NineData product architecture
This page explains the overall product architecture and core functional components of NineData.
Architecture overview
NineData uses a distributed, highly reliable, multi-tenant architecture based on cloud-native technology. The following diagram illustrates the major layers and components.
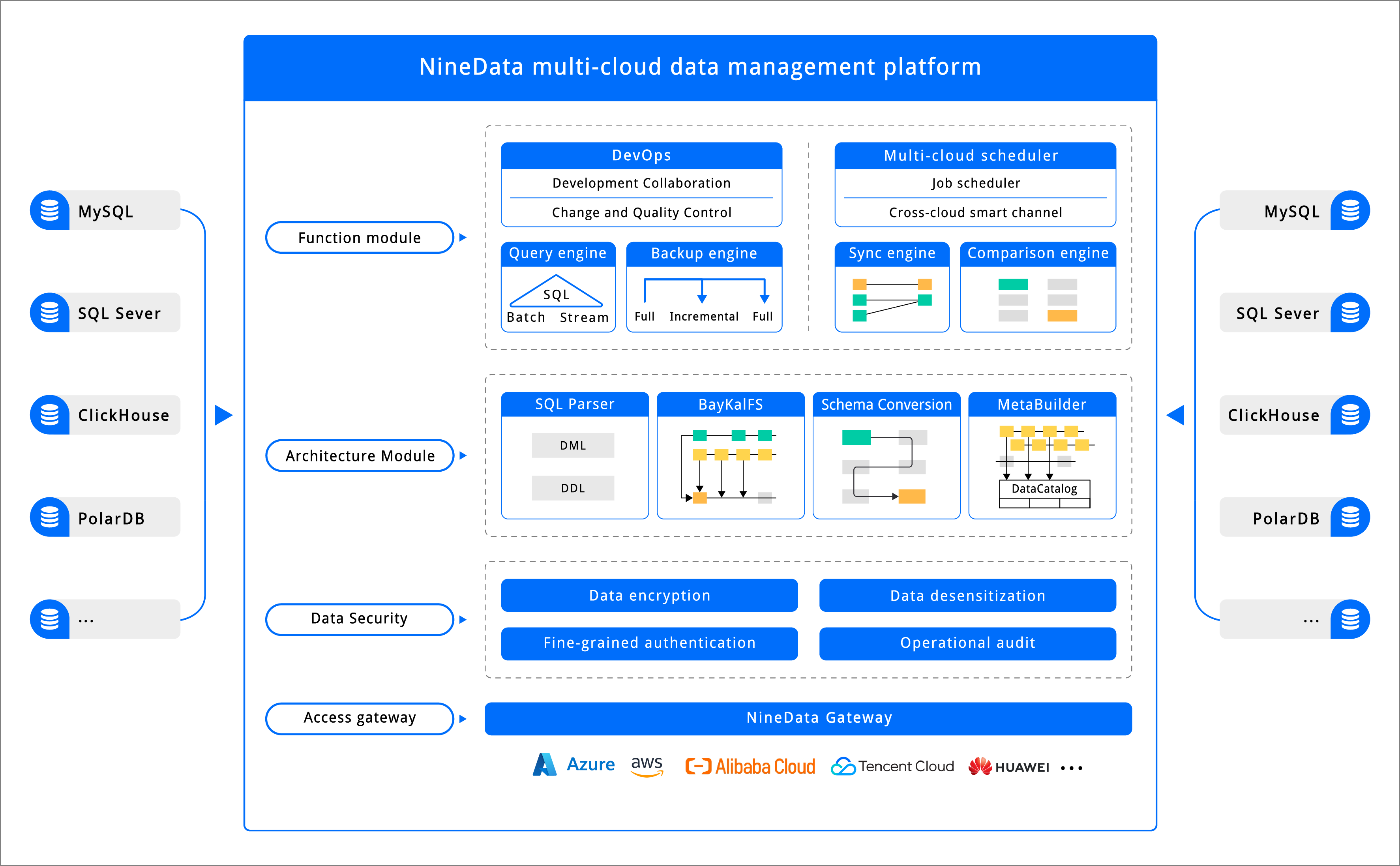
The product architecture contains five layers:
- Access layer: Handles user interaction, task lifecycle management, and data management operations. Users mainly access this layer through the web console.
- Function engine layer: Runs the core data management workloads, including DevOps, query, backup, synchronization, comparison, and scheduling engines. For details about each engine, see Functional Components.
- Core component layer: Provides shared capabilities for the function engines, including log parsing, data conversion, and data storage.
- Data security layer: Protects data across the full lifecycle of data management. Components include fine-grained permission control, sensitive data management and masking, data encryption, and security audit logs.
- Data connection layer: Provides connection access to supported data sources for the upper layers.
Functional Components
| Engines and Components | Description |
|---|---|
| DevOps and query engines | DevOps :
|
| Query engine : Receive SQL requests sent by users. | |
| Scheduling engine | Responsible for overall task and resource scheduling across the platform.
|
| Backup engine | Runs backup and recovery tasks and monitors task status. |
| Synchronization engine | Runs data replication tasks, schedules dependent tasks in pipelines based on the selected replication type, and monitors task status. |
| Comparison engine | Runs schema and data comparison tasks between two data sources and monitors task status. |
| SQL Parser | SQL parsing module. Analyzes SQL statements and logs across the platform, and helps engines complete tasks such as data reading and secure data access. |
| Sensitive data management | Provides sensitive data metadata and masking functions for the query, backup, synchronization, and comparison engines. Dozens of sensitive data recognition algorithms are built in. When enabled, NineData scans and marks sensitive fields in the data source. |