SQL 窗口(Milvus)
NineData SQL 窗口支持 Milvus 向量数据库,通过封装行业标准的 MySQL 语法,提供面向向量数据库的 SQL 扩展能力。开发人员无需学习特定 API,可直接使用熟悉的 SQL 语法实现向量数据管理、相似性检索等操作,大幅降低技术门槛。
背景信息
Milvus 是由 Zilliz 公司开发的开源向量数据库,专为解决人工智能时代非结构化数据处理难题而设计。Milvus 面向 AI 应用的新一代基础设施,广泛应用于 AI 推理、语义搜索等场景。
尽管 Milvus 具备强大的技术能力,但其原生接口存在显著使用门槛。NineData 针对 Milvus 的使用痛点,封装了 MySQL 语法,开发者可直接通过熟悉的 SQL 语法实现 Milvus 的全量功能。
前提条件
已将目标需要管理的数据库添加到 NineData。如何添加,请参见管理数据源。Milvus 版本为 2.3、2.4、2.5,实例类型为阿里云托管版 Milvus。
在组织模式(数据库 DevOps 企业版)下,您必须拥有目标数据源的只读、DML 或 DDL 权限。
提示只读权限仅支持查询操作。
在商业化版本下(数据库 DevOps 专业版、数据库 DevOps 企业版),请确保您的包年包月订阅未过期,否则将无法正常使用数据库 DevOps 服务。您可以在 NineData 控制台页面右上方快速查看剩余配额以及到期时间。

操作步骤
登录 NineData 控制台。
在左侧导航栏单击 数据库 DevOps>SQL 窗口。
提示如果之前登录过数据源且没有关闭,则会自动进入该数据源页面。
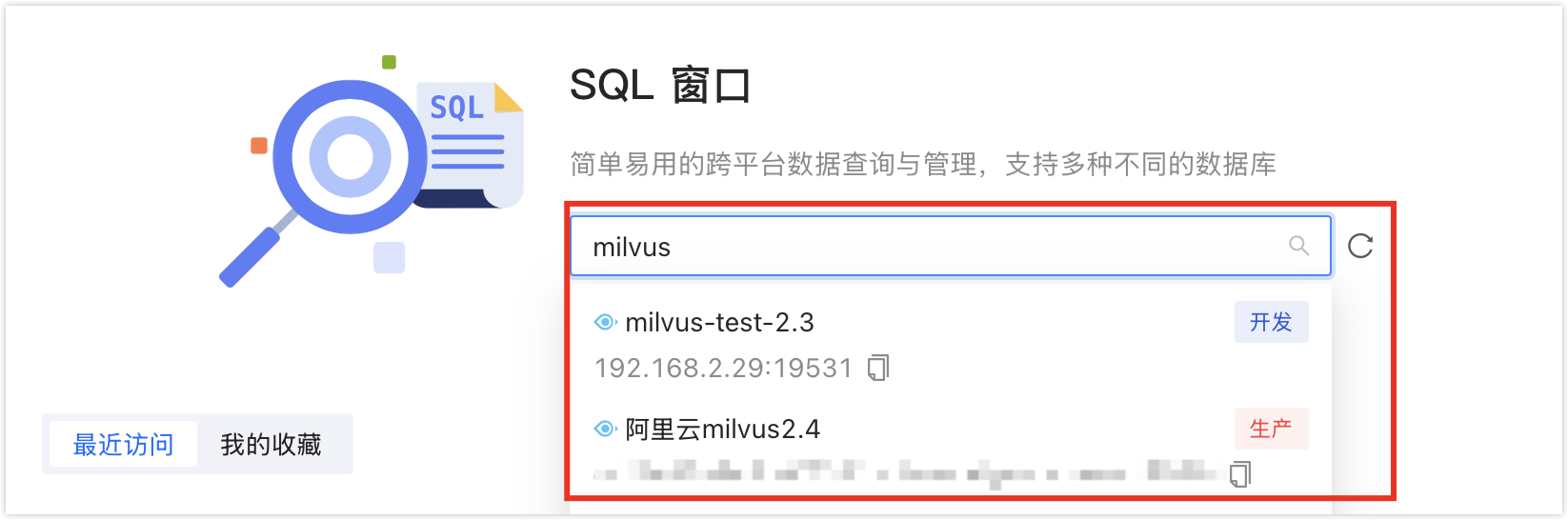
单击 SQL 窗口下方文本框,会弹出可用的数据源,单击目标数据源,并单击开始查询,跳转到 SQL 窗口。
提示- 如果您之前没有创建过数据源,则会显示空白页。此时,请单击页面中的创建数据源。
如果有多个数据源,您可以在框中输入全部或部分关键词进行精确查找或模糊查找。支持搜索的字段如下:
数据源名称
IP 地址
打开 SQL 窗口后,即可对数据源执行数据开发操作。SQL 窗口的详细使用方法,请参见界面说明。
界面说明
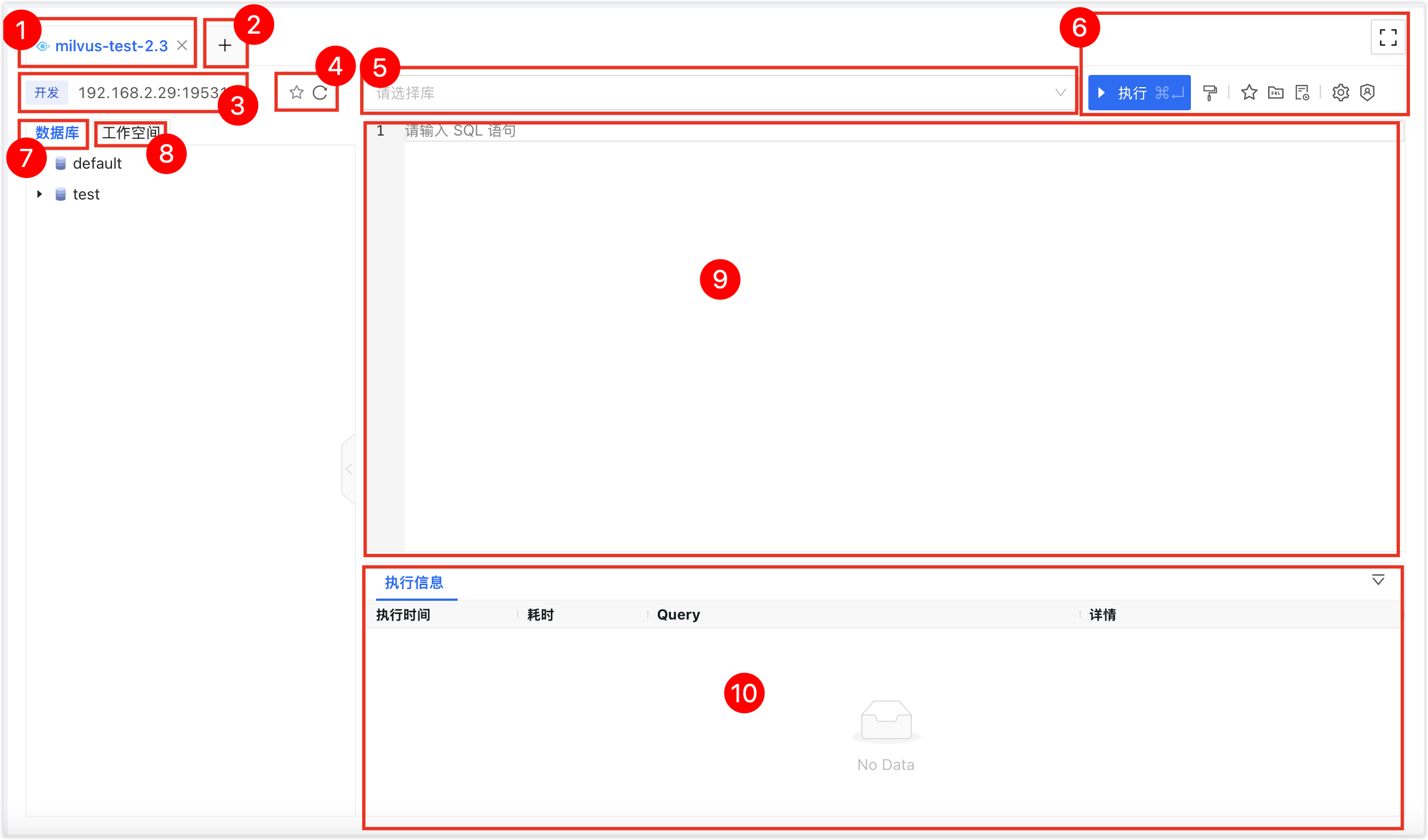
| 序号 | 功能 | 介绍 |
|---|---|---|
| 1 | SQL 窗口页签 | 表示当前已打开的数据源 SQL 窗口,多个 SQL 窗口可以通过单击页签切换,单击页签右侧的X可以关闭该 SQL 窗口;双击页签可以更改页签的名称;拖动页签可以调整页签的位置。右键菜单支持如下操作:
|
| 2 | 打开数据源 | 选择并打开新的数据源 SQL 窗口。 |
| 3 | 数据源信息 | 展示当前 SQL 窗口的数据源信息,包含环境、IP 地址以及端口号。 右键菜单:
|
| 4 | 收藏|刷新 |
|
| 5 | 数据库名称 | 选中目标数据库以执行 SQL 操作。 |
| 6 | 功能按钮 |
|
| 7 | 数据库对象树 | 以树的形式展示当前 Milvus 中的所有库、表、列等对象。您可以做如下操作:
|
| 8 | 工作空间 | 占位。 |
| 9 | 编辑器窗口 | 支持如下功能:
|
| 10 | 执行信息、结果集 | 显示命令的执行信息以及结果集。
|
附件一:SQL 语法设计
DDL
| 类别 | 命令 | 语法 |
|---|---|---|
| 数据库操作 | 创建数据库 | CREATE DATABASE <库名> |
| 删除数据库 | DROP DATABASE <库名> | |
| 表操作 | 创建表 | CREATE TABLE <表名>( <主键名><数据类型> PRIMARY KEY, <列名><数据类型>(<长度>) [PROPS 属性][NOT NULL|NULL][comment '注释'], INDEX <索引名称>(<列名>) [PROPS 属性] ) |
| 修改表属性 | ALTER TABLE <表名> SET PROPS(<表属性>) | |
| 重命名表 | RENAME TABLE <表名> TO <新表名> | |
| 删除表 | DROP TABLE <表名> | |
| 加载表 | LOAD TABLE <表名> | |
| 卸载表 | RELEASE TABLE <表名> | |
| 索引操作 | 创建索引 | CREATE INDEX <索引名> ON <表名>(<列名>) PROPS(<属性>) |
| 删除索引 | DROP INDEX <索引名> ON <表名> | |
| 别名操作 | 创建别名 | CREATE ALIAS <别名> FOR <表名> |
| 删除别名 | DROP ALIAS <别名> |
示例:
--创建简单表
create table t1(
id bigint primary key, -- 主键列
vector vector(3), -- 3 维浮点向量
name varchar(32), -- 短文本字段
age int, -- 数值字段
index idx1(vector) props( -- HNSW向量索引
index_type=HNSW, -- 索引类型
M=16, -- 层间连接数
metric_type=COSINE, -- 相似度计算方式
efConstruction=128), -- 构建参数
index idx2(age)
);
--创建复杂表
create table t2 (
id bigint primary key,
c2 int64 props(is_partition_key=true) not null, -- 分区键
c3 float null comment 'abc',
c4 double comment 'c4 column comment',
c5 vector(32), -- 标准浮点向量
c6 int[45], -- 定长数组
c7 json, -- JSON文档
c8 varchar(2541) default 'abc',
c9 varchar(10)[21],
c10 float[32],
c11 binary_vector(128), -- 二进制向量
c12 sparse_float_vector(128), -- 稀疏向量
c14 int8,
c15 int16,
c16 int32,
c17 varchar(256) comment '字符串测试',
c18 vector(32),
index idx1(c3),
index idx2(c2) props(type=autoindex),
index idx3(c5) props(type=ivf_flat,nlist=10,metric_type=COSINE), -- IVF_FLAT向量索引
index idx4(c11) props(type=BIN_IVF_FLAT,nlist=10,metric_type=HAMMING), -- 二进制向量索引
index idx5(c12) props(type=SPARSE_INVERTED_Index,metric_type=IP),
index idx6(c18) props(type=HNSW,M=31,metric_type=L2,efConstruction=124),
index idx7(c8) props(type=inverted),
index idx8(c14) props(type=bitmap),
index idx9(c15) props(type=STL_SORT),
index idx10(c17) props(type=Trie)
) comment='test table' props(
enable_dynamic_field=true, -- 允许动态字段
collection.ttl.seconds=3600, -- 数据自动过期时间
ABC=234);
DML
| 类别 | 命令 | 语法示例 |
|---|---|---|
| 数据插入 | 插入单条数据 | INSERT INTO <表名> (<列名 1>,<列名 2>) VALUES (<值 1>,<值 2>) |
| 插入多条数据 | INSERT INTO <表名> (<列名 1>,<列名 2>) VALUES (<值 1>,<值 2>),(<值 3>,<值 4>) | |
| 通过 SET 插入 | INSERT INTO <表名> SET <列名 1>=<值 1>, <列名 2>=<值 2> | |
| 数据替换 | 替换数据 | REPLACE INTO <表名> (<列名 1>,<列名 2>) VALUES (<值 1>,<值 2>) |
| 数据删除 | 按条件删除 | DELETE FROM <表名> WHERE <条件语句> |
DQL
| 类别 | 命令/功能 | 语法示例 |
|---|---|---|
| 基础查询 | 查看数据库 | SHOW DATABASES |
| 查看表 | SHOW TABLES | |
| 全表查询 | SELECT * FROM <表名> | |
| 条件过滤 | SELECT * FROM <表名> WHERE <列名 1> IN (1,2,3) | |
| 分页查询 | SELECT * FROM <表名> LIMIT 10 OFFSET 20 | |
| 向量检索 | 单向量搜索 | SELECT * FROM <表名> ORDER BY vector_search(<向量列名>, [1.0,2.0,3.0]) |
| 带参数向量搜索 | SELECT * FROM <表名> ORDER BY vector_search((<向量列名>, [1.0,2.0], nlist=10, metric_type=COSINE) | |
| 结合过滤条件 | SELECT * FROM <表名> WHERE filter='id>0' ORDER BY vector_search(<向量列名>, [1.0,2.0,3.0]) | |
| 聚合与分组 | 分组检索 | SELECT * FROM <表名> GROUP BY <列名> PROPS(group_size=3) |
示例:
--普通查询
select * from table_name
select id,c1 from table_name where id=1
select * from table_name where id in (1,2)
select * from table_name where id in (1,2,3) limit 10
select * from table_name where id in (1,2,3) limit 10,20
select * from table_name where filter='id==3' limit 10
select * from table_name where filter='id in [1,2,8]' limit 10 offset 20
select * from table_name where filter='age>15 and age<81' limit 10,20
select * from table_name where filter='TEXT_MATCH(text, \'test deep\') and id>0';
select * from t123 where id in (14641243,88282101)
and filter='id>0 and name like "beyond%"'
limit 2;
--向量查询
select * from table_name
order by vector_search(column_name,{vector_value})
limit 10
select id,text from table_name
order by vector_search(column_name,{vector_value},nlist=10,param2=2)
limit 10
select id,text from table_name
where filter='id>0'
order by vector_search(column_name,{vector_value},nlist=10,radius=0.4,range_filter=0.6)
limit 10
select * from t123 where filter='id>0'
group by docId
order by vector_search(vector,[1,2,1])
props(group_size=3,strict_group_size=false)
select version()
select embedding('男士','text-embedding-v3',64)
权限控制
| 类别 | 命令 | 语法示例 |
|---|---|---|
| 角色管理 | 查看角色 | SHOW ROLES |
| 创建角色 | CREATE ROLE <角色名称> | |
| 授权角色 | GRANT <权限> ON <范围> TO <角色名称> | |
| 撤销权限 | REVOKE <权限> ON <范围> FROM <角色名称> | |
| 用户管理 | 查看用户 | SHOW USERS |
| 创建用户 | CREATE USER <用户名称> IDENTIFIED BY '<密码>' | |
| 绑定角色 | GRANT <权限>, <角色名称> TO <用户名称> |
示例:
-- 角色管理示例
create role role1; -- 创建角色 role1
grant CreateDatabase,DropDatabase on Global to role1; -- 将创建数据库、删除数据库的权限在全局范围内授权给 role1
grant Delete,Insert on Colleciton to role1; -- 将删除、插入权限在集合范围内授权给 role1
revoke Delete on Colleciton from role1; -- 撤销 role1 在集合中的删除权限
-- 用户管理示例
create user user1 identified by 'abc123'; -- 创建名为 user1 的用户,密码为 abc123
grant admin,role1 to user1; -- 将管理员角色,以及 role1 角色绑定给 user1
desc user user1; -- 显示用户 user1 拥有的所有角色
desc role role1; -- 显示角色 role1 拥有的是所有权限
附件二:函数语法表
| 函数名 | 函数作用 | 参数定义 | 使用示例 |
|---|---|---|---|
VECTOR_SEARCH | 执行向量相似度计算,用于检索时的排序 |
| SELECT * FROM <表名> ORDER BY vector_search(vector_col, [0.1,0.2,0.3], nlist=10) |
EMBED | 将文本转换为向量 |
| INSERT INTO t1 VALUES (1, 'text', embed('男士', 'text-embedding-v3', 64)) |
VERSION | 返回数据库版本信息 | 无参数 | SELECT VERSION() |


 企业微信
企业微信