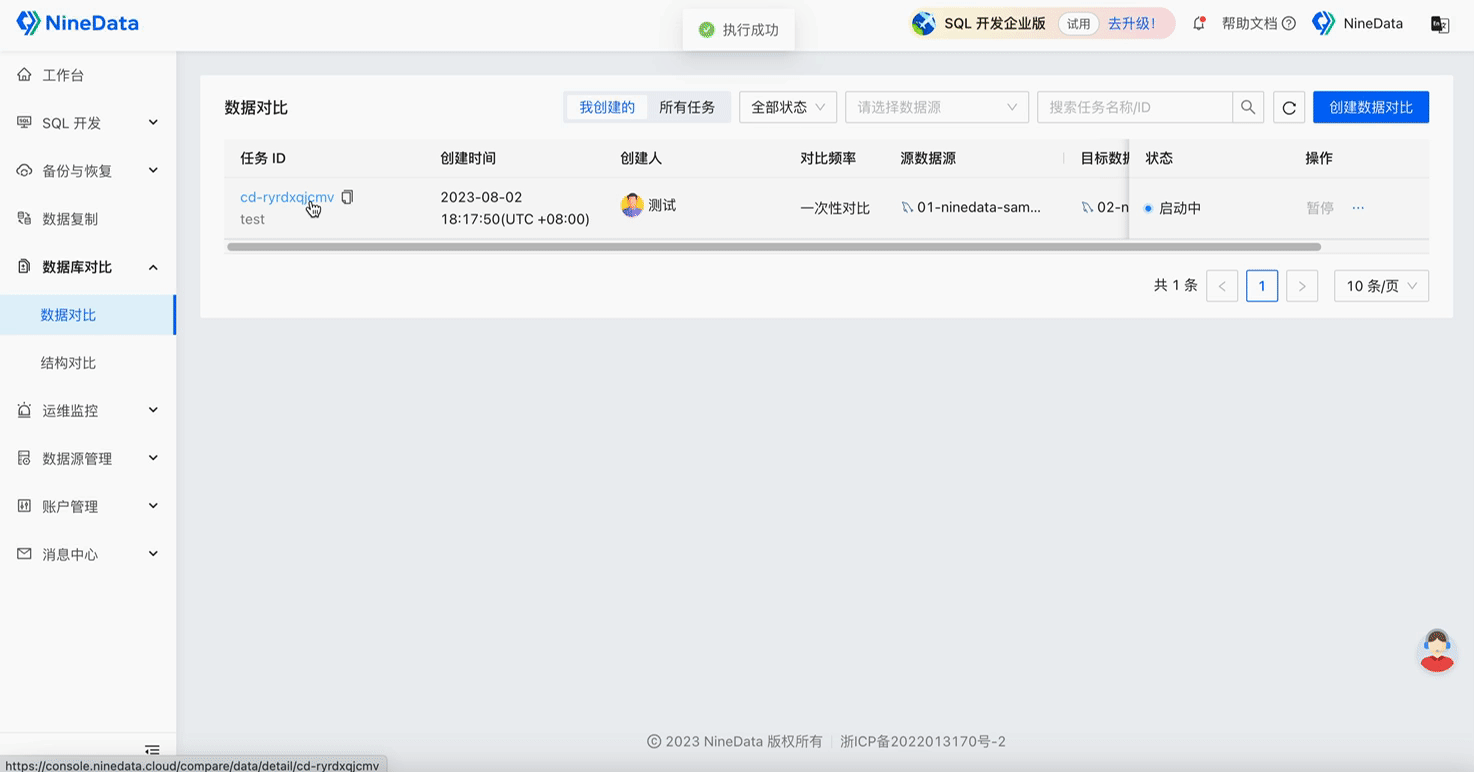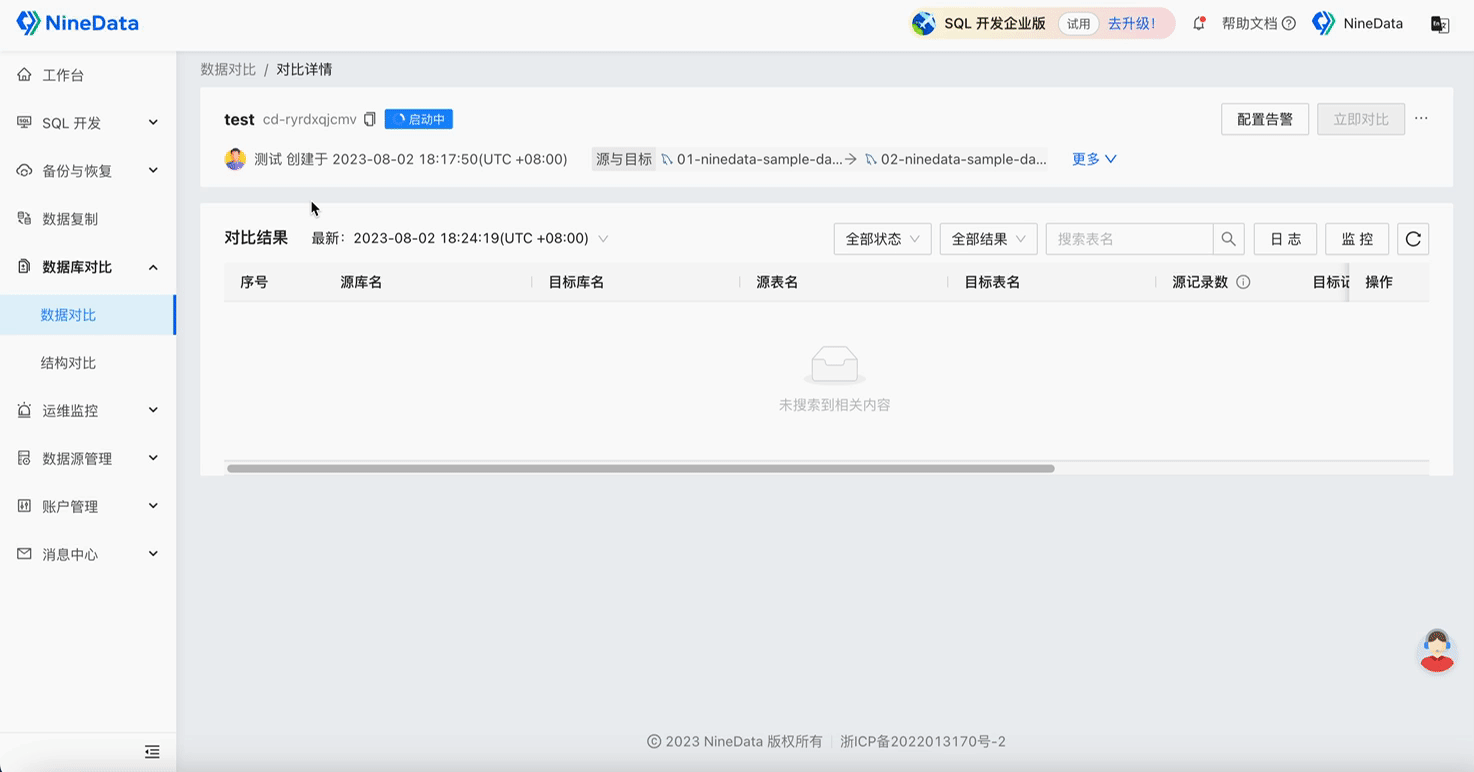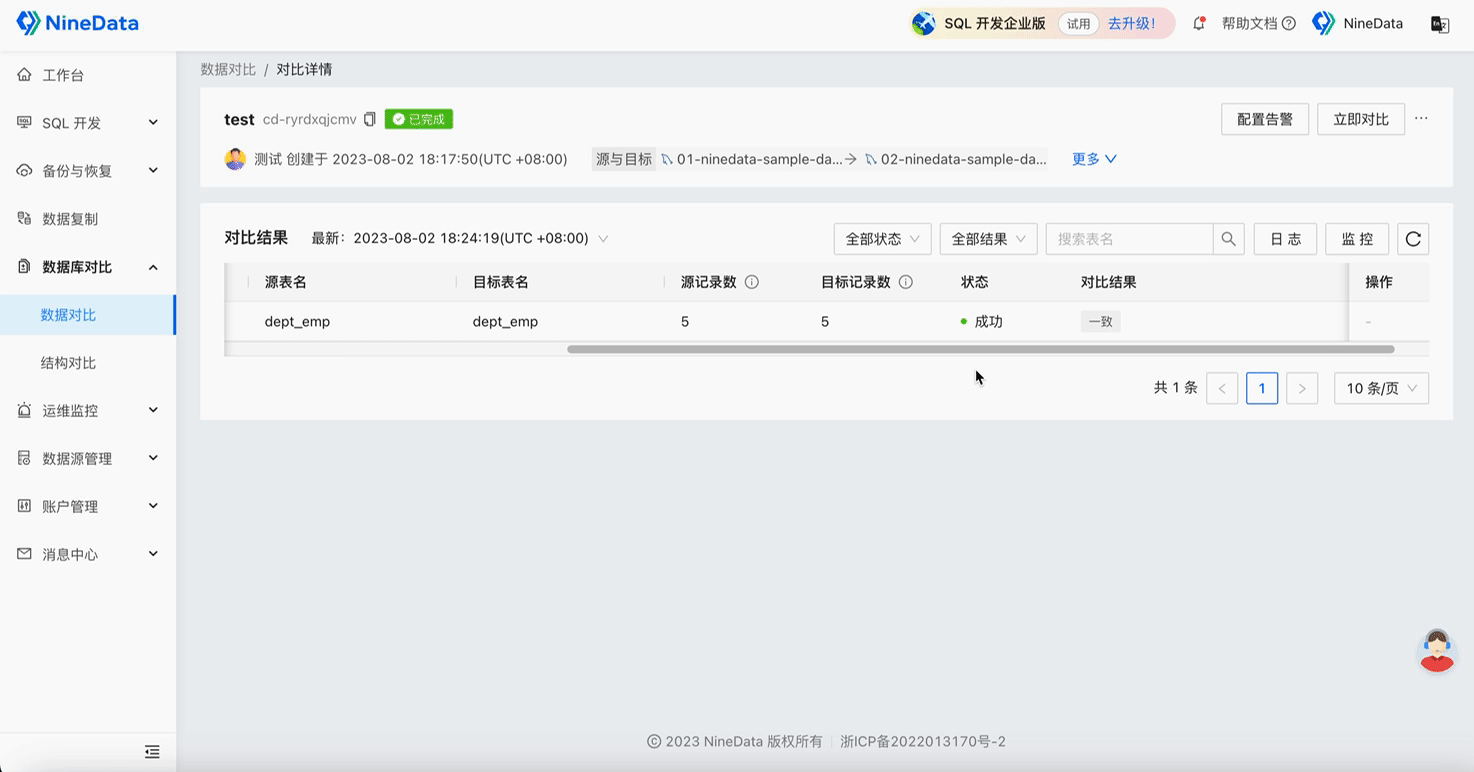
Step Four: Verify Repair Results
Verify Data Repair
Verify Structure Repair
Step Five: View Task Logs and Monitoring Metrics