复制分库分表
NineData 支持 MySQL 分库分表的数据复制,可从多个分库分表中将数据复制到其他的分库分表,或聚合到另一个 MySQL 实例中。
前提条件
已将源数据源和目标数据源添加至 NineData。如何添加,请参见添加数据源。
使用限制
- 创建库表分组时,库中的物理分表必须真实存在,并能使用提取表达式提取到。
- 数据复制功能仅针对数据源中的用户数据库,系统库不会被复制。例如:MySQL 类型数据源中的
information_schema、mysql、performance_schema、sys库不会被复制。 - 源数据源的账号必须拥有复制对象的
SELECT权限(结构复制、全量复制)、SHOW VIEW权限(视图复制)以及REPLICATION CLIENT、REPLICATION SLAVE权限(增量复制),目标数据源的账号必须拥有DML、DDL权限。 - 执行数据同步前需评估源数据源和目标数据源的性能,同时建议业务低峰期执行数据同步。否则全量数据初始化时将占用源数据源和目标数据源一定的读写资源,导致数据库负载上升。
- 仅支持表对象的复制,其他对象会被自动忽略。
- 需要确保同步对象中的每张表都有分区键、主键或唯一约束,并且执行分表路由算法后,路由到同一目标分表的两行数据的主键或唯一约束不能相同,否则新写入的数据将覆盖旧数据。
步骤一:创建库表分组
您需要将源数据源中的分库分表添加到 NineData 的库表分组中,以实现分库分表的迁移。如果您的复制目标也是分库分表,则也需要执行当前步骤创建目标库的库表分组 。
登录 NineData 控制台。
在左侧导航栏,单击数据源管理 > 数据源。
单击库分组页签,单击页面中的创建库分组。
根据下表配置表单,并单击创建库分组。
参数 说明 库分组名称 输入库分组的名称,仅支持英文字符、数字和下划线,以英文字符开头。为了方便后续使用和管理,请尽量使用有意义的名称。 描述(可选) 输入针对该库分组的业务描述。 环境 选择您的业务所属的环境名称,您将根据该环境筛选数据源。 库 单击添加数据源,选择需要加入到分组中的数据源,支持多选、全选和反选操作,同时支持输入数据源名称进行搜索,单击确定后,还需要选择具体的分库。 页面自动跳转至分组详情,单击创建表分组。
根据下表配置表单,并单击创建表分组。
参数 说明 表分组名称 输入表分组的名称,仅支持英文字符、数字和下划线,以英文字符开头。为了方便后续使用和管理,请尽量使用有意义的名称。 方式 支持手动添加和表达式添加两种。 表达式添加 方式选择表达式添加时需要配置,输入表达式并单击自动提取后,系统将根据您提供的表达式,自动遍历并提取目标库中所有符合要求的表。 路由算法(可选) 方式选择表达式添加时可配置,根据您应用中配置的路由算法配置该参数,可以根据路由快速解析需要访问的表。路由算法的配置方式,请参见本文附录。 库 方式选择手动添加时需要配置,单击添加数据源,选择需要加入到分组中的数据源,支持多选、全选和反选操作,同时支持输入数据源名称进行搜索,单击确定后,还需要选择具体的库和表,根据数据源不同,可能还需要选择具体的 Schema。
步骤二:创建数据复制任务
NineData 数据复制产品已商业化,您仍然可以保有 10 条复制任务免费使用,注意事项如下:
- 10 条复制任务中可以包含 1 条增量复制任务,规格为 Micro。
- 状态为已终止的任务不算在 10 条任务的限制内,如果您已经创建了 10 条复制任务,还想要继续创建,可以先终止之前的复制任务,然后再创建新任务。
- 创建复制任务时,仅可选择您已购买的复制规格,未购买的规格将以灰度显示,无法选择。如需购买,请通过页面右下角的客服图标联系我们。
登录 NineData 控制台。
在左侧导航栏单击数据复制。
在数据复制页面,单击右上角的创建复制。
在数据源与目标页签,按照下表进行配置,并单击下一步。
参数 说明 任务名称 输入数据同步任务的名称,为了方便后续查找和管理,请尽量使用有意义的名称。最多支持 64 个字符。 源数据源 选择同步对象所在的库分组。 目标数据源 接收同步对象的数据源或库分组。 复制类型 选择需要复制到目标数据源或库表分组的内容。 - 结构复制:只同步源库表 分组的结构,不同步数据。
- 全量复制:同步源库表分组的所有对象和数据,即全量数据复制。右侧的开关为周期性全量复制的开关,更多信息,请参见周期性全量复制。
目标库同名对象处理策略(选中结构复制时需要选择) - 预检查报错并停止任务:预检查阶段检测到同名表时,停止任务。
- 跳过并继续任务:预检查阶段检测到同名表时,发送提示并继续任务。 结构复制时,忽略该同名表。如果您同时进行了数据复制,则数据会在同名表中追加,而不会覆盖原有数据。
- 删除对象并重建:预检查阶段检测到同名表时,发送提示并继续任务。结构复制时,删除目标库同名表,并基于源库重新复制表结构。如果您同时进行了数据复制,则数据会在表结构复制完成后写入。
- 保留结构并清空数据,再覆盖写入(同时进行结构和数据复制时可选):预检查阶段检测到同名表时,发送提示并继续任务。结构复制时在目标库保留该表结构,并在数据复制开始时清空同名表中的数据,然后重新从原表中复制。
目标表存量数据处理策略(未选中结构复制时需要选择) - 预检查报错并停止任务:预检查阶段检测到目标表中存在数据时,停止任务。
- 忽略目标存量数据,追加写入:预检查阶段检测到目标表中存在数据时,忽略该部分数据,追加写入其他数据。
- 清空目标存量数据,重新写入:预检查阶段检测到目标表中存在数据时,删除该部分数据,重新写入。
在选择复制对象页签,配置下列参数,然后单击下一步。
参数 说明 复制对象 选择需要复制的内容,您可以选择全部实例复制源库所有内容,也可以选择自定义对象,在源对象列表中选中需要复制的内容,单击>添加到右侧目标对象列表。 黑名单(可选) 单击添加增加一条黑名单记录,选择需要加入黑名单的库或对象,这些内容都不会被复制。用于在自定义对象的全库复制或全实例复制中排除某些库或对象。 - 左侧下拉框:选择需要加入黑名单的库名。
- 右侧下拉框:选择对应库中的对象,您可以单击多个对象进行多选,留空则将整个数据库加入黑名单。
如果您需要创建多条相同复制对象的复制链路,可以创建一个配置文件,在新建任务的时候导入即可。单击右上角的导入配置,再单击下载模板,将配置文件模版下载到本地,编辑完成后单击上传文件上传该配置文件即可实现批量导入。配置文件说明:
参数 说明 source_table_name需同步的对象所在的源表名。 destination_table_name接收同步对象的目标表名。 source_schema_name需同步的对象所在的源 Schema 名。 destination_schema_name接收同步对象的目标 Schema 名。 source_database_name需同步的对象所在的源库名。 target_database_name接收同步对象的目标库名。 column_list需要同步的字段列表。 extra_configuration额外的配置信息,您可以在这里配置如下信息: column_rules:用于定义字段的映射关系与取值规则。字段说明:column_name:原列名。destination_column_name:指定目标列名。column_value:指定字段值,可为 SQL 函数或常量值。
filter_condition:用于指定行级数据的过滤条件,只有满足条件的行会被复制。
提示extra_configuration的示例内容如下:{
"extra_config":{
"column_rules":[
{
"column_name": "created_time", //指定需要执行列名映射的原列名。
"destination_column_name": "migrated_time", //目标列名映射为 "migrated_time"。
"column_value": "current_timestamp()" //将列的字段取值更改为当前时间戳。
}
],
"filter_condition": "id != 0" //ID 不为 0 的行才会同步。
}
}配置文件的整体示例内容请参见下载的模版。
在"配置映射"页签,根据所选的复制类型选择不同操作,然后单击保存并预检查。如果在配置映射阶段,源和目标数据源中有更新,可以单击页面右上角的刷新元数据按钮,重新获取源和目标数据源的信息。
包含结构复制:配置目标表同步到目标数据源之后的表名。
不包含结构复制:系统默认选择目标数据源中的同名数据库,如果不存在,则需要手动选择目标库。目标库中的表名、列名需要和同步对象一致。如果不一致,您也可以手动进行表名和列名的映射。
除此之外,您还可以执行如下 ETL(Extract、Transform、Load )操作 :
使用字段表达式:以去除字段名称最右侧的空格为例,单击目标表右侧的映射与过滤,找到需要调整的字段,单击其字段表达式列下方的空白框,在请输入文本框中输入
removepattern(x,' +$'),单击提交,然后再单击确定即可。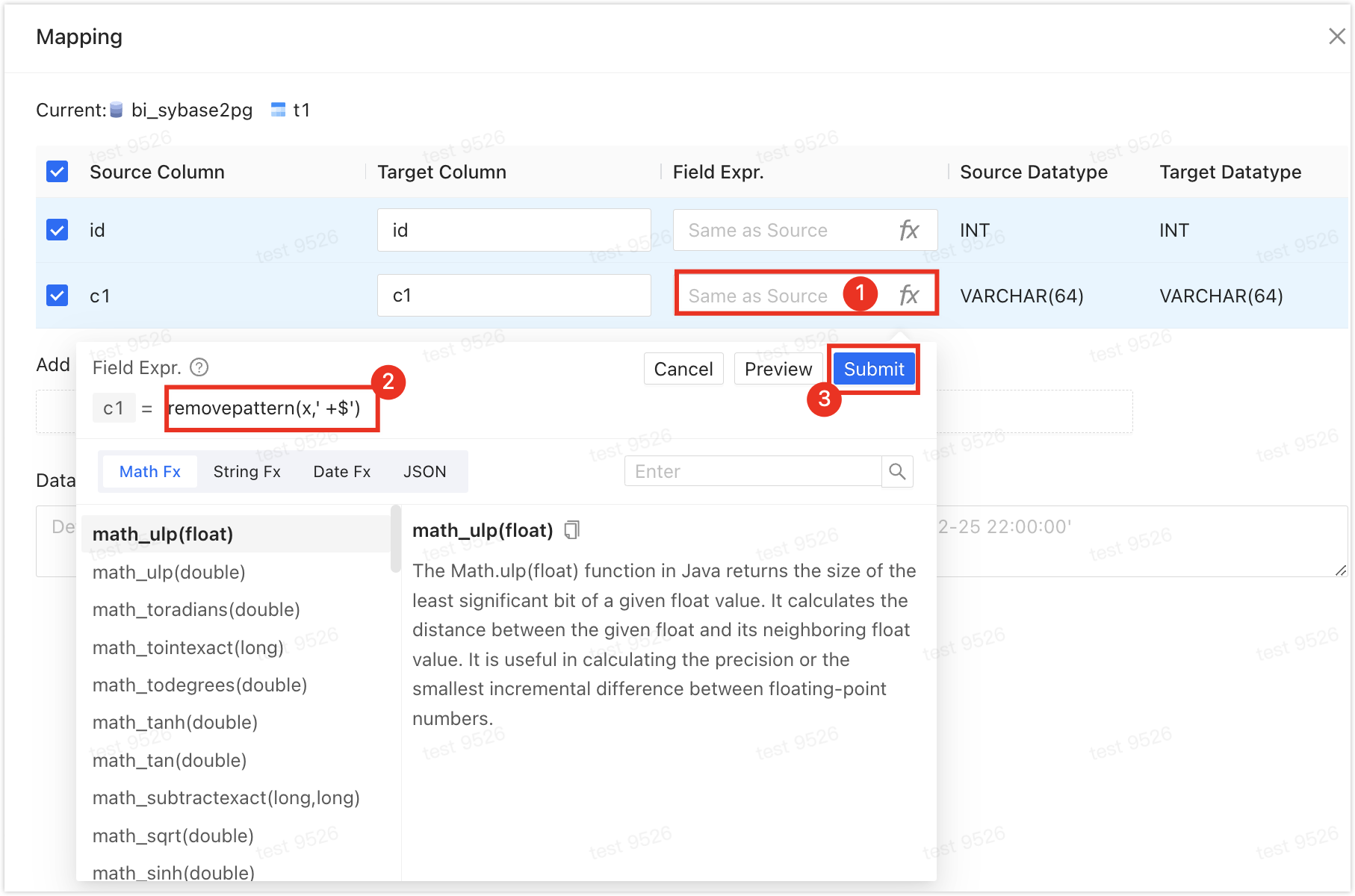
在目标表中新增列:以添加
hospital_code列(值为常数)为例,单击目标表右侧的映射与过滤,然后单击目标表添加列下方的添加,依次填充列名、字段表达式、以及字段类型,然后单击确定即可。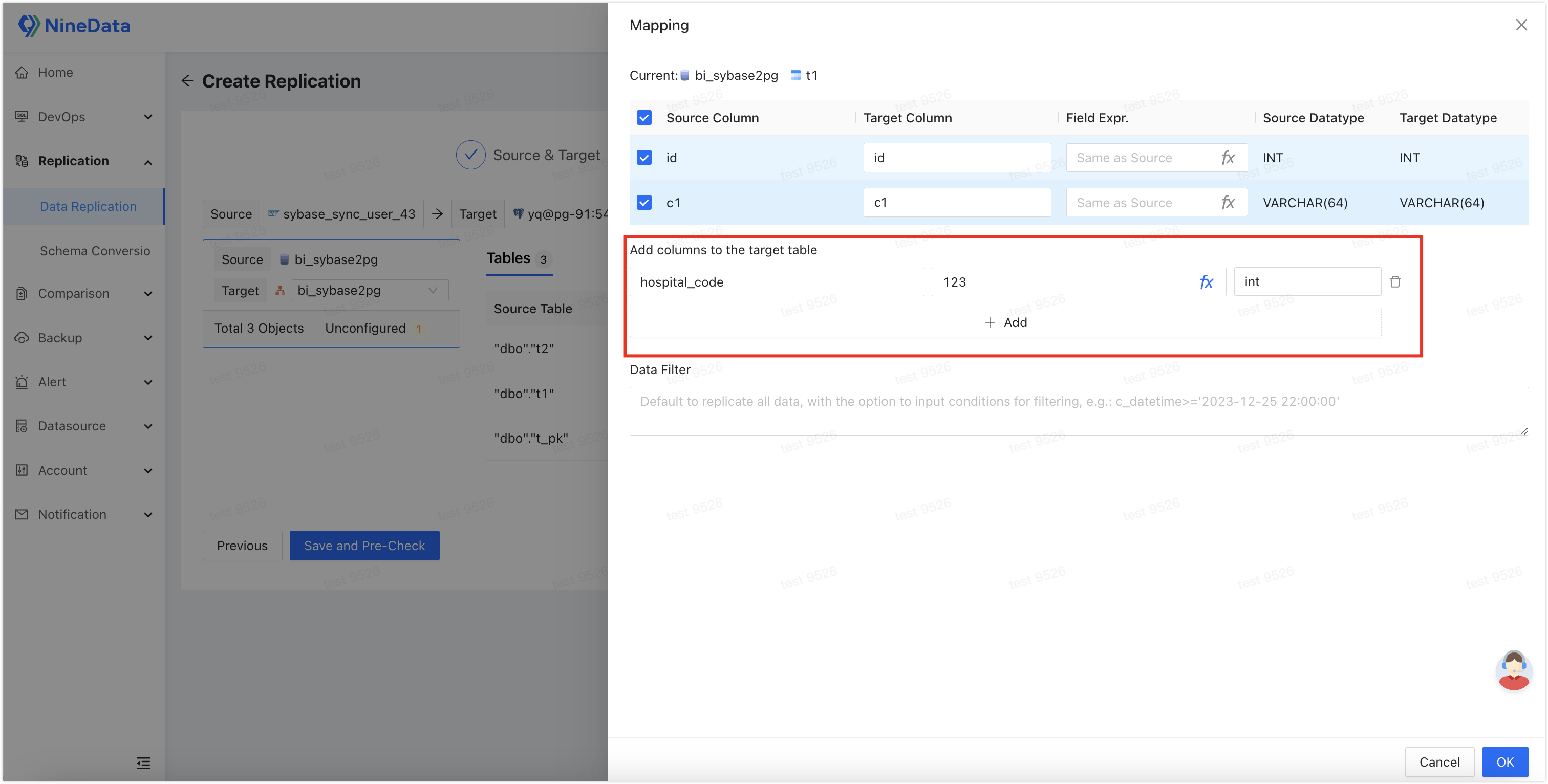
设置数据过滤条件:单击页面右侧的映射与过滤,在数据过滤条件下方文本框中,输入
emp_no>=10005,则 emp_no 列中小于 10005 的数据均不会同步到目标数据源。
在"预检查"页签,等待系统完成预检查,预检查通过后,单击启动任务。
提示- 您可以勾选开启数据一致性对比。在同步任务完成后,自动开启基于源数据源的数据一致性对比,保证两端数据一致。根据您选择的复制类型,开启数据一致性对比的启动时机如下:
- 结构复制:结构复制完成后启动。
- 结构复制+全量复制、全量复制:全量复制完成后启动。
- 如果预检查未通过,需要单击目标检查项右侧操作列的详情,排查失败的原因,手动修复后单击重新检查重新执行预检查,直到通过。
- 检查结果为警告的检查项,可视具体情况修复或忽略。
- 您可以勾选开启数据一致性对比。在同步任务完成后,自动开启基于源数据源的数据一致性对比,保证两端数据一致。根据您选择的复制类型,开启数据一致性对比的启动时机如下:
在启动任务页面,提示启动成功,同步任务开始运行。此时您可以进行如下操作:
- 单击查看详情查看同步任务各个阶段的执行情况。
- 单击返回列表可以返回数据复制任务列表页面。
步骤三:查看同步结果
登录 NineData 控制台。
在左侧导航栏单击数据复制 > 数据复制。
在数据复制页面单击目标同步任务的任务 ID,页面说明如下。

序号 功能 说明 1 配置告警 配置告警后,系统会在任务失败时通过您选择的方式通知您。更多信息,请参见运维监控简介。 2 更多 - 暂停:暂停任务,仅状态为运行中的任务可选。
- 类似创建:创建一个和当前任务配置相同的新复制任务。
- 终止:结束未完成或监听中(即增量同步中)的任务,终止任务后无法重启任务,请谨慎操作。如果同步对象中包含触发器,会弹出触发器复制选项,请按需选择。
- 删除:删除任务,任务删除后无法恢复,请谨慎操作。
3 结构复制(包含结构复制的场景下显示) 展示结构复制的进度和详细信息。 - 单击页面右侧的日志:查看结构复制的执行日志。
- 单击页面右侧的
 :查看最新的信息。
:查看最新的信息。 - 单击列表中目标对象右侧操作列的查看 DDL:可以查看 SQL 回放。
4 全量复制(包含全量复制的场景下显示) 展示全量复制的进度和详细信息。 - 单击页面右侧的监控:查看全量复制过程中的各监控指标。全量复制过程中,还可以单击监控指标页面右侧的限流设置,限制每秒写入到目标数据源的速率。单位为行/秒。
- 单击页面右侧的日志:查看全量复制的执行日志。
- 单击页面右侧的:查看最新的信息。
5 数据对比 展示源数据源和目标数据源之间对比的结果。如果您未开启数据对比,请单击页面中的开启数据对比。 - 单击页面右侧的重新对比:对当前源和目标两端数据重新发起对比。
- 单击页面右侧的停止:对比任务开始后,可单击该按钮立即停止对比任务。
- 单击页面右侧的日志:查看一致性对比的执行日志。
- 单击页面右侧的监控(仅数据对比显示):查看对比 RPS(每秒对比的记录数)的走势图。单击详情可以查看更早之前的记录。
- 在对比列表右侧操作列单击
 (数据页签下只在不一致情况下显示):查看源端和目标端的对比详情。
(数据页签下只在不一致情况下显示):查看源端和目标端的对比详情。 - 在对比列表右侧操作列单击
 (不一致情况下显示):生成变更 SQL,您可以直接复制该 SQL 到目标数据源执行,修改不一致的内容。
(不一致情况下显示):生成变更 SQL,您可以直接复制该 SQL 到目标数据源执行,修改不一致的内容。
6 展开 展示当前复制任务的详细信息。常用选项: - 导出表配置:导出当前任务的库表配置,可在新建复制任务时快速导入,以快速创建多条相同复制对象的复制链路。
- 告警规则:配置当前任务的告警策略。
附录:路由算法说明
路由算法的主要功能是自动完成数据路由,路由算法配置中,目标分库与分表通过以下表达式定义:
'<dbname_expression>''.<tablename_expression>'
<dbname_expression>:分库名表达式,格式:'<dbname_prefix>'+(<expression>)+'<dbname_suffix>'。'<dbname_prefix>':分库名前缀,例如'logical_db_0'。(<expression>):分库名组合的动态数字部分,例如#user_id#%4。假设user_id列的值为1,除以4取余的结果就是1,则结合分库名前缀即为logical_db_01。NineData 规定在路由算法中的字段名前后使用#进行标识,方便解析。'<dbname_suffix>':分库名后缀,根据实际情况配置,可为空。例如'_bak'。则组合后的分库名为logical_db_01_bak。
示例:假设通过
#user_id#%4计算的结果为 0,则路由到对应分库的<dbname_expression>写法如下。需路由的分库名称 <dbname_expression>写法logical_db_01 'logical_db_0'+(#user_id#%4+1) logical_db_01_bak 'logical_db_0'+(#user_id#%4+1)+'_bak' logical_db_00 'logical_db_0'+(#user_id#%4) logical_db_1 'logicaldb'+(#user_id#%4+1) .<tablename_expression>:分表名表达式,格式:'.<tablename_prefix>'+(<expression>)+'<tablename_suffix>'。'.<tablename_prefix>':分表名前缀,例如'.test_time_0'。点(.)代表该表名隶属于前面的库。(<expression>):分表名组合的动态数字部分,例如#user_id#%4。假设user_id列的值为1,除以4取余的结果就是1,则结合分表名前缀即为test_time_01。NineData 规定在路由算法中的字段名前后使用#进行标识,方便解析。'<tablename_suffix>':分库名后缀,根据实际情况配置,可为空。例如'_bak'。则组合后的分表名为.test_time_01_bak。
示例:假设通过
#user_id#%4计算的结果为 0,则路由到对应分表的.<tablename_expression>写法如下。需路由的分表名称 <dbname_expression>写法test_time_01 '.test_time_0'+(#user_id#%4+1) test_time_01_bak '.test_time_0'+(#user_id#%4+1)+'_bak' test_time_00 '.test_time_0'+(#user_id#%4) test_time_1 '.testtime'+(#user_id#%4+1)
结合上述的例子,如果 user_id 列的值为 0,那下述路由算法将路由至 logical_db_01 分库下的 test_time_01 分表。
'logical_db_0'+(#user_id#%4+1)'.test_time_0'+(#user_id#%4+1)