GaussDB 迁移同步到 Datahub
NineData 数据复制支持 GaussDB 到 Datahub 数据源之间的数据同步。
功能介绍
NineData 数据复制支持数据源之间的结构、全量数据、增量数据的高性能复制,对于部分数据源,还提供双向复制功能,实现快捷构建异地多活业务架构。
- 结构:支持同构及异构数据源之间的对象结构复制,很大程度上降低了两个数据源之间的数据复制门槛。
- 全量数据:通过智能数据分片实现行级并发批量复制能力,有效保障复制性能。自主研发的新型断点续传技术,保证无主键表的数据准确性。
- 增量数据:支持全对象类型的 DML|DDL 增量数据复制,结合行级并发、热点合并等技术,提供强劲复制性能。
- 双向数据实时复制:直接多个节点之间的数据双向复制,保证所有节点的数据均保持最新状态。
通过以上功能,可以轻松高效地实现全量|增量数据复制、全量|增量数据迁移、全量|增量数据同步、数据集成、不停机无缝迁移等场景,为企业提供灵活和可靠的数据复制解决方案。
前提条件
- 已将源数据源和目标数据源添加至 NineData。如何添加,请参见添加数据源。
- 源的数据源类型为 GaussDB。
- 目标的数据源类型为 Datahub。
如需增量复制,请确保已完成如下条件:
已将 NineData 的服务地址加入到逻辑复制节点的白名单。NineData 的服务地址即录入 GaussDB 数据源页面中,接入地域下方显示的 IP 地址。
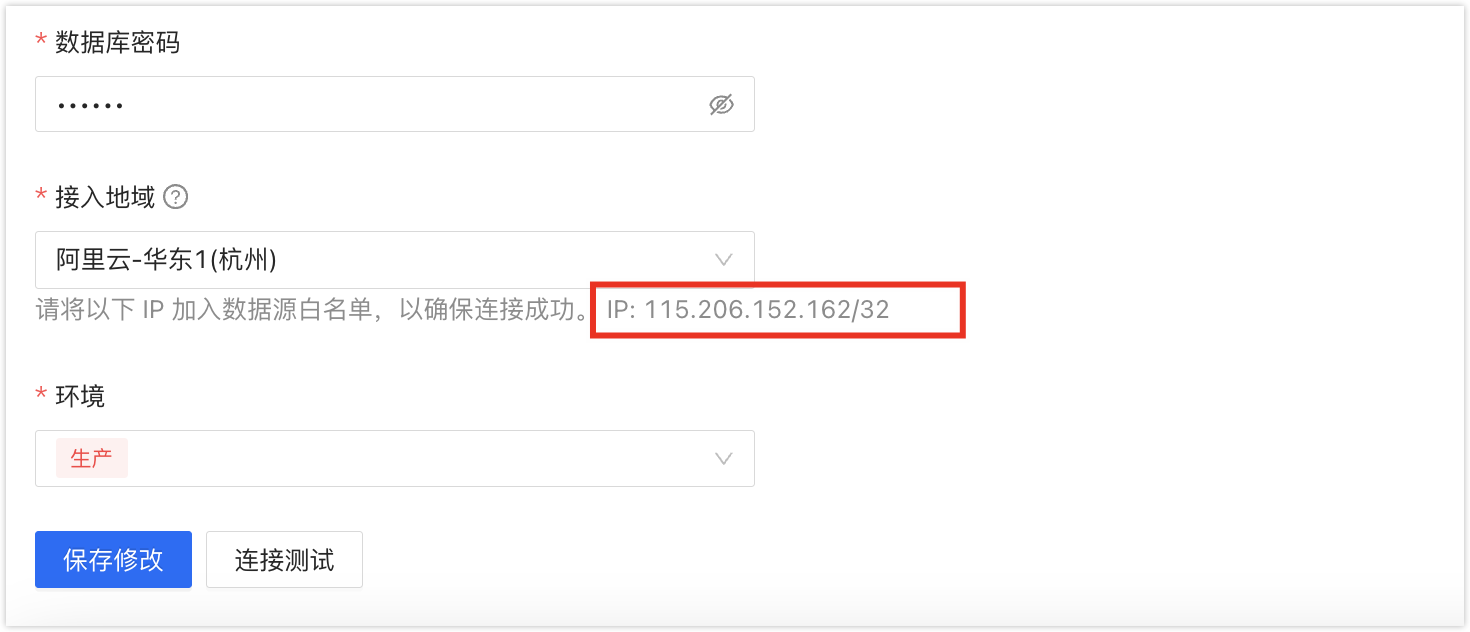
源数据源的
wal_level参数必须为logical。源数据源的
max_replication_slots参数必须大于1。此参数指定服务器可以支持的最大复制槽数。默认值为10。源数据源的
max_wal_senders参数必须大于1。此参数指定最大的并发连接数。默认值为10。
提示上述更改可以提交华为云工单进行更改。
使用限制
- 执行数据同步前需评估源数据源和目标数据源的性能,同时建议业务低峰期执行数据同步。否则全量数据初始化时将占用源数据源和目标数据源一定的读写资源,导致数据库负载上升。
- 需要确保同步对象中的每张表都有主键或唯一约束、列名具有唯一性,否则可能会重复同步相同数据。
操作步骤
NineData 数据复制产品已商业化,您仍然可以保有 10 条复制任务免费使用,注意事项如下:
- 10 条复制任务中可以包含 1 条增量复制任务,规格为 Micro。
- 状态为已终止的任务不算在 10 条任务的限制内,如果您已经创建了 10 条复制任务,还想要继续创建,可以先终止之前的复制任务,然后再创建新任务。
- 创建复制任务时,仅可选择您已购买的复制规格,未购买的规格将以灰度显示,无法选择。如需购买,请通过页面右下角的客服图标联系我们。
登录 NineData 控制台。
在左侧导航栏单击数据复制。
在数据复制页面,单击右上角的创建复制。
在数据源与目标页签,按照下表进行配置,并单击下一步。
参数 说明 任务名称 输入数据同步任务的名称,为了方便后续查找和管理,请尽量使用有意义的名称。最多支持 64 个字符。 源数据源 同步对象所在的数据源。 目标数据源 接收同步对象的数据源。 Datahub Project 选择目标 Datahub Project,源数据源中的数据将写入到该指定 Project 中。 目标对象命名规则 选择对象名称从源端迁移到目标端后的大小写转换规则。 - 全部转小写:无论源端的命名规则如何,目标端的命名规则全部为小写。
- 保持与源一致:沿用源端的命名规则。
- 全部转大写:无论源端的命名规则如何,目标端的命名规则全部为大写。
复制类型 选择需要复制到目标数据源的内容。 - 结构复制:只同步源数据源的库表结构,不同步数据。
- 全量复制:同步源数据源的所有对象和数据,即全量数据复制。右侧的开关为周期性全量复制的开关,更多信息,请参见周期性全量复制。
- 增量复制:在全量同步完成后,基于源数据源的日志进行增量同步。
逻辑复制地址(选中增量复制时需要填写) 此处默认为源库的 IP 地址和端口号(端口默认 + 1),如果无法连接,请确认您 GaussDB 实例的复制连接端口(请参见 GaussDB 为源链路增量同步连接及端口说明)。
GaussDB 的逻辑复制地址通过逻辑解码,将 WAL 日志解析为易于理解和处理的逻辑日志格式,NineData 从该地址接收日志用于实时同步增量数据。目标库同名对象处理策略(选中结构复制时需要选择) - 预检查报错并停止任务:预检查阶段检测到同名表时,停止任务。
- 跳过并继续任务:预检查阶段检测到同名表时,发送提示并继续任务。 结构复制时,忽略该同名表。如果您同时进行了数据复制,则数据会在同名表中追加,而不会覆盖原有数据。
- 删除对象并重建:预检查阶段检测到同名表时,发送提示并继续任务。结构复制时,删除目标库同名表,并基于源库重新复制表结构。如果您同时进行了数据复制,则数据会在表结构复制完成后写入。
- 保留结构并清空数据,再覆盖写入(同时进行结构和数据复制时可选):预检查阶段检测到同名表时,发送提示并继续任务。结构复制时在目标库保留该表结构,并在数据复制开始时清空同名表中的数据,然后重新从原表中复制。
目标表存量数据处理策略(未选中结构复制时需要选择) - 预检查报错并停止任务:预检查阶段检测到目标表中存在数据时,停止任务。
- 忽略目标存量数据,追加写入:预检查阶段检测到目标表中存在数据时,忽略该部分数据,追加写入其他数据。
在选择复制对象页签,配置下列参数,然后单击下一步。
参数 说明 复制对象 选择需要复制的内容,您可以选择全部实例复制源库所有内容,也可以选择自定义对象,在源对象列表中选中需要复制的内容,单击>添加到右侧目标对象列表。 如果您需要创建多条相同复制对象的复制链路,可以创建一个配置文件,在新建任务的时候导入即可。单击右上角的导入配置,再单击下载模板,将配置文件模版下载到本地,编辑完成后单击上传文件上传该配置文件即可实现批量导入。配置文件说明:
参数 说明 source_table_name需同步的对象所在的源表名。 destination_table_name接收同步对象的目标表名。 source_schema_name需同步的对象所在的源 Schema 名。 destination_schema_name接收同步对象的目标 Schema 名。 source_database_name需同步的对象所在的源库名。 target_database_name接收同步对象的目标库名。 column_list需要同步的字段列表。 extra_configuration额外的配置信息,您可以在这里配置如下信息: column_rules:用于定义字段的映射关系与取值规则。字段说明:column_name:原列名。destination_column_name:指定目标列名。column_value:指定字段值,可为 SQL 函数或常量值。
filter_condition:用于指定行级数据的过滤条件,只有满足条件的行会被复制。
提示extra_configuration的示例内容如下:{
"extra_config":{
"column_rules":[
{
"column_name": "created_time", //指定需要执行列名映射的原列名。
"destination_column_name": "migrated_time", //目标列名映射为 "migrated_time"。
"column_value": "current_timestamp()" //将列的字段取值更改为当前时间戳。
}
],
"filter_condition": "id != 0" //ID 不为 0 的行才会同步。
}
}配置文件的整体示例内容请参见下载的模版。
在配置映射页签,根据所选的复制类型选择不同操作,然后单击保存并预检查。
包含结构复制:配置目标表同步到目标数据源之后的表名。
不包含结构复制:系统默认选择目标数据源中的同名数据库,如果不存在,则需要手动选择目标库。目标库中的表名、列名需要和同步对象一致。如果不一致,您也可以手动进行表名和列名的映射。
除此之外,您还可以进行如下操作:
如果在配置映射阶段,源和目标数据源中有更新,可以单击页面右上角的刷新元数据按钮,重新获取源和目标数据源的信息。
单击目标表右侧的列选择与处理配置,可以单独配置每个列。
单击目标表右侧的列选择与处理配置,可以配置系统字段配置。Datahub 作为一个队列产品,不支持随机的 UPDATE/DELETE 操作,因此 NineData 需要往用户的 Datahub 中新增如下几个元数据字段,为每条投递到 Datahub 的数据标识特性。
元数据字段名 元数据字段取值 _record_id_${nd_record_id} _operation_type_${nd_operation_type} _execution_time_${nd_exec_timestamp} _before_image_${nd_before_image} _after_image_${nd_after_image} 您也可以按需添加、修改元数据字段名称或取值,关于各字段取值的详细信息,请参见本文附录。
单击目标表右侧的列选择与处理配置,可以通过比较表达式配置数据过滤条件。仅符合过滤条件的数据会同步到目标数据源。例如,将过滤条件设置为
emp_no>=10005,则 emp_no 列中小于 10005 的数据均不会同步到目标数据源。
在预检查页签,等待系统完成预检查,预检查通过后,单击启动任务。
提示您可以勾选开启数据一致性对比。在同步任务完成后,自动开启基于源数据源的数据一致性对比,保证两端数据一致。根据您选择的复制类型,开启数据一致性对比的启动时机如下:
结构复制:结构复制完成后启动。
结构复制+全量复制、全量复制:全量复制完成后启动。
结构复制+全量复制+增量复制、增量复制:当增量数据首次和源数据源一致且延迟为 0 秒时启动。您可以单击查看详情,在复制详情页面中查看同步延迟。

如果预检查未通过,需要单击目标检查项右侧操作列的详情,排查失败的原因,手动修复后单击重新检查重新执行预检查,直到通过。
检查结果为警告的检查项,可视具体情况修复或忽略。
在启动任务页面,提示启动成功,同步任务开始运行。此时您可以进行如下操作:
- 单击查看详情查看同步任务各个阶段的执行情况。
- 单击返回列表可以返回数据复制任务列表页面。
查看同步结果
登录 NineData 控制台。
在左侧导航栏单击数据复制 > 数据复制。
在数据复制页面单击目标同步任务的任务 ID,页面说明如下。

序号 功能 说明 1 同步延迟 源数据源和目标数据源之间的数据同步延迟,0 秒表示两端之间没有延迟,此时您可以选择将业务切换到目标数据源,实现平滑迁移。 2 配置告警 配置告警后,系统会在任务失败时通过您选择的方式通知您。 3 更多 - 暂停:暂停任务,仅状态为运行中的任务可选。
- 类似创建:创建一个和当前任务配置相同的新复制任务。
- 终止:结束未完成或监听中(即增量同步中)的任务,终止任务后无法重启任务,请谨慎操作。如果同步对象中包含触发器,会弹出触发器复制选项,请按需选择。
- 删除:删除任务,任务删除后无法恢复,请谨慎操作。
4 结构复制(包含结构复制的场景下显示) 展示结构复制的进度和详细信息。 - 单击页面右侧的日志:查看结构复制的执行日志。
- 单击页面右侧的
 :查看最新的信息。
:查看最新的信息。 - 单击列表中目标对象右侧操作列的查看 DDL:可以查看 SQL 回放。
5 全量复制(包含全量复制的场景下显示) 展示全量复制的进度和详细信息。 - 单击页面右侧的监控:查看全量复制过程中的各监控指标。全量复制过程中,还可以单击监控指标页面右侧的限流设置,限制每秒写入到目标数据源的速率。单位为行/秒。
- 单击页面右侧的日志:查看全量复制的执行日志。
- 单击页面右侧的:查看最新的信息。
6 增量复制(包含增量复制的场景下显示) 展示增量复制的各项监控指标。 - 单击页面右侧的查看线程:查看当前复制任务正在执行中的操作,包含:
- 线程号:复制任务分多个线程执行复制操作,展示当前进行中的线程号。
- 执行 SQL:当前线程正在执行中的 SQL 语句详情。
- 提交响应时间:当前线程的响应时间,如果该数值变大,则代表当前线程可能由于某些原因卡住。
- 事件时间:当前线程开启的时间戳。
- 状态:当前线程的状态。
- 单击页面右侧的限流设置:限制每秒写入到目标数据源的速率。单位为行/秒。
- 单击页面右侧的日志:查看增量复制的执行日志。
- 单击页面右侧的:查看最新的信息。
7 修改对象 展示同步对象的修改记录。 - 单击页面右侧的修改同步对象,可对同步对象进行配置。
- 单击页面右侧的:查看最新的信息。
8 数据对比 展示源数据源和目标数据源之间对比的结果。如果您未开启数据对比,请单击页面中的开启数据对比。 - 单击页面右侧的重新对比:对当前源和目标两端数据重新发起对比。
- 单击页面右侧的停止:对比任务开始后,可单击该按钮立即停止对比任务。
- 单击页面右侧的日志:查看一致性对比的执行日志。
- 单击页面右侧的监控(仅数据对比显示):查看对比 RPS(每秒对比的记录数)的走势图。单击详情可以查看更早之前的记录。
- 在对比列表右侧操作列单击
 (数据页签下只在不一致情况下显示):查看源端和目标端的对比详情。
(数据页签下只在不一致情况下显示):查看源端和目标端的对比详情。 - 在对比列表右侧操作列单击
 (不一致情况下显示):生成变更 SQL,您可以直接复制该 SQL 到目标数据源执行,修改不一致的内容。
(不一致情况下显示):生成变更 SQL,您可以直接复制该 SQL 到目标数据源执行,修改不一致的内容。
9 展开 展示当前复制任务的详细信息。常用选项: - 导出表配置:导出当前任务的库表配置,可在新建复制任务时快速导入,以快速创建多条相同复制对象的复制链路。
- 告警规则:配置当前任务的告警策略。
附录 1:数据类型映射表
| 类别 | GaussDB 数据类型 | DataHub 数据类型 |
|---|---|---|
| Numeric | TINYINT/INT1 | TINYINT |
| UINT1 | SMALLINT | |
| SMALLINT/INT2 | SMALLINT | |
| UINT2 | INTEGER | |
| MEDIUMINT/INT3 | INTEGER | |
| UINT3 | BIGINT | |
| BINARY_INTEGER/INT4 | INTEGER | |
| INTEGER | 精度和标度不为空,转换为 DECIMAL, 否则转换为 INTEGER。 | |
| UINT4 | BIGINT | |
| BIGINT/INT8 | DECIMAL | |
| UINT8 | DECIMAL | |
| INT16 | DECIMAL | |
| NUMERIC/DECIMAL/DEC/NUMBER | DECIMAL | |
| SMALLSERIAL | SMALLINT | |
| SERIAL | INTEGER | |
| BIGSERIAL | BIGINT | |
| LARGESERIAL | DECIMAL | |
| REAL | FLOAT | |
| FLOAT4 | FLOAT | |
| FLOAT8/DOUBLE/DOUBLE PRECISION | DOUBLE | |
| BINARY DOUBLE | DOUBLE | |
| FLOAT | 精度和标度不为空,转换为 DECIMAL, 标度为空但精度小于 24,转换为 FLOAT, 否则转换为 DOUBLE。 | |
| MONEY | DECIMAL | |
| BIT | STRING | |
| BIT VARING | STRING | |
| BOOL/BOOLEAN | BOOLEAN | |
| DATE AND TIME | DATE | STRING |
| TIMESTAMP WITHOUT TIME ZONE /TIMESTAMPTZ | DATETIME | |
| TIMESTAMP WITH TIME ZONE | DATETIME | |
| TIME WITH TIME ZONE /TIMETZ | STRING | |
| TIMESTAMP | DATETIME | |
| TIME | STRING | |
| SMALL DATETIME | DATETIME | |
| RELTIME | STRING | |
| ABSTIME | DATETIME | |
| YEAR | INTEGER | |
| INTERVAL | STRING | |
| INTERVAL YEAR | STRING | |
| INTERVAL MONTH | STRING | |
| INTERVAL DAY | STRING | |
| INTERVAL HOUR | STRING | |
| INTERVAL MINUTE | STRING | |
| INTERVAL SECOND | STRING | |
| INTERVAL DAY TO HOUR | STRING | |
| INTERVAL DAY TO MINUTE | STRING | |
| INTERVAL DAY TO SECOND | STRING | |
| INTERVAL HOUR TO MINUTE | STRING | |
| INTERVAL HOUR TO SECOND | STRING | |
| INTERVAL MINUTE TO SECOND | STRING | |
| STRING | CHAR/CHARACTER | STRING |
| NCHAR | STRING | |
| VARCHAR/CHARACTER VAYING/VARCHAR2 | STRING | |
| NVARCHAR2 | STRING | |
| TINYTEXT | STRING | |
| TEXT | STRING | |
| MEDIUMTEXT | STRING | |
| LONGTEXT | STRING | |
| CLOB | STRING | |
| TINYBLOB | STRING | |
| INET | STRING | |
| CLOB | STRING | |
| CIDR | STRING | |
| MACADDR | STRING | |
| UUID | STRING | |
| HLL | STRING | |
| ACLITEM | STRING | |
| HASH16 | STRING | |
| HASH32 | STRING | |
| SET | STRING | |
| FLOATVECTOR | STRING | |
| BOOLVECTOR | STRING | |
| RANGE | INT4RANGE | STRING |
| INT8RANGE | STRING | |
| NUMRANGE | STRING | |
| DATERANGE | STRING | |
| TS RANGE | STRING | |
| TS TZ RANGE | STRING | |
| JSON | JSON | STRING |
| JSONB | STRING | |
| BINARY | TINYBLOB | STRING |
| BLOB | STRING | |
| MEDIUMBLOB | STRING | |
| LONGBLOB | STRING | |
| RAW | STRING | |
| BYTEA | STRING | |
| BYTEA WITHOUT ORDER COL | STRING | |
| BYTEA WITHOUT ORDER WITH EQUAL COL | STRING | |
| _BYTEA WITHOUT ORDER WITH EQUAL COL | STRING | |
| _BYTEA WITHOUT ORDER COL | STRING | |
| SPATIAL | POINT | STRING |
| LINE | STRING | |
| LSEG | STRING | |
| BOX | STRING | |
| PATH | STRING | |
| POLYGON | STRING | |
| CIRCLE | STRING | |
| XML | XML | STRING |
| XML TYPE | STRING |
附录 2:系统参数说明
为了在 DataHub 中实现增量数据的存储,NineData 提供了一套默认的系统参数与元数据字段,用于标识数据特性。以下是系统参数的具体含义和使用场景。
| 参数名称 | 含义与用途 |
|---|---|
| ${nd_record_id} | 每条数据记录(Record)的唯一 ID。在 UPDATE 操作中,更新前后的记录需保持相同的 record_id 以实现变更关联。 |
| ${nd_exec_timestamp} | Record 操作的运行时间。 |
| ${nd_database_name} | 表所属的数据库名称,便于区分数据来源。 |
| ${nd_table_name} | Record 所对应表的名称,用于精确定位变更记录。 |
| ${nd_operation_type} | Record 变更操作类型,取值如下:
|
| ${nd_before_image} | 前镜像标识,表示目标 Record 状态为变更发生前,即当前数据发生过变更。取值:
|
| ${nd_after_image} | 后镜像标识,表示目标 Record 状态为变更发生后,即当前数据为最新状态。取值:
|
| ${nd_datasource} | 数据源信息:数据来源的 IP 和端口号,格式为 ip:port。 |
附录:预检查项一览表
| 检查项 | 检查内容 |
|---|---|
| 源数据源连接检查 | 检查源数据源网关状态、实例是否可达、用户名及密码准确性 |
| 目标数据源连接检查 | 检查目标数据源网关状态、实例是否可达、用户名及密码准确性 |
| 源库权限检查 | 检查源数据库的账号权限是否满足要求 |
| 检查 wal_level | 检查源数据源的 wal_level 是否为 logical |
| 检查 max_wal_senders | 检查 max_wal_senders 是否满足复制连接数要求 |
| 检查 max_replication_slots | 检查 max_replication_slots 是否满足复制槽数量要求 |
| 源库无主键表存在性校验 | 检查待复制对象是否不存在主键或唯一键 |