Kafka 迁移同步到 MySQL
NineData 数据复制支持将 Kafka 中的数据复制到 MySQL,实现 Kafka 数据自动结构化以及实时数据复制。
背景信息
NineData 为您提供了一个强大而可靠的数据复制解决方案,通过该解决方案,可以简化开发人员在不同数据存储之间迁移数据的过程,提高数据管理的效率。您可以方便地利用 Kafka 的高吞吐量和实时性能实现分布式数据处理等场景,同时将 Kafka 中的数据迁移到 MySQL 数据库中,进行安全储存以及实时分析查询。
前提条件
- 已将源和目标数据源添加至 NineData。如何添加,请参见创建数据源。
- 源数据源为 Kafka 0.10 及以上版本。
支持的 MySQL 数据源版本为 5.1 ~ 9.0。
- 基于 Kafka JSON 对象中各字段的名称,已在目标端的 MySQL 上创建相对应的库、表、列。
操作步骤
NineData 数据复制产品已商业化,您仍然可以保有 10 条复制任务免费使用,注意事项如下:
- 10 条复制任务中可以包含 1 条增量复制任务,规格为 Micro。
- 状态为已终止的任务不算在 10 条任务的限制内,如果您已经创建了 10 条复制任务,还想要继续创建,可以先终止之前的复制任务,然后再创建新任务。
- 创建复制任务时,仅可选择您已购买的复制规格,未购买的规格将以灰度显示,无法选择。如需购买,请通过页面右下角的客服图标联系我们。
登录 NineData 控制台。
在左侧导航栏单击数据复制。
在数据复制页面中单击创建复制。
在数据源与目标页签,按照下表进行配置,并单击下一步。
参数 说明 任务名称 输入数据同步任务的名称,为了方便后续查找和管理,请尽量使用有意义的名称。最多支持 64 个字符。 源数据源 同步对象所在的数据源,此处选择需复制数据所在的 Kafka 数据源。 目标数据源 接收同步对象的数据源,此处选择目标 MySQL 数据源。 Kafka Topic 选择需要复制的 Kafka Topic(主题)。 Message Format 选择数据将以什么格式复制到 MySQL,当前仅支持 Canal-JSON。 复制开始时间 - Earliest (复制 Topic 中最早的 Message):从 Kafka Topic 中寻找最早的一条消息,并按顺序复制到 MySQL。
- Latest (启动任务后,复制 Topic 中新产生的 Message):忽略 Kafka Topic 中已存在的数据,仅复制任务开始之后新产生的消息。
- 自定义 Offset (从定义 Offset 开始复制):自定义 Kafka Topic 中的消息位置,即 Offset 编号。系统将从该 Offset 编号开始按顺序复制消息。
目标表存量数据处理策略 - 预检查报错并停止任务:预检查阶段检测到目标表中存在数据时,停止任务。
- 忽略目标存量数据,追加写入:预检查阶段检测到目标表中存在数据时,忽略该部分数据,追加写入其他数据。
- 清空目标存量数据,重新写入:预检查阶段检测到目标表中存在数据时,删除该部分数据,重新写入。
在选择复制对象页签,配置下列参数,然后单击下一步。
参数 说明 待复制对象 选择 Kafka 数据复制到 MySQL 之后的存储位置,您可以选择全部实例包含 MySQL 的所有库,也可以选择自定义对象,源对象列表中选中需要存储 Kafka 数据的位置,然后单击>添加到右侧目标对象列表。 在配置映射页签,可以单独配置 Kafka 消息中的键值对与每个 MySQL 库表列之间的映射关系,只要符合您配置条件的 Kafka 消息,都会保存在 MySQL 中对应的位置。更多信息,请参见附录。
提示Message Format 为 Canal-JSON 的情况下,您需要为每个 MySQL 的库和表配置 Kafka 中 $.database 和 $.table 字段的映射。例如,将 $.database 配置为
sample_employees_210,$.table 配置为departments,则 Kafka 中符合该条件的所有消息均会复制到 MySQL 目标库表的对应列中。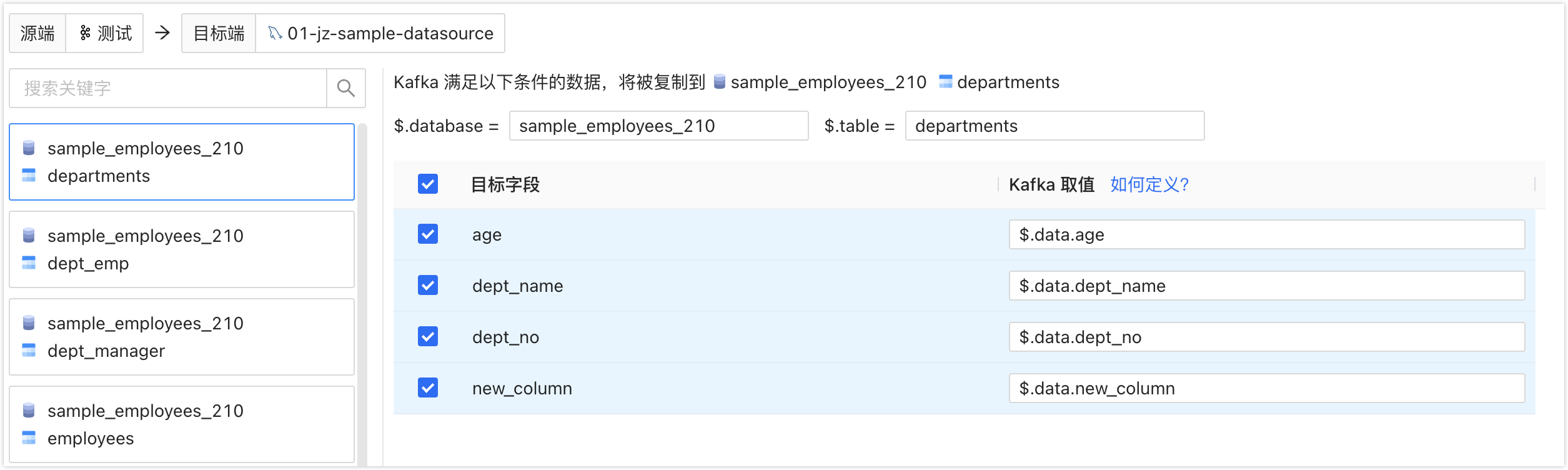
在预检查页签,等待系统完成预检查,预检查通过后,单击启动任务。
提示如果预检查未通过,需要单击目标检查项右侧操作列的详情,排查失败的原因,手动修复后单击重新检查重新执行预检查,直到通过。
检查结果为警告的检查项,可视具体情况修复或忽略。
在启动任务页面,提示启动成功,同步任务开始运行。此时您可以进行如下操作:
- 单击查看详情可以查看同步任务各个阶段的执行情况。
- 单击返回列表可以返回数据复制任务列表页面。
查看同步结果
登录 NineData 控制台。
在左侧导航栏单击数据复制。
在数据复制页面单击目标同步任务的 ID,打开复制详情页面,页面说明如下。

序号 功能 说明 1 同步延迟 源数据源和目标数据源之间的数据同步延迟,0 秒表示两端之间没有延迟。 2 配置告警 配置告警后,系统会在任务失败时通过您选择的方式通知您。更多信息,请参见运维监控简介。 3 更多 - 暂停:暂停任务,仅状态为运行中的任务可选。
- 终止:结束未完成或监听中(即增量同步中)的任务,终止任务后无法重启任务,请谨慎操作。
- 删除:删除任务,任务删除后无法恢复,请谨慎操作。
4 增量复制 展示增量复制的各项监控指标。 - 单击页面右侧的日志:查看增量复制的执行日志。
- 单击页面右侧的
 图标:查看最新的信息。
图标:查看最新的信息。
5 修改对象 展示同步对象的修改记录。 - 单击页面右侧的修改同步对象,可对同步对象进行配置。
- 单击页面右侧的图标:查看最新的信息。
6 更多 展示当前复制任务的详细信息,包括正在同步中的 Kafka Topic、Message Format、开始时间等。
附录:JSON_PATH 的定义
Kafka 迁移到 MySQL 是通过提取 Kafka 中 JSON 对象中的数据并转存到 MySQL 中目标库表的方式来实现的,而 JSON_PATH 是用于定位 Kafka JSON 对象中特定元素的一种路径表达式,本章节介绍 JSON_PATH 的定义。
JSON_PATH 由 Scope 和 pathExpression 两个主要部分组成:
- Scope:由美元符号($)表示,代表 JSON 的根。
- pathExpression:用于匹配 JSON 对象中特定元素的路径,由一个或多个 pathLeg 组成,这些 pathLeg 可以是 member、arrayLocation 或 doubleAsterisk,多个 pathLeg 代表多个层级。
- member:匹配 JSON 对象中的 Key。格式为
.<Key 名称>或.*,前者将在 JSON 对象中基于指定的 Key 名称查找;后者表示 JSON 对象中的所有 Key。 - arrayLocation:匹配 JSON 对象中的数组元素。格式为
[<非负整数>]或[*],前者将在 JSON 对象中基于指定的非负整数定位数组元素;后者表示 JSON 对象中的所有数组元素。 - doubleAsterisk:匹配任意层级的 Key 或数组位置。格式为
.**。
- member:匹配 JSON 对象中的 Key。格式为
示例:以下是一段 Kafka 中的 JSON 对象示例,通过 JSON_PATH 进行匹配。
{
"data": [{
"id": "2",
"name": "John",
"address": "2"
}],
"database": "9zcloud",
"es": 1693809702000,
"id": 63,
"isDdl": false,
"mysqlType": {
"id": "int",
"name": "varchar(20)",
"address": "varchar(50)"
},
"old": null,
"pkNames": ["id"],
"sql": "",
"sqlType": {
"id": 4,
"name": 12,
"address": -5
},
"table": "t",
"ts": 1693809701769,
"type": "INSERT"
}
$.data:匹配名为 data 的 JSON 对象。$.data.id:匹配 data JSON 对象下名为 id 的 Key。$.**:匹配 JSON 对象中任意层级的任意 Key。